







 本文深入探讨了图注意力网络(GAT)的工作原理,包括非对称注意力权重的学习、LeakyReLU的重要性,以及与Transformer的对比。GAT通过学习节点间的注意力权重,实现对图数据的加权聚合,从而在处理图数据时能更好地处理噪声节点,并提供一定的可解释性。
本文深入探讨了图注意力网络(GAT)的工作原理,包括非对称注意力权重的学习、LeakyReLU的重要性,以及与Transformer的对比。GAT通过学习节点间的注意力权重,实现对图数据的加权聚合,从而在处理图数据时能更好地处理噪声节点,并提供一定的可解释性。
参考来源:https://mp.weixin.qq.com/s/Ry8R6FmiAGSq5RBC7UqcAQ
1、介绍
图神经网络已经成为深度学习领域最炽手可热的方向之一。作为一种代表性的图卷积网络,Graph Attention Network (GAT) 引入了注意力机制来实现更好的邻居聚合。通过学习邻居的权重,GAT 可以实现对邻居的加权聚合。因此,GAT 不仅对于噪音邻居较为鲁棒,注意力机制也赋予了模型一定的可解释性。
下图概述了 Graph Attention Network 主要做的事情。
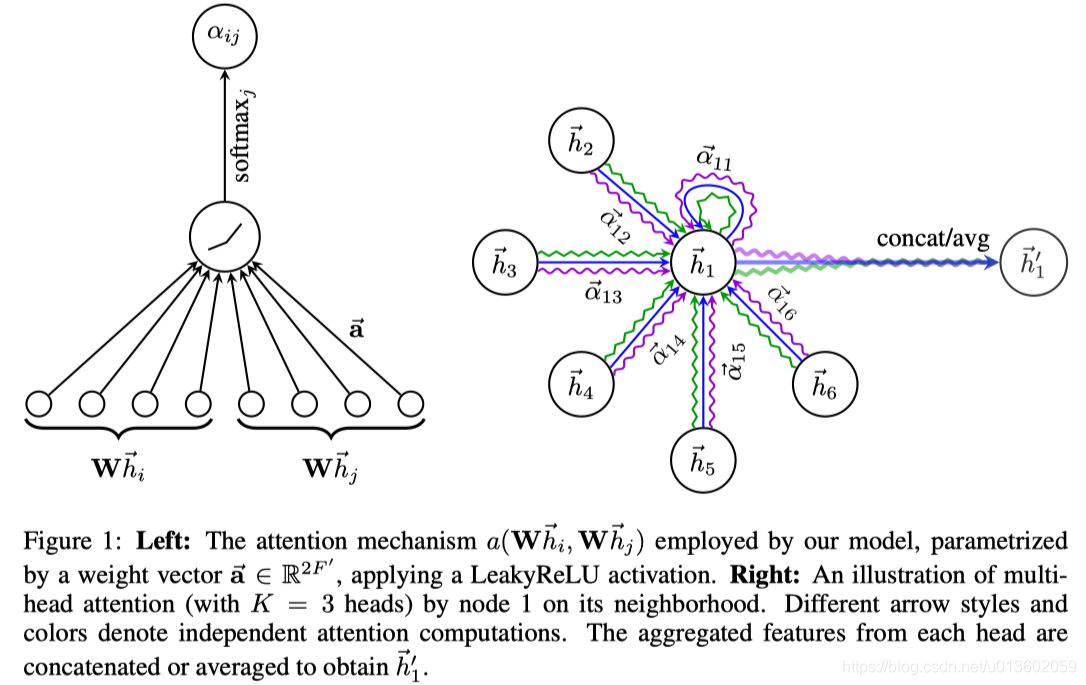
针对节点 i i i 和节点 j j j, GAT 首先学习了他们之间的注意力权重 α i j \alpha_{ij} αij(如左图所示);然后,基于注意力权重 { α 11 , ⋯ , α 16 } \{\alpha_{11},\cdots,\alpha_{16}\} {
α11,⋯,α16} 来对节点 { 1 , 2 , ⋯ , 6 } \{1,2,\cdots,6\} {
1,2,⋯,6} 的表示 { h 1 , ⋯ , h 6 } \{h_1,\cdots,h_6\} {
h1,⋯,h6} 加权平均,进而得到节点1 的表示 h 1 ′ h'_1 h1′ 。
2、深入理解图注意力机制
2.1、非对称的注意力权重
首先,介绍下如何学习节点对 ( i , j ) (i,j) (i,j) 之间的注意力值 e i j e_{ij} eij。很明显,为了计算 e i j e_{ij} eij ,注意力网络 a a a 需要同时考虑两个节点的影响,如下式: e i j = a ( W h ⃗ i , W h ⃗ j ) e_{ij}=a\left(W\vec{h}_i,W\vec{h}_j\right) eij=a(Whi,Whj)
其中, h ⃗ i , h ⃗ j \vec{h}_i,\vec{h}_j hi,hj分别是节点 i i i 和 j j j 的表示, W W W 是一个投影矩阵。
注意力网络可以有很多的设计方式,这里作者将节点 i i i 和 j j j 的表示进行了拼接,再映射为一个标量。需要注意,这里拼接导致 e i j ≠ e j i e_{ij}\neq e_{ji} eij=eji,也就是说注意力值 e i j e_{ij} eij 是非对称的。 e i j = L e a k y R e L U ( a ⃗ T [ W h ⃗ i ∣ ∣ W h ⃗ j ] ) e_{ij}=LeakyReLU\left(\vec{a}^T\left[W\vec{h}_i||W\vec{h}_j\right]\right) eij=LeakyReLU(aT[Whi∣∣Whj])
除了拼接操作以外,聚合邻居信息时,需要对每个节点的所有邻居的注意力进行归一化。归一化之后的注意力权重 α i j \alpha_{ij} αij 才是真正的聚合系数。 α i j = s o f t m a x ( e i j ) = e x p ( e i j ) ∑ k ∈ N i e x p ( e i k ) \alpha_{ij}=softmax(e_{ij})=\frac{exp(e_{ij})}{\sum_{k\in\mathcal{N}_i}exp(e_{ik})} αij=softmax(eij)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









