







 本文深入探讨了延迟渲染技术,包括前向渲染与延迟渲染的区别、延迟渲染的工作原理及其优势与局限性。介绍了G-Buffer的使用,如何结合前向渲染与延迟渲染,并详细解释了光体积的概念及其实现方法。
本文深入探讨了延迟渲染技术,包括前向渲染与延迟渲染的区别、延迟渲染的工作原理及其优势与局限性。介绍了G-Buffer的使用,如何结合前向渲染与延迟渲染,并详细解释了光体积的概念及其实现方法。
到目前为止,我们进行照明的方式称为forward rendering前向渲染或forward shading前向着色。我们渲染对象,根据场景中的所有光源对其进行照明。我们为场景中的每个对象分别为每个对象执行此操作。虽然很容易理解和实现,但它对性能的影响也很大,因为每个渲染对象都必须为每个渲染片段迭代每个光源,这很多!由于片段着色器输出被覆盖,forward rendering前向渲染也往往会浪费大量在深度复杂度高的场景(多个对象覆盖同一屏幕像素)中运行的片段着色器。
Deferred Shading延迟着色或deferred rendering延迟渲染旨在通过彻底改变我们渲染对象的方式来克服这些问题。这为我们提供了几个新选项来显着优化具有大量灯光的场景,使我们能够以可接受的帧速率渲染数百(甚至数千)个灯光。下图是使用延迟着色渲染的 1847 个点光源的场景(图片由 Hannes Nevalainen 提供);forward rendering前向渲染无法做到的事情。

Deferred Shading延迟着色基于我们将大部分重渲染(如照明)推迟或推迟到稍后阶段的想法。 Deferred Shading延迟着色由两个PASS通道组成:在第一个PASS通道中,称为geometry pass几何通道,我们渲染场景一次并从我们存储在称为 G-buffer G 缓冲区的纹理集合中的对象中检索各种几何信息; 考虑位置向量、颜色向量、法线向量和/或镜面反射值。 存储在 G 缓冲区中的场景的几何信息随后用于(更复杂的)照明计算。 下面是一个单帧的 G-buffer 的内容:
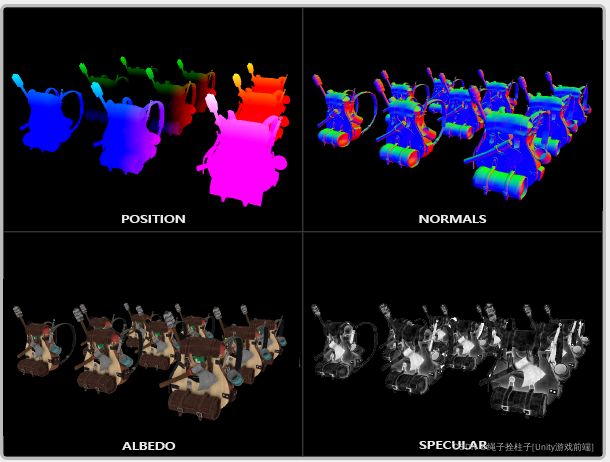
position:位置 normals法线 albedo反照率 specular镜面反射
(我去,一个单帧G-buffer,就存了4个图片)
我们在称为lighting pass光照通道的第二个PASS通道中使用来自 G 缓冲区的纹理,在此我们渲染一个充满屏幕的四边形,并使用存储在 G 缓冲区中的几何信息计算每个片段的场景光照; 我们逐个像素地遍历 G 缓冲区。 我们没有将每个对象从顶点着色器一直带到片段着色器,而是将其 advanced fragment processes高级片段处理decouple解耦到后面的阶段。 光照计算完全相同,但这次我们从相应的 G-buffer 纹理中获取所有需要的输入变量,而不是顶点着色器(加上一些统一变量)。
下图很好地说明了延迟着色的过程。MRT:multiple render targets(多个渲染目标)
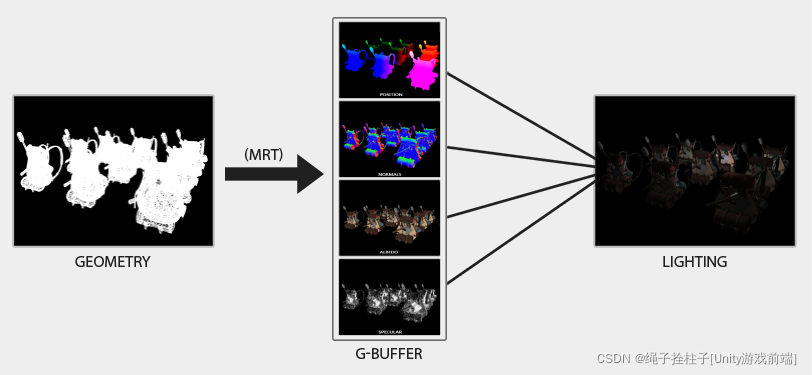
这种方法的一个主要优点是,任何最终进入 G 缓冲区的片段都是最终作为屏幕像素的实际片段信息。深度测试已经得出结论,这个片段是最后一个也是最顶层的片段。这确保了对于我们在光照通道中处理的每个像素,我们只计算一次光照。此外,延迟渲染为进一步优化提供了可能性,与forward rendering前向渲染相比,我们可以渲染更多的光源。
它也有一些缺点,因为 G 缓冲区需要我们在其纹理颜色缓冲区中存储相对大量的场景数据。这会占用内存,特别是因为像位置向量这样的场景数据需要高精度。另一个缺点是它不支持blending混合(因为我们只有最顶层片段的信息)并且 MSAA 不再有效。我们将在本章末尾介绍几种解决方法。
填充 G 缓冲区(在几何过程中)并不太昂贵,因为我们直接将对象信息(如位置、颜色或法线)存储到帧缓冲区中,处理量很小或为零。通过使用multiple render targets多个渲染目标 (MRT),我们甚至可以在一次渲染过程中完成所有这些工作。
1. The G-buffer (geometry buffer)
G-buffer 是用于存储最终光照通道的光照相关数据的所有纹理的总称。 让我们借此机会简要回顾一下使用forward rendering前向渲染点亮片段所需的所有数据:
- A 3D world-space position vector to calculate the (interpolated) fragment position variable used for lightDir and viewDir.(计算转换空间后的fragment pos)
- An RGB diffuse color vector also known as albedo. (漫反射)
- A 3D normal vector for determining a surface's slope. (法线)
- A specular intensity float.(镜面反射)
- All light source position and color vectors. (遍历所有光源和颜色)
- The player or viewer's position vector. (转换观察者视角)
如果我们能够以某种方式将完全相同的数据传递给最终的deferred lighting pass 延迟光照通道,我们就可以计算出相同的光照效果,即使我们正在渲染 2D 四边形的片段。
OpenGL 对我们可以在纹理中存储的内容没有限制,因此将所有每个片段的数据存储在 G 缓冲区的一个或多个屏幕填充纹理中并稍后在光照通道中使用它们是有意义的。 由于 G-buffer 纹理将具有与光照通道的 2D 四边形相同的大小,我们得到与forward rendering前向渲染设置完全相同的片段数据,但这次是在lighting pass光照通道中; 有一对一的映射。
在伪代码中,整个过程看起来有点像这样:
while(...) // render loop
{
// 1. geometry pass: render all geometric/color data to g-buffer
glBindFramebuffer(GL_FRAMEBUFFER, gBuffer);
glClearColor(0.0, 0.0, 0.0, 1.0); // keep it black so it doesn't leak into g-buffer
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
gBufferShader.use();
for(Object obj : Objects)
{
ConfigureShaderTransformsAndUniforms();
obj.Draw();
}
// 2. lighting pass: use g-buffer to calculate the scene's lighting
glBindFramebuffer(GL_FRAMEBUFFER, 0);
lightingPassShader.use();
BindAllGBufferTextures();
SetLightingUniforms();
RenderQuad();
}我们需要存储每个片段的数据是: position vector位置向量、normal vector法线向量、color vector颜色向量和specular intensity value镜面反射强度值。在几何通道中,我们需要渲染场景的所有对象并将这些数据组件存储在 G 缓冲区中。我们可以再次使用 multiple render targets 多渲染目标在单个渲染过程中渲染到多个颜色缓冲区;
对于几何传递,我们需要初始化一个我们称之为 gBuffer 的帧缓冲区对象,该对象附加了多个颜色缓冲区和一个深度渲染缓冲区对象。对于位置和法线纹理,我们最好使用high-precision texture高精度纹理(每个组件 16 或 32 位浮点数)。对于 albedo反照率和specular values镜面反射值,我们可以使用默认纹理精度(每个组件 8 位精度)。请注意,我们使用 GL_RGBA16F 而不是 GL_RGB16F,因为由于字节对齐,GPU 通常更喜欢 4 分量格式而不是 3 分量格式;否则,某些驱动程序可能无法完成帧缓冲区。
unsigned int gBuffer;
glGenFramebuffers(1, &gBuffer);
glBindFramebuffer(GL_FRAMEBUFFER, gBuffer);
unsigned int gPosition, gNormal, gColorSpec;
// - position color buffer
glGenTextures(1, &gPosition);
glBindTexture(GL_TEXTURE_2D, gPosition);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA16F, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGBA, GL_FLOAT, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, gPosition, 0);
// - normal color buffer
glGenTextures(1, &gNormal);
glBindTexture(GL_TEXTURE_2D, gNormal);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA16F, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGBA, GL_FLOAT, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT1, GL_TEXTURE_2D, gNormal, 0);
// - color + specular color buffer
glGenTextures(1, &gAlbedoSpec);
glBindTexture(GL_TEXTURE_2D, gAlbedoSpec);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGBA, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT2, GL_TEXTURE_2D, gAlbedoSpec, 0);
// - tell OpenGL which color attachments we'll use (of this framebuffer) for rendering
unsigned int attachments[3] = { GL_COLOR_ATTACHMENT0, GL_COLOR_ATTACHMENT1, GL_COLOR_ATTACHMENT2 };
glDrawBuffers(3, attachments);
// then also add render buffer object as depth buffer and check for completeness.
[...]由于我们使用多个渲染目标,我们必须明确告诉 OpenGL 我们希望使用 glDrawBuffers 渲染与 GBuffer 关联的哪个颜色缓冲区。 这里还值得注意的是,我们将颜色和镜面强度数据组合在单个 RGBA 纹理中; 这使我们不必声明额外的颜色缓冲纹理。 随着您的延迟着色管道变得越来越复杂并且需要更多数据,您将很快找到新方法来组合单个纹理中的数据。
接下来我们需要渲染到 G-buffer 中。 假设每个对象都有一个diffuse漫反射纹理、normal法线纹理和texture 镜面反射纹理,我们将使用类似于以下片段着色器的东西来渲染到 G 缓冲区中:
#version 330 core
layout (location = 0) out vec3 gPosition;
layout (location = 1) out vec3 gNormal;
layout (location = 2) out vec4 gAlbedoSpec;
in vec2 TexCoords;
in vec3 FragPos;
in vec3 Normal;
uniform sampler2D texture_diffuse1;
uniform sampler2D texture_specular1;
void main()
{
// store the fragment position vector in the first gbuffer texture
gPosition = FragPos;
// also store the per-fragment normals into the gbuffer
gNormal = normalize(Normal);
// and the diffuse per-fragment color
gAlbedoSpec.rgb = texture(texture_diffuse1, TexCoords).rgb;
// store specular intensity in gAlbedoSpec's alpha component
gAlbedoSpec.a = texture(texture_specular1, TexCoords).r;
} 当我们使用多个渲染目标时,layout specifier布局说明符告诉 OpenGL 我们渲染到活动帧缓冲区的哪个颜色缓冲区。 请注意,我们不会将镜面反射强度存储到单独一个颜色缓冲区纹理中,因为我们可以将其单个浮点值存储在其他颜色缓冲区纹理之一的 alpha 分量中。
请记住,对于照明计算,将所有相关变量保持在同一坐标空间中非常重要。 在这种情况下,我们将所有变量存储(并计算)在世界空间中。
如果我们现在将大量背包对象渲染到 gBuffer 帧缓冲区中,并通过将每个颜色缓冲区一个接一个地投影到屏幕填充的四边形上来可视化其内容,我们会看到如下所示:
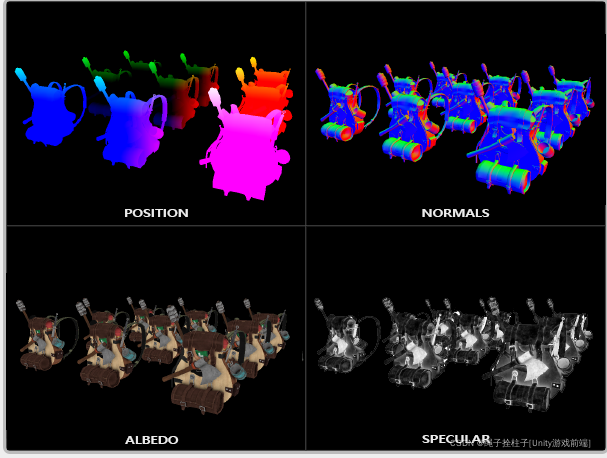
试着想象世界空间位置和法线向量确实是正确的。 例如,指向右侧的法线向量将更符合红色,类似于从场景原点指向右侧的位置向量。 只要您对 G 缓冲区的内容感到正常,就可以进行下一步:光照通道。
2.The deferred lighting pass (延迟照明通道)
借助 G-Buffer 中可供我们使用的大量片段数据,我们可以选择完全计算场景的最终光照颜色。 我们通过逐个像素地迭代每个 G-Buffer 纹理并将它们的内容用作光照算法的输入来做到这一点。 因为 G-buffer 纹理值都代表最终转换后的片段值,所以我们只需要对每个像素进行一次昂贵的光照操作。 这在复杂场景中特别有用,在这些场景中,我们很容易在前向渲染设置中为每个像素调用多个昂贵的片段着色器调用。
对于光照通道,我们将渲染一个 2D 屏幕填充四边形(有点像后处理效果)并在每个像素上执行一个 昂贵的lighting fragment shader光照片段着色器:
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, gPosition);
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, gNormal);
glActiveTexture(GL_TEXTURE2);
glBindTexture(GL_TEXTURE_2D, gAlbedoSpec);
// also send light relevant uniforms
shaderLightingPass.use();
SendAllLightUniformsToShader(shaderLightingPass);
shaderLightingPass.setVec3("viewPos", camera.Position);
RenderQuad(); 我们在渲染之前绑定 G 缓冲区的所有相关纹理,并将与光照相关的统一变量发送到着色器。
lighting pass光照通道的片段着色器与我们目前使用的光照章节着色器非常相似。 新的是我们获取光照输入变量的方法,我们现在直接从 G-buffer 中采样:
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D gPosition;
uniform sampler2D gNormal;
uniform sampler2D gAlbedoSpec;
struct Light {
vec3 Position;
vec3 Color;
};
const int NR_LIGHTS = 32;
uniform Light lights[NR_LIGHTS];
uniform vec3 viewPos;
void main()
{
// retrieve data from G-buffer
// 从G-buffer中获取数据 gPosition和gNormal和gAlbedoSpec都是uniform
vec3 FragPos = texture(gPosition, TexCoords).rgb;
vec3 Normal = texture(gNormal, TexCoords).rgb;
vec3 Albedo = texture(gAlbedoSpec, TexCoords).rgb;
float Specular = texture(gAlbedoSpec, TexCoords).a;
// then calculate lighting as usual
vec3 lighting = Albedo * 0.1; // hard-coded ambient component
vec3 viewDir = normalize(viewPos - FragPos);
for(int i = 0; i < NR_LIGHTS; ++i)
{
// diffuse
vec3 lightDir = normalize(lights[i].Position - FragPos);
vec3 diffuse = max(dot(Normal, lightDir), 0.0) * Albedo * lights[i].Color;
lighting += diffuse;
}
FragColor = vec4(lighting, 1.0);
} 光照通道着色器接受 3 个统一纹理,它们代表 G -buffer并保存我们存储在几何通道中的所有数据。 如果我们使用当前片段的纹理坐标对这些进行采样,我们将获得完全相同的片段值,就像我们直接渲染几何体一样。 请注意,我们从单独的 gAlbedoSpec 纹理中检索了 Albedo 颜色和 Specular 强度。
由于我们现在拥有计算 Blinn-Phong 光照所需的每个片段变量(以及相关的统一变量),因此我们不必对光照代码进行任何更改。 我们在延迟着色中唯一改变的是获取光照输入变量的方法。
运行一个总共有 32 个小灯的简单演示看起来有点像这样:
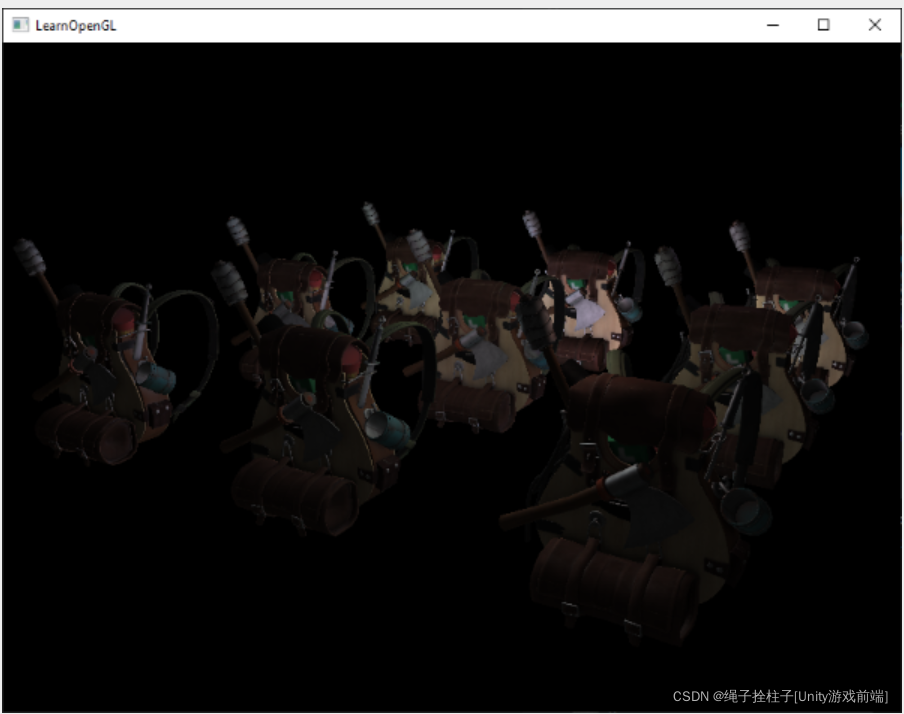
延迟着色的缺点之一是无法进行混合,因为 G 缓冲区中的所有值都来自单个片段,并且混合对多个片段的组合进行操作。 另一个缺点是延迟着色迫使您对场景的大部分照明使用相同的照明算法。 您可以通过在 G 缓冲区中包含更多特定于材质的数据来以某种方式缓解这一点。
为了克服这些缺点(尤其是混合),我们经常将渲染器分成两部分:一个是forward rendring延迟渲染部分,另一个是前向渲染部分,专门用于混合或不适合延迟渲染管道的特殊着色器效果。 为了说明这是如何工作的,我们将使用forward rendring前向渲染器将光源渲染为小立方体,因为光立方体需要特殊的着色器(只需输出单一的光色)。
3.Combining deferred rendering with forward rendering(将延迟渲染与前向渲染相结合)
先向通常那样渲染光照立方体,但只有在我们完成了延迟渲染操作之后。 在代码中,这看起来有点像这样:
// deferred lighting pass
[...]
RenderQuad();
// 延迟渲染之后,再进行常规渲染
// now render all light cubes with forward rendering as we'd normally do
shaderLightBox.use();
shaderLightBox.setMat4("projection", projection);
shaderLightBox.setMat4("view", view);
for (unsigned int i = 0; i < lightPositions.size(); i++)
{
model = glm::mat4(1.0f);
model = glm::translate(model, lightPositions[i]);
model = glm::scale(model, glm::vec3(0.25f));
shaderLightBox.setMat4("model", model);
shaderLightBox.setVec3("lightColor", lightColors[i]);
RenderCube();
}然而,这些渲染的立方体没有考虑到任何存储的延迟渲染器的几何深度,因此总是渲染在先前渲染的对象之上; 这不是我们想要的结果。
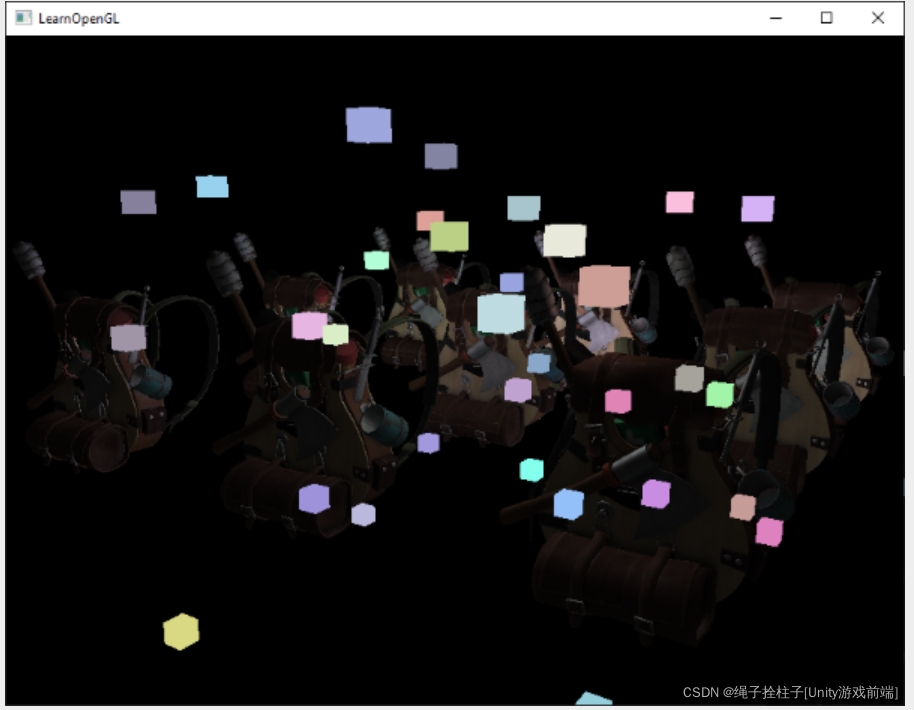
我们需要做的是,首先将存储在几何传递中的深度信息复制到默认帧缓冲区的深度缓冲区中,然后再渲染光立方。这样,光立方体的片段仅在之前渲染的几何体之上时才会被渲染。
我们可以在 glBlitFramebuffer 的帮助下将一个帧缓冲区的内容复制到另一个帧缓冲区的内容中,我们也在抗锯齿章节中使用了这个函数来解析多采样帧缓冲区。 glBlitFramebuffer 函数允许我们将帧缓冲区的用户定义区域复制到另一个帧缓冲区的用户定义区域。
我们将延迟几何通道中渲染的所有对象的深度存储在 gBuffer FBO 中。如果我们将其深度缓冲区的内容复制到默认帧缓冲区的深度缓冲区中,那么光立方体就好像所有场景的几何体都是使用forward rendering前向渲染渲染的。正如抗锯齿章节中简要说明的那样,我们必须指定一个帧缓冲区作为读取帧缓冲区,并类似地指定一个帧缓冲区作为写入帧缓冲区:
glBindFramebuffer(GL_READ_FRAMEBUFFER, gBuffer);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0); // write to default framebuffer
// 复制framebuffer到默认framebuffer中
glBlitFramebuffer(
0, 0, SCR_WIDTH, SCR_HEIGHT, 0, 0, SCR_WIDTH, SCR_HEIGHT, GL_DEPTH_BUFFER_BIT, GL_NEAREST
);
glBindFramebuffer(GL_FRAMEBUFFER, 0);
// now render light cubes as before
[...] 这里我们将整个读取的framebuffer的depth buffer内容复制到default framebuffer的depth buffer; 这可以类似地用于颜色缓冲区和模板缓冲区。 如果我们然后渲染光立方体,立方体确实在场景的几何体上正确渲染:
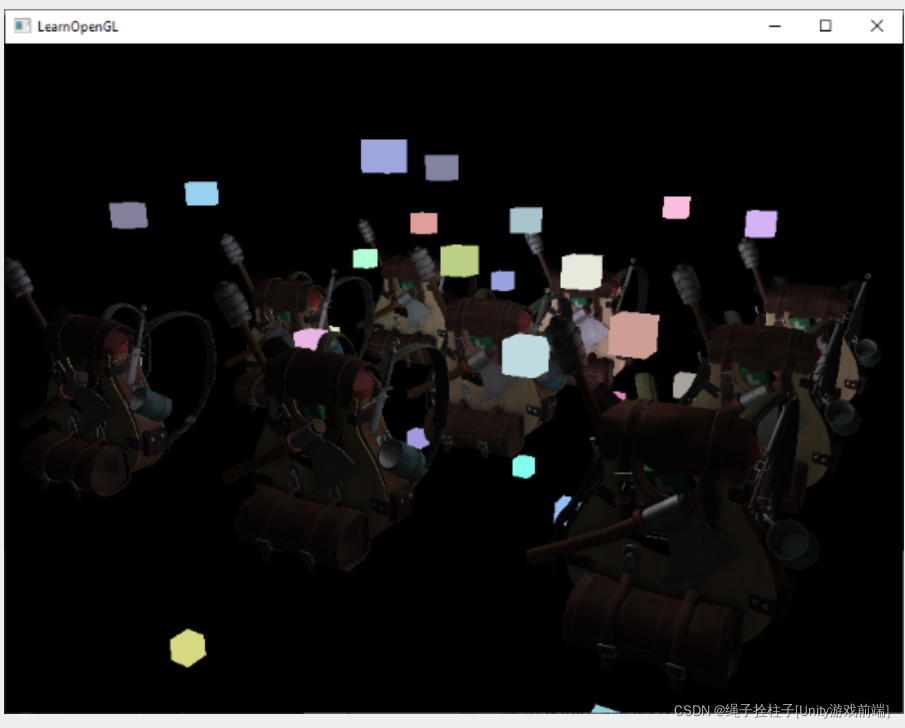
总结:由于把书包的depth buffer信息复制进来了,再渲染光方块,每个fragment都会对比depth buffer中的深度信息,进行调整。
通过这种方法,我们可以轻松地将deffered shader延迟着色与 forward shader前向着色结合起来。 这很棒,因为我们现在仍然可以应用需要特殊着色器效果的混合和渲染对象,这在纯延迟渲染上下文中是不可能的。
4.A larger number of lights (更多的灯)
延迟渲染经常受到赞誉的是,它能够渲染大量光源,而不会产生高昂的性能成本。延迟渲染本身不允许使用非常大量的光源,因为我们仍然需要为场景的每个光源计算每个片段的照明组件。使大量光源成为可能的是我们可以应用于延迟渲染管道的非常巧妙的优化: light volumes光量。
通常,当我们在大型光照场景中渲染片段时,我们会计算场景中每个光源的贡献,而不管它们与片段的距离如何。这些光源中有很大一部分永远不会到达片段,那么为什么要浪费所有这些光照计算呢?
light volumes光量背后的想法是计算光源的半径或体积,即其光线能够到达fragments的区域。由于大多数光源使用某种形式的衰减,我们可以使用它来计算它们的光能够到达的最大距离或半径。然后,我们只在片段位于这些光体积中的一个或多个内时才进行昂贵的光照计算。这可以为我们节省大量的计算,因为我们现在只计算必要的光照。
这种方法的诀窍主要是弄清楚光源的光体积的大小或半径。
4.1 Calculating a light's volume or radius (计算光的体积或者范围)
为了获得光的体积半径,我们必须求解光贡献何时变为 0.0 的衰减方程。 对于衰减函数,我们将使用light casters投光器章节中介绍的函数:
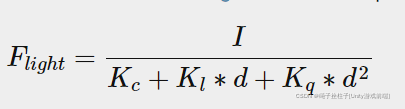
我们要做的是求解当 Flight 为 0.0 时的方程。 然而,这个方程永远不会精确地达到 0.0 的值,所以不会有解。 然而,我们可以做的不是求解 0.0 的方程,而是求解接近 0.0 但仍被认为是暗的亮度值。 本章的演示场景可以接受 5/256 的亮度值; 为啥要除以 256,因为默认的 8 位帧缓冲区一帧光强,只能有1/256。
使用的衰减函数在其可见范围内大多是暗的。 如果我们将其限制为比 5/256 更暗的亮度,则光量会变得太大,因此效果会降低。 只要用户看不到光源在其体积边界处突然中断,我们就可以了。 当然,这总是取决于场景的类型; 较高的亮度阈值会导致较小的光量,从而提高效率,但会产生明显的伪影,其中照明似乎在体积的边界处中断。
我们必须求解的衰减方程变为:(左边由Flight变成了5/256)
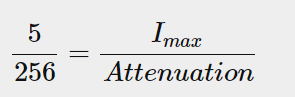
初中数学变换:
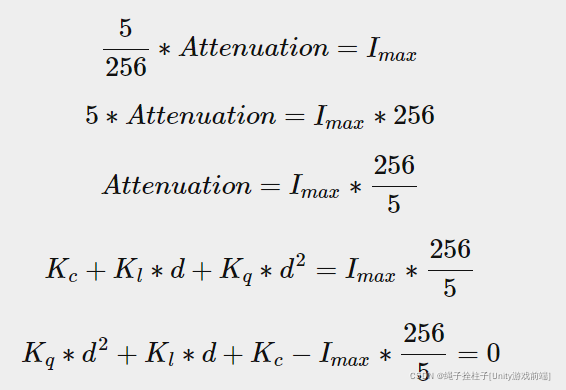
最后一个方程是 ax2+bx+c=0 形式的方程,我们可以使用二次方程求解:
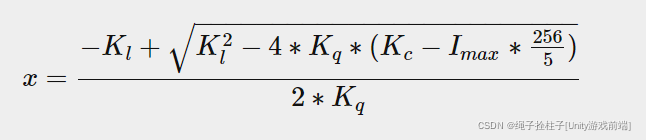
这也是初中数学知识
这为我们提供了一个通用方程,允许我们计算 x,即给定恒定、线性和二次参数的光源的光体积半径:
float constant = 1.0;
float linear = 0.7;
float quadratic = 1.8;
float lightMax = std::fmaxf(std::fmaxf(lightColor.r, lightColor.g), lightColor.b);
float radius =
(-linear + std::sqrtf(linear * linear - 4 * quadratic * (constant - (256.0 / 5.0) * lightMax)))
/ (2 * quadratic); 我们为场景的每个光源计算此半径,并仅在片段位于光源体积内时使用它来计算该光源的照明。 下面是更新的光照通道片段着色器,它考虑了计算的光量。 请注意,这种方法仅用于教学目的,在实际环境中不可行,因为我们将很快讨论:
教学版本fs:(仅教学,实际不可用)
struct Light {
[...]
float Radius;
};
void main()
{
[...]
for(int i = 0; i < NR_LIGHTS; ++i)
{
// calculate distance between light source and current fragment
float distance = length(lights[i].Position - FragPos);
if(distance < lights[i].Radius)
{
// do expensive lighting
[...]
}
}
}结果与之前完全相同,但这次每个灯光只计算其所在体积的光源的光照。
4.2 How we really use light volumes (非教学的真实情况下,如何使用光照体积)
上面显示的片段着色器在实践中并没有真正起作用,只是说明了我们如何可以使用灯光的体积来减少光照计算。现实情况是,您的 GPU 和 GLSL 在优化循环和分支方面非常糟糕。原因是 GPU 上的着色器执行是高度并行的,并且大多数架构都要求对于大量线程,它们需要运行完全相同的着色器代码以使其高效。这通常意味着运行着色器会执行 if 语句的所有分支,以确保着色器运行对于该组线程是相同的,从而使我们之前的半径检查优化完全无用;我们仍然会计算所有光源的光照!
(总结:为了保持100000个线程中的shader同步运行,每个shader中的if需要把所有条件都跑一遍,尽管很多if条件不满足的,也空跑一遍,导致我们优化了和没优化一样,我们必须缩减shader的总体计算量)
使用光照体积的适当方法是渲染actual spheres实际球体(就是渲染一个真实的球体),按光照体积半径进行缩放。这些球体的中心位于光源的位置,当它按光体积半径缩放时,球体正好包含光的可见体积。这就是诀窍所在:我们使用deffered shader延迟光照着色器(只渲染平面表面的光照)来渲染处理球体。由于渲染处理球体产生的片段着色器invocations调用与光源的照射的像素完全匹配,我们可以只光照渲染相关像素并跳过所有其他像素。下图说明了这一点:

这是针对场景中的每个光源完成的,并且生成的片段会相加混合在一起。结果是与之前完全相同的场景,但这次只渲染每个光源的相关片段。这有效地将计算从 nr_objects * nr_lights 减少到 nr_objects + nr_lights,这使得它在具有大量灯光的场景中非常高效。这种方法使得延迟渲染非常适合渲染大量灯光。
这种方法仍然存在一个问题:应该启用face culling 面部剔除(否则我们会渲染两次灯光效果),启用后用户可以输入光源的体积,之后体积不再渲染(由于背面剔除),去除光源的影响;我们可以通过只渲染球体的背面来解决这个问题。(说实话,这段没看懂,英文原文:
There is still an issue with this approach: face culling should be enabled (otherwise we'd render a light's effect twice) and when it is enabled the user may enter a light source's volume after which the volume isn't rendered anymore (due to back-face culling), removing the light source's influence; we can solve that by only rendering the spheres' back faces.)翻译:face culling(没正对着camera的面都剔除)应该开启(为了防止fragment进行light渲染两遍,正反各一遍),导致某个fragment按z轴计算,本来能进入一个光照体积,现在体积球朝里的三角形都被剔除了,导致进不了光照体积球了,我们的解决方案是只有光照球,是正反都要渲染的(其他三角形就朝背面的都剔除)
渲染光照体积确实会影响性能,虽然它通常比渲染大量光照的普通延迟着色快得多,但我们还有更多可以优化的地方。在延迟着色之上还有另外两个流行(并且更有效)的扩展,称为deferred lighting延迟光照和tile-based deferred shading.基于图块的延迟着色。这些在渲染大量光线时甚至更有效,并且还允许相对高效的 MSAA。
4.3 Deferred rendering vs forward rendering(延迟渲染与前向渲染对比)
就其本身(没有光量)而言,延迟着色是一个很好的优化,因为每个像素只运行一个片段着色器,而前向渲染我们通常每个像素运行多次片段着色器。延迟渲染确实有一些缺点:内存开销大,没有 MSAA,并且混合仍然必须通过前向渲染来完成。
当您有一个小场景并且没有太多灯光时,延迟渲染不一定更快,有时甚至更慢,因为开销超过了延迟渲染的好处。在更复杂的场景中,延迟渲染很快成为一个重要的优化;尤其是更高级的优化扩展。此外,一些渲染效果(尤其是后处理效果)在延迟渲染管道上变得更便宜,因为许多场景输入已经可以从 g-buffer获得。
作为最后一点,基本上所有可以通过前向渲染完成的效果也可以在延迟渲染上下文中实现;这通常只需要一个小的翻译步骤。例如,如果我们想在延迟渲染器中使用法线贴图,我们将更改几何通道着色器以输出从法线贴图(使用 TBN 矩阵)提取的世界空间法线,而不是表面法线;光照过程中的光照计算根本不需要改变。如果您希望视差映射起作用,您需要先置换几何通道中的纹理坐标,然后再对对象的漫反射、镜面反射和法线纹理进行采样。一旦您了解了延迟渲染背后的想法,那么获得创意就不会太难了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









