







 本文介绍TransR和CTransR模型,用于改善知识图谱中的实体和关系表示,通过分离实体空间和关系空间,提升链接预测、三元组分类和关系抽取任务的表现。
本文介绍TransR和CTransR模型,用于改善知识图谱中的实体和关系表示,通过分离实体空间和关系空间,提升链接预测、三元组分类和关系抽取任务的表现。

论文链接:http://nlp.csai.tsinghua.edu.cn/~lyk/publications/aaai2015_transr.pdf
代码链接:https://github.com/mrlyk423/relation_extraction
参考文档:https://blog.csdn.net/qq_36426650/article/details/103357256
论文来源:2015 AAAI
导读
TransH在TransE基础上做出的改进,提高了知识表示的效果,在一定程度上解决了复杂关系的处理,同时在链接预测、三元组分类和关系抽取任务上相比传统的方法(距离模型、非结构模型、单层神经网络、双线性模型等)达到最优,然而TransH也存在一定的问题。TransR作者发现TransH模型虽然有效的处理了复杂语义关系表示,但两个实体仍然处于相同的语义空间,因此不能够充分表示实体与关系的语义联系。
1、引言
知识图谱的完成可以实现目标实体之间的链接预测。本文我们研究了知识图谱表征的方法。最近TransE和TransH模型通过将关系视为一种从头实体到尾实体的翻译机制来获得实体和关系的表征。事实上一个实体可能有多个不同方面(特征),关系可能关注实体不同方面的特征,公共的实体特征空间不足以表征。本文,我们提出TransR模型构建实体和关系表征,将实体空间和关系空间相分离。然后我们以这种方式训练表征向量:首先通过将实体映射到关系空间中,其次在两个投影实体之间构建翻译关系。实验中,我们在三个任务上完成了验证,分别是链接预测、三元组分类和关系抽取。实验效果表明相比之前的基线模型,包括TransE和TransR,得到了一定的提升。
完善的知识图谱旨在预测给定两个实体对的关系,即链接预测,期现如今面临的挑战包括(1)图谱中的结点包含不同类型和属性的实体、(2)边表示不同类型的关系。对于知识补全,我们不仅仅只是判断实体对是否存在关系,也需要预测具体的关系类。基于此,传统的链接预测方法则无法实现链接预测。最近一种新提出的表示学习是指将实体和关系嵌入到连续的向量空间中。
TransE和TransH模型是基于这种表示学习。TransE在word2vec的启发之下,通过构建简单的语义表示
h
+
r
≈
t
h+r\approx t
h+r≈t实现训练,TransH则基于TransE基础上能够对复杂关系进行表示。不过这两个模型均是假定实体和关系是在同一个语义空间中。作者提出一种新的策略,将实体和关系分别映射到不同的语义空间中,分别为entity space(实体空间)和relation space(关系空间)。
TransR的主要思路如图所示:
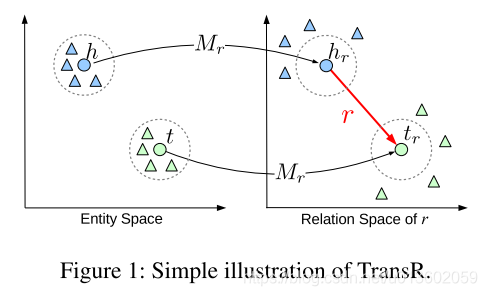
假设实体对
(
h
,
r
,
t
)
(h,r,t)
(h,r,t) ,首先根据当前的关系
r
r
r 将头尾实体分别映射到关系空间中
h
r
,
t
r
h_r,t_r
hr,tr,然后在关系空间中建模
h
r
+
r
≈
t
r
h_r+r\approx t_r
hr+r≈tr。
另外,在特定的关系下,实体对通常表现出不同的模式,因此不能单纯的将关系直接与实体对进行操作。我们通过将不同的头尾实体对聚类成组,并为每个组学习不同的关系向量来扩展TransR,称为基于聚类的TransR (CTransR)。
2、TransR模型详解
TransR模型:设实体对 ( h , r , t ) (h,r,t) (h,r,t)的表征分别为 h , t ∈ R k \mathbf{h},\mathbf{t}\in\mathbb{R}^k h,t∈Rk, r ∈ R d \mathbf{r}\in\mathbb{R}^d r∈Rd,其中 k ≠ d k\ne d k=d。对于每个关系 r r r 给定映射矩阵 M ∈ R k × d \mathbf{M}\in\mathbb{R}^{k\times d} M∈Rk×d,则有: h r = h M r \mathbf{h}_r=\mathbf{h}\mathbf{M}_r hr=hMr, t r = t M r \mathbf{t}_r=\mathbf{t}\mathbf{M}_r tr=tMr。得分函数定义为 f r ( h , t ) = ∣ ∣ h r + r − t r ∣ ∣ 2 2 f_r(h,t)=||\mathbf{h}_r+\mathbf{r}-\mathbf{t}_r||_2^2 fr(h,t)=∣∣hr+r−tr∣∣22。约束条件为 ∣ ∣ h ∣ ∣ 2 ≤ 1 ||\mathbf{h}||_2\leq1 ∣∣h∣∣2≤1, ∣ ∣ r ∣ ∣ 2 ≤ 1 ||\mathbf{r}||_2\leq1 ∣∣r∣∣2≤1, ∣ ∣ t ∣ ∣ 2 ≤ 1 ||\mathbf{t}||_2\leq1 ∣∣t∣∣2≤1, ∣ ∣ h M r ∣ ∣ 2 ≤ 1 ||\mathbf{h}\mathbf{M}_r||_2\leq1 ∣∣hMr∣∣2≤1, ∣ ∣ t M r ∣ ∣ 2 ≤ 1 ||\mathbf{t}\mathbf{M}_r||_2\leq1 ∣∣tMr∣∣2≤1。
CTransR模型:受到piecewise linear regression(分段线性回归)的启发。
- (1)首先将输入示例分为多个组。对于特定的关系 r r r ,所有的实体对 ( h , t ) (h,t) (h,t) 可被聚类到多个簇中,每个簇中的实体对可被认为与关系 r r r 有关。
- (2)为每个簇对应的关系向量 r c \mathbf{r}_c rc表征,并得到对应的 M r \mathbf{M}_r Mr ,然后将每个簇中的头实体和尾实体映射到对应关系空间中 h r , c = h M r \mathbf{h}_{r,c}=\mathbf{h}\mathbf{M}_r hr,c=hMr, t r , c = t M r \mathbf{t}_{r,c}=\mathbf{t}\mathbf{M}_r tr,c=tMr。得分函数定义为 f r ( h , t ) = ∣ ∣ h r , c + r c − t r , c ∣ ∣ 2 2 + α ∣ ∣ r c − r ∣ ∣ 2 2 f_r(h,t)=||\mathbf{h}_{r,c}+\mathbf{r}_c-\mathbf{t}_{r,c}||_2^2+\alpha ||\mathbf{r}_c-\mathbf{r}||_2^2 fr(h,t)=∣∣hr,c+rc−tr,c∣∣22+α∣∣rc−r∣∣22
TransR和CTransR的区别在于两者的关系空间不同,前者只有一个关系空间,亦即对所有的关系都在同一个空间中;后者则是根据不同的关系,对属于同一个关系的所有实体对聚集在一个簇中,每个关系代表不同的空间。
损失函数:损失函数与之前的一样:
L
=
∑
(
h
,
r
,
t
)
∈
S
∑
(
h
′
,
r
,
t
′
)
∈
S
′
[
γ
+
f
r
(
h
,
t
)
−
f
r
(
h
′
,
t
′
)
]
+
L=\sum_{(h,r,t)\in S}\sum_{(h',r,t')\in S'}[\gamma + f_r(h,t)-f_r(h',t')]_+
L=(h,r,t)∈S∑(h′,r,t′)∈S′∑[γ+fr(h,t)−fr(h′,t′)]+作者指出训练策略与负样本构建则与TransH一样,因此在此不做详细讲解。
3、实验
实验主要包括三个任务,实验的具体细节与TransH相同 ,不做详细介绍。
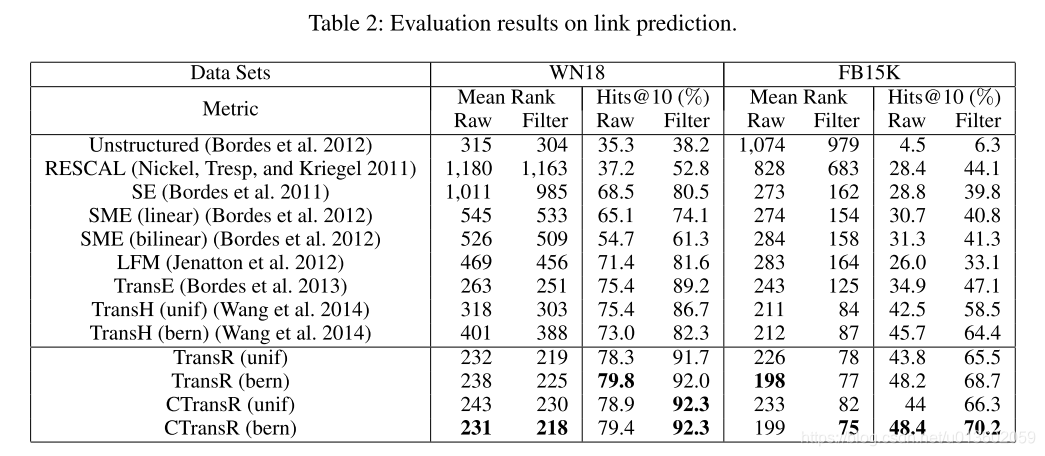
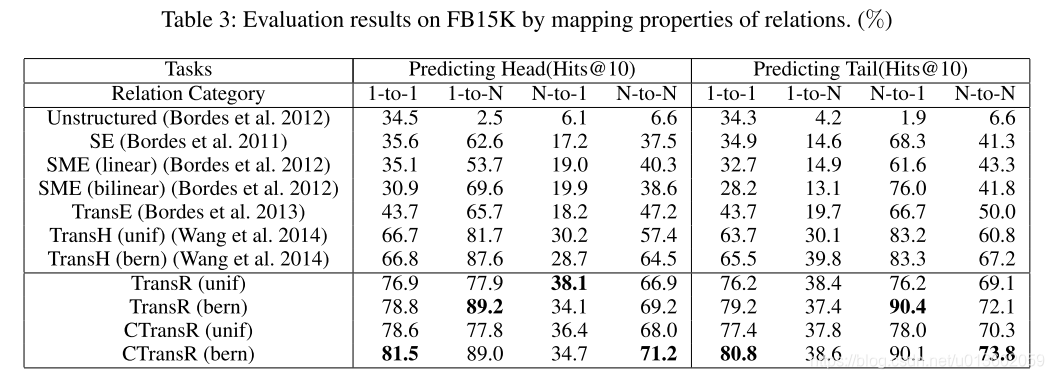
3.1、链接预测
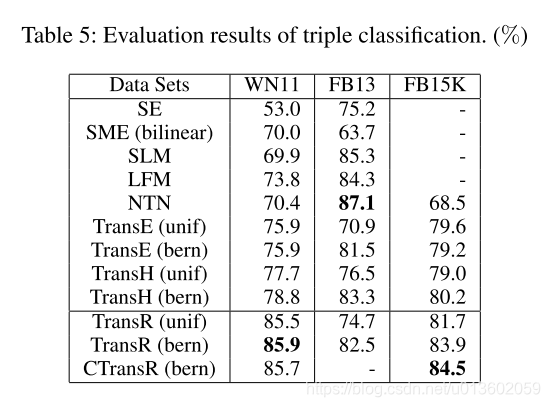
3.2、三元组分类
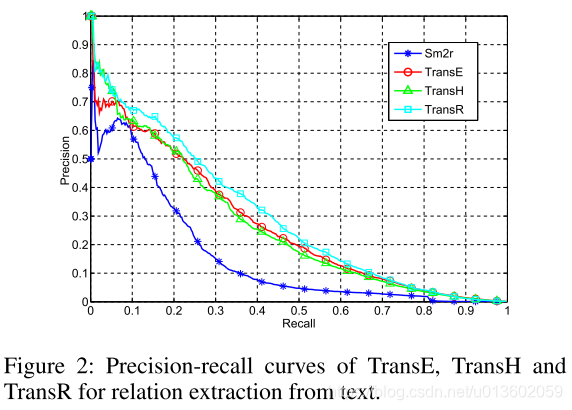
3.3、关系抽取
4、总结
本文作者提出的TransR和CTransR模型可以将相同关系的三元组映射到对应关系的空间中,有效的对三元组进行语义表示,在包括链接预测、三元组分类和关系抽取任务上均实现最好效果。作者提出三个未来工作,包括:
- (1)利用推理信息增强图谱的表征;
- (2)探究文本与图谱的表示模型;
- (3)基于CTransR,研究更复杂的模型。
TransR模型巧妙的借鉴了TransH模型的空间投影想法,更细致的将不同的关系作为不同的投影空间,试想一下,每个三元组中的两个实体之所以在同一个三元组,很大程度上是因为两个实体的某些特性符合当前的关系,而这些特性在这个关系所在的语义空间中满足一定的规律,亦即 h r + r ≈ t r h_r+r\approx t_r hr+r≈tr。
TransR还有一些缺点。例如引入的空间投影策略增加了计算量、头尾实体一同投影到关系空间,而未考虑到头尾实体的不同语义类型、仅将实体投影到关系空间中还不够完全提高语义表能力等。TransD模型试图改进这些不足之处。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









