







 本文介绍了如何使用Python实现kNN(k最近邻)分类算法。首先讲解了如何安装Python环境,然后通过二维点分类的实例解释了kNN算法的伪代码和欧几里得距离计算。接着,文章展示了约会网站数据分类的例子,包括数据解析、归一化、散点图绘制和分类器的测试。最后,文章探讨了一个手写数字识别系统,详细阐述了数据预处理和分类过程,指出虽然准确率高,但算法在时间和空间复杂度上的挑战。
本文介绍了如何使用Python实现kNN(k最近邻)分类算法。首先讲解了如何安装Python环境,然后通过二维点分类的实例解释了kNN算法的伪代码和欧几里得距离计算。接着,文章展示了约会网站数据分类的例子,包括数据解析、归一化、散点图绘制和分类器的测试。最后,文章探讨了一个手写数字识别系统,详细阐述了数据预处理和分类过程,指出虽然准确率高,但算法在时间和空间复杂度上的挑战。
安装python
Matplotlib依赖于Python和NumPy,所以在unbuntu上安装python的快捷方法就是直接安装Matplotlib
>sudo apt-get install python-matplotlibkNN算法伪代码
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排序;
3.选取与当前距离最小的k个点;
4.确定前k个点所在类别的出现频率;
5.返回前k个点中出现频率最高的类别作为当前点的预测分类;优点:简单有效
缺点:空间时间复杂度高,无法知晓平均实例样本和典型实例样本的特征
实例一 二维点分类
给出4个二维数据点及其对应分类,用k-mean算法,对新输入的点进行分类
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
#calculate the distance
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
#select k nearby points
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#sort
sortedClassCount = sorted(classCount.iteritems(),
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0] 运行程序
>>> import kNN
>>> group,labels = kNN.createDataSet()
>>> group
array([[ 1. , 1.1],
[ 1. , 1. ],
[ 0. , 0. ],
[ 0. , 0.1]])
>>> labels
['A', 'A', 'B', 'B']
实例二 约会网站数据分类
从文本文件中解析数据
数据说明
| 第一列 | 第二列 | 第三列 | 第四列 |
|---|---|---|---|
| 飞行里程 | 玩游戏时间百分比 | 消费冰淇淋公升数 | 喜好程度 |
数据内容
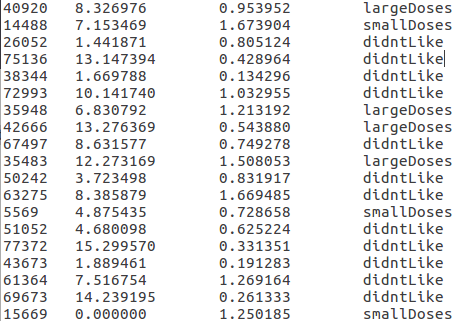
处理一下初始数据,将标称数据转换成数字
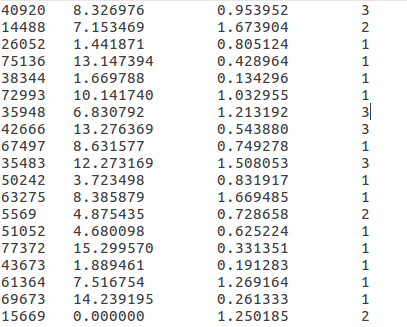
#transfer text to matrix
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector程序运行
>>> reload(kNN)
<module &# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1890
1890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









