







import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
hidden_layer_size = [256]*4
input_layer_size = 784
output_layer_size = 10
mnist = input_data.read_data_sets('data/', one_hot=True)
train_img = mnist.train.images
train_lbl = mnist.train.labels
test_img = mnist.test.images
test_lbl = mnist.test.labels
def initial_weights(ils, hls, ols):
weights,bias = {}, {}
stddev = 0.1
for i in xrange(len(hls)+1):
fan_in = ils if i==0 else hls[i-1]
fan_out = ols if i==len(hls) else hls[i]
print fan_in, fan_out
weights[i] = tf.Variable(tf.random_normal([fan_in, fan_out], stddev=stddev))
bias[i] = tf.Variable(tf.random_normal([fan_out]))
return weights, bias
def mlp(_x, _w, _b, _keep_prob):
layers = {}
for i in xrange(len(_w)):
if i == 0:
layers[i] = tf.nn.dropout(tf.nn.relu(tf.add(tf.matmul(_x, _w[i]), _b[i])), _keep_prob)
elif i < len(_w)-1:
layers[i] = tf.nn.dropout(tf.nn.relu(tf.add(tf.matmul(layers[i-1], _w[i]), _b[i])), _keep_prob)
else:
layers[i] = tf.add(tf.matmul(layers[i-1], _w[i]), _b[i])
return layers[len(_w) - 1]
weights, bias = initial_weights(input_layer_size, hidden_layer_size, output_layer_size)
x = tf.placeholder(tf.float32, [None, input_layer_size], name='input')
y = tf.placeholder(tf.float32, [None, output_layer_size], name='output')
dropout_keep_prob = tf.placeholder(tf.float32)
score = mlp(x, weights, bias, dropout_keep_prob)
prob = tf.nn.softmax(score)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(score, y))
lr = 0.001
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
# optimizer = tf.train.GradientDescentOptimizer(lr).minimize(loss)
pred = tf.equal(tf.argmax(prob, 1), tf.argmax(y,1))
acc = tf.reduce_mean(tf.cast(pred, tf.float32))
init = tf.initialize_all_variables()
epoch = 100
batch_size = 200
snapshot = 5
sess = tf.Session()
with tf.Session() as sess:
sess.run(init)
loss_cache = []
acc_cache = []
for ep in xrange(epoch):
num_batch = mnist.train.num_examples/batch_size
avg_loss, avg_acc = 0, 0
for nb in xrange(num_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
out = sess.run([optimizer, acc, loss], feed_dict={x:batch_x, y:batch_y, dropout_keep_prob:0.7})
avg_loss += out[2]/num_batch
avg_acc += out[1]/num_batch
loss_cache.append(avg_loss)
acc_cache.append(avg_acc)
if ep % snapshot ==0:
print 'Epoch: %d, loss: %.4f, acc: %.4f'%(ep, avg_loss, acc_cache[-1])
print 'test accuracy:' , acc.eval({x:test_img, y:test_lbl, dropout_keep_prob:1.0})
plt.figure(1)
plt.plot(range(len(loss_cache)), loss_cache, 'b-', label='loss')
plt.legend(loc = 'upper right')
plt.figure(2)
plt.plot(range(len(acc_cache)), acc_cache, 'o-', label='acc')
plt.legend(loc = 'lower right')
plt.show()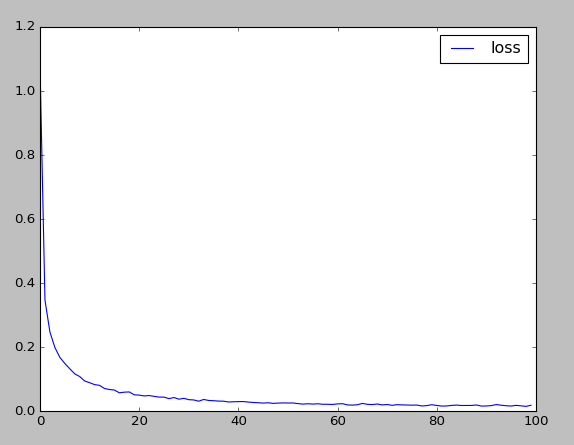
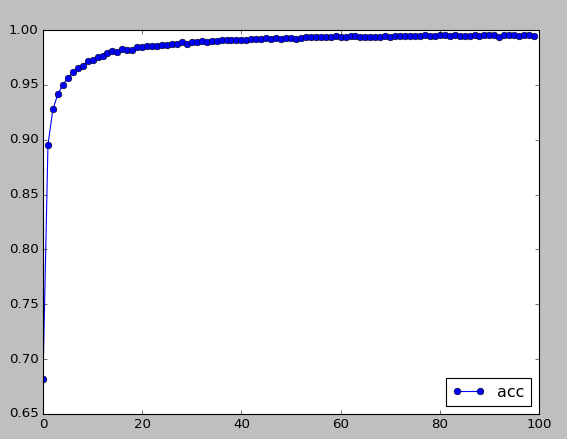
# Epoch: 0, loss: 1.0799, acc: 0.6821
# Epoch: 5, loss: 0.1487, acc: 0.9563
# Epoch: 10, loss: 0.0885, acc: 0.9731
# Epoch: 15, loss: 0.0655, acc: 0.9799
# Epoch: 20, loss: 0.0497, acc: 0.9841
# Epoch: 25, loss: 0.0434, acc: 0.9868
# Epoch: 30, loss: 0.0354, acc: 0.9887
# Epoch: 35, loss: 0.0322, acc: 0.9902
# Epoch: 40, loss: 0.0292, acc: 0.9909
# Epoch: 45, loss: 0.0247, acc: 0.9927
# Epoch: 50, loss: 0.0250, acc: 0.9924
# Epoch: 55, loss: 0.0216, acc: 0.9935
# Epoch: 60, loss: 0.0222, acc: 0.9937
# Epoch: 65, loss: 0.0237, acc: 0.9933
# Epoch: 70, loss: 0.0202, acc: 0.9936
# Epoch: 75, loss: 0.0182, acc: 0.9946
# Epoch: 80, loss: 0.0174, acc: 0.9954
# Epoch: 85, loss: 0.0172, acc: 0.9946
# Epoch: 90, loss: 0.0157, acc: 0.9954
# Epoch: 95, loss: 0.0155, acc: 0.9951
# test accuracy: 0.9819













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









