







谈谈MySql优化的一些事
前言概述:
MySql优化一直以来都是一个热议的话题,不管是在面试的过程中,还是企业中真实开发的场景下,可以说这已经是一名成熟程序员的必备之器了!所以今天我们一起总结一下关于MySql优化方向的一些常规手段和方案。
凭借着出色的性能、低廉的成本、丰富的资源,MySql已经成为绝大多数互联网公司的首选关系型数据库。可以看到Google,Facebook,Twitter,百度,新浪,腾讯,淘宝,网易,久游等绝大多数互联网公司数据库都是用的MySQL数据库,甚至将其作为核心应用的数据库系统。虽然性能出色,但所谓“好马配好鞍”,如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如“精通MySQL”、“SQL语句优化”、“了解数据库原理”等要求。我们知道一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
我们将这里进行一个较为全面的分析,让大家了解到MySQL的性能到底与哪些地方有关,以便于让大家寻找出其性能问题的根本原因,而尽可能清楚的知道该如何去优化自己的数据库。
在我们正式介绍优化之前还是要重点声明一个前提,那就是**一切优化工作都是建立在实际业务场景之上的,没有业务就谈优化就是耍流氓!**这里说明一下,无论多么好的优化方案都是针对相对业务设计的,脱离了业务对MySql优化高谈阔论的话那就是纸上谈兵。所以我们今天就会选取 电商项目中的订单模块的为例子来介绍整个优化思路。下面并以章节的形式来逐步探讨!
一、 优化的维度
首先,我们一起来看一下MySql优化的维度,这一部分决定了我们后面优化方案的取舍,所以值得关注!以下图为例 MySql数据库的优化大概可以考虑4个人维度,分别是 SQL及索引优化、数据库表结构优化、系统配置、硬件优化。这几个维度不难理解 重点在于 如何选择!我们通常会选择 性价比高的方案,由下图所示,这个倒金字塔最上方的应该就是性价比最高的方案,因为 优化效果突出而且成本较低!所以由此可见 我们本次分享也会符合这个思路,重点推出 SQL及索引优化 和 数据库表结构方面的优化
**成本:**需要特别注意一下,优化对整个系统造成的影响的大小决定了这件事的成本的大小,影响越大成本越高!而不是用金钱来衡量这个成本的
二、优化工具和监控Sql的手段的介绍
上一章节我们讲到优化维度,而经过分析重点优化方向就是 SQL及索引优化,那么问题来了,当一个系统已经上线,而我们也无法保证一次性就能写出最佳方案的SQL以及索引的应用。所以经过对项目的使用过程中对SQL的监控就变得尤为关键了,也是我们将来进行优化的重要依据!那么如何来对MySql 中的Sql执行进行监控呢?接下来我们就来接触几个概念:
**慢查询:**一种MySql的自带机制,可以监控MySql中Sql语句执行的具体情况 (日志的形式体现,后面会详解…)
**mysqldumpslow:**分析慢查询日志的工具,其中提供了大量的命令参数,可以让我们对 MySql 的慢查询日志进行归类分析,得到我们最想关注的SQL语句!
explain: 按照上面的思路我们已经可以分析出需要进行优化的Sql语句,那么究竟接下来要怎么优化,此时就要用到explain看查看SQL执行的查询计划,只有清晰的掌握了SQL的整个查询计划 那我们才能对症下药!
小结:
根据以上的介绍我们大概可以得出一个针对 查询优化的思路和流程
- 利用MySQL的慢查询功能检测MySql执行的情况,并根据自己的业务情况定义慢查询的标准。
- 利用mysqldumpslow工具对慢查询日志进行精准分析,获取需要优化的SQL语句
- 然后再利用 explain关键字查看这些执行慢的SQL 的查询计划,从而制定合适的优化策略
三、查询优化
上面一小节我们分析了如何进行优化分析的流程,接下来就一起说一下
查询优化的操作,在实际开发当中要掌握一个规律 通常都是 查多写少,所以查询优化也是我们本次文章分析的一个重点。
首先来了解一下MySql 中一个查询的执行流程是如何,如下图:
1.MySql的查询流程:
① 客户端将查询发送到服务器;
② 服务器检查查询缓存,如果找到了,就从缓存中返回结果,否则进行下一步。
③ 服务器解析,预处理。
④ 查询优化器优化查询
⑤ 生成执行计划,执行引擎调用存储引擎API执行查询
⑥服务器将结果发送回客户端。

查询缓存
在解析一个查询语句之前,如果查询缓存是打开的,那么MySQL会优先检查这个查询是否命中查询缓存中的数据,如果命中缓存直接从缓存中拿到结果并返回给客户端。这种情况下,查询不会被解析,不用生成执行计划,不会被执行。
语法解析和预处理器
MySQL通过关键字将SQL语句进行解析,并生成一棵对应的“解析树”。MySQL解析器将使用MySQL语法规则验证和解析查询。
查询优化器
语法书被校验合法后由优化器转成查询计划,一条语句可以有很多种执行方式,最后返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
查询执行引擎
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这个执行计划来完成整个查询。最常使用的也是比较最多的引擎是MyISAM引擎和InnoDB引擎。mysql5.5开始的默认存储引擎已经变更为innodb了。
了解查询流程后,我们就详细的来进行优化操作!
3.1 设置MySql的慢查询规则
**准备业务场景:**以电商项目场景的 订单表为例子!
创建一个新的数据库 --> 执行dianshang.sql --> 执行 order_init.sql
注意: 这里我们模拟了 百万级别的数据,如果数据量不够达不到优化的效 果!
1.1 在Dos命令窗口下操作:
-
登录MySql
-
查看Mysql的慢查询日志功能是否开启
show variables like ‘%slow_query_log%’;
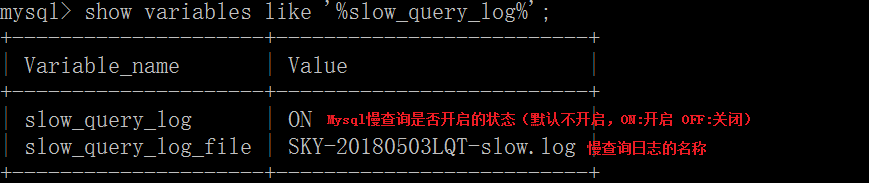
-
开启慢查询功能:
set global slow_query_log = 1/ON
-
自定义慢查询时间规则
set long_query_time =1 (单位是 秒)
注意: 通过命令进行设置可能马上不会生效,如果要永久生效,最好在 my.ini 文件中修改 my.cnf 需要从起MySql服务
- 执行Sql语句 --> 查询统计订单详情表
select count(*)from tb_order_detail;
-
此时打开MySql服务的Data目录

此文件就是慢查询日志文件,打开文件后会发现记录了查询执行超过1秒的SQL语句!

OK!到此完成了慢查询的设置!!!
3.2 慢查询日志文件的分析工具 mysqldumpslow
刚才我们成功的记录了慢查询日志,接下来就要对日志进行详细分析!
注意:
mysqldumpslow 工具依赖 Perl环境!
Linux环境下:安装完MySql服务 自带 mysqldumpslow ,因为Linux 环境
自带Perl环境 。
Window环境下:需要咱们自己先安装 Perl环境
1.对慢查询日志经行分析
根据查询时间进行排序:
mysqldumpslow.pl -s t C:/SKY-20180503LQT-slow.log
2.将分析得到的Sql语句记录出来
**小结:**到此我们也就完成了对慢查询日志的分析以及SQL语句的筛选工作
3.3 Explain 分析Sql的执行计划
Explain 分析Sql语句
EXPLAIN select * from tb_order where user_id = 1212741731695472640

id:不重要,它就是当前记录的一个序号 忽略不计
-
select_type: 表示当前执行的Sql的查询类型
- SIMPLE: 简单的Sql (只有一个Select)
- PRIMARY: 子查询中最外层的查询
- SUB QUERY: 子查询(第二个或者后面的查询)
- UNION: 查询语句中使用了UNION关键字(合并查询)
-
table : 当前要查询操作的表
-
type: 查询性能级别的体现
const > eq_ref > ref > ref_or_null > range > index > ALL
- ALL: 全表扫描,查询的时候没有用到任何优化策略(没有使用任何索引)
- index: 全索引扫描
- range: 在索引上进行范围查找
- ref_or_null : 在索引上进行null值的判断
- ref : 在索引上进行 等值 查找
- eq_ref: 索引上只有一个可选项
- const: 常量查询,通常是主键 唯一索引 经过MySql查询优化器处理后的结果!
-
possible_keys: 查询过程中可能会使用的索引
-
key: 实际查询中用到的索引
-
key_len: 索引的字段的值数据类型的长度
-
ref: 使用索引的等值查询,会显示const
-
**rows: ** 执行查询预计要扫描的行数,这个不精准 仅供参考
-
filtered: 查询的数据 预计占总行数的百分比,这个值不准仅供参考
**小结:**到此我们就可以清晰的查看本次SQL的执行计划,然后对其进行适当 的优化,那么如何优化呢?针对查询优化 索引 是很重要的一个手段,所以下一小结重点就是介绍索引优化…
3.4 索引优化
**前言概述:**索引的使用时MySql查询优化的重要手段,下面我们就详细的介 绍索引优化!
3.4.1 首先给条件字段user_id创建索引
– ALTER TABLE tb_order add INDEX user_idx(user_id);
3.4.2 再通过Explain来看Sql的执行计划 如下:

发现查询计划中已经用到了索引!
3.4.3 索引的底层数据结构是什么呀,有很多人都会问这个问题,我们一起来 看一下? 如下图所示 :
- BTree

-
B-Tree --> 聚集型索引

-
B+Tree非聚集型索引

**小结:**这里介绍索引底层的数据结构,通过图例分析了它的原理
3.4.4 使用索引的基本必备常识
- 常见的索引类型
普通索引:只能提供查询加速的功能
主键索引:唯一且非空
唯一索引: 要求数据的唯一性,NULL除外
组合索引: 多个字段创建联合索引
hash索引: 全内存查找,和Memory 存储引擎配合的很好
fullText: 全文索引
-
创建索引的原则
1.数据的辨识度不能低于70% (辨识度:字段内的数据唯一值的个数)
age 100条数据–>理想状态 100种情况 > 70%
sex 100条数据 --> 理想状态 2中情况 < 70%
2.经常作为where 条件的字段适合加索引或者组合索引
3.经常作为多表连接的字段适合加索引
4.经常作为排序字段出现适合加索引
-
索引的失效场景
1.不要使用 != / < > /not in / is null/ in not null
2.不要在索引字段上进行运算 where id + 1 = 100;
3.不要在字符串列上使用隐式的类型转换 phone = 18811011011,但是反 过来可以
场景一: varchar 类型的字段 phone (字符串)–>给这个字段加了索引
where phone = ‘18811011011’; (不失效)
where phone = 18811011011; (失效 --> 因为传的参数是 数值 类 型而字段本身是字符串类型,在做等值比较的时候MySql会进行 隐式类型 转换)
**场景二:**int 类型字段 phone (数值)—> 不管有没有隐式转换 索引都不 失效
4.使用like关键字不遵循左前缀匹配规则 phone like ‘%000’
5.当使用组合索引的时候 切记 要遵循左前匹配规则,如果不遵循索引就失效啦
– 组合索引创建
ALTER TABLE tb_order add INDEX user_idx(user_id,role_id);
where user_id = 1 and role_id = 2 (不失效)
where role_id = 1 and user_id = 2(不失效)
where user_id = 1 (不失效 --> 遵循了左前匹配规则)
where role_id = 2 (失效 --> 违反了左前匹配规则)
3.5 优化实战-以订单表为例
**前言:**有了以上的知识储备,下面我们就对 订单表 设置两个业务场景进行优化操作!
**场景1:**快年底了,公司要决策来年的战略部署,需要参考很多报表数据!
需求1:统计9月份订单总金额
– 场景:快年底了,公司要决策来年的战略部署,需要参考很多报表数据!
– 需求:统计9月份订单总金额
– Sql:
select sum(total_fee) from tb_order
where pay_time >= ‘2019-09-01 00:00:00’
and pay_time < ‘2019-10-01 00:00:00’
– 执行时间 1.6秒
– 优化1:给pay_time 加索引
create index pay_time_idx on tb_order(pay_time)
– 执行结果 8秒(效率不升反降)
– 问题:在使用多字段查询数据的时候建议使用 组合索引
– 创建组合索引
create index paytime_totalfee_idx on tb_order(pay_time, total_fee)
**场景2:**快年底了,公司要决策来年的战略部署,需要参考很多报表数据!
需求2:统计9月份订单总金额
– 场景2:快年底了,公司要决策来年的战略部署,需要参考很多报表数据!
– 需求:统计9月份销量最好的商品
select sku_id, count(1) cnt from tb_order_detail
where create_time
BETWEEN ‘2019-09-01 00:00:00’
AND ‘2019-10-01 00:00:00’
GROUP BY sku_id
ORDER BY cnt
LIMIT 1
– 执行时间 3.1 秒(需要优化)
– 解决方案:创建组合索引
create
index createtime_skuid_idx
on tb_order_detail(create_time, sku_id)
– 优化结果 0.2秒
总结:以上就本作者对MySql的查询优化中的重点索引优化的一些拙见和精力很高兴和大家分享!
四、数据库结构优化
**前言:**上面是针对查询索引方面的优化,当然MySql优化方案远不止如此,本小节就来聊聊数据库结构方面的优化策略
1.优化表结构
– 尽量将表字段定义为NOT NULL约束
– 定义字段的时候能用数值类型就不要用字符串
– VARCHAR的长度只分配真正需要的空间
– 尽量使用TIMESTAMP而非DATETIME,但TIMESTAMP只能表示1970 - 2038年,比DATETIME表示的范围小得多,而且TIMESTAMP的值因时区不同而不同。
– 单表不要有太多字段,建议在20以内
– 合理的加入冗余字段可以提高查询速度。(建议在冗余字段上加 - 索引)
2.读写分离
**备注:**Mysql中的读写分离和Redis中的一样的!

3.表拆分
3.1垂直拆分
场景: 在实际开发当中,考虑一个表字段过多或者对字段的值的大小进行区分,通常都会进行垂直拆分。例如 spu 和 spu_detail

注意事项:
– 插入的时候使用事务,也可以保证两表的数据一致。
3.2 水平拆分
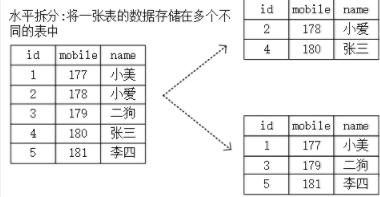
问题:水平拆分后 当查询的时候如何准确定位 查那张表?
- 1.切分键原理拆表

2.基因提取法
场景: 注册的时候利用手机号注册,后期可能会出现根据手机号查询用户,那将来根据手机号查询的时候应该查询那一张表?
– 在生成数据的时候就利用到 基因提取法 方案 生成用户id,这样一来 在查询的时候,还是利用取模的方式 就能准确定位要查那一张表!

4.MySql数据库集群
场景:考虑到高并发和高可用 我们可以采取数据库集群的解决方案!
如下图所示:

五、存储优化
**前言:**如何把控在存储方面的优化思路,前提得了解MySql中的两大常用存储引擎!
1.在Mysql中查看存储引擎的方式:
show ENGINES;

2.Innodb和MyISAM的区别
-
– MyISAM是非事务安全型的,而InnoDB是事务安全型的。
-
– MyISAM锁的粒度是表级,而InnoDB支持行级锁定。
-
– MyISAM不支持外键,而InnoDB支持外键
-
– MyISAM相对简单,所以在效率上要优于InnoDB,小型应用可以考虑使用 MyISAM。
-
– InnoDB表比MyISAM表更安全。
-
– MyISAM对聚合查询支持很好,如果频繁的统计计算的需求建议使用MyISAM
3.实际开发中两种存储引擎的取舍!
Innodb一般用于核心业务系统,而且要求支持事务的场景下,MyISAM一般用于服务辅助核心业务系统的边缘化系统,类似于报表统计系统!

4.存数据的时候需要考虑的优化策略
- 禁用索引
禁用-- alter table 表名 disable keys;
开启-- alter table 表名 enable keys;
- 禁用唯一性检查
禁用-- set unique_checks = 0;
开启-- set unique_checks =1;
- 禁用外键检查
禁用-- set foreign_key_checks = 0;
开启-- set foreign_key_checks = 1;
- 禁止自动提交
禁用:SET autocommit = 0;
开启:SET autocommit = 1;
- 批量插入数据
insert into 表名 values (…),(…),(…)
综上所述:提升Insert 效率其实在插入数据的时候尽量少维护其他东西
六、缓存优化
备注: MySql的查询缓存5.7.20版本之后不建议使用MySql的查询,并且在MySql8.0中已经删除了查询缓存功能!
原因: 表中只要有一条数据发生变更,整张表的查询缓存就都失效了!
**注意:**本小节内容读者们只需要了解即可,因为上面说的很清楚,MySql缓存这一块已经逐步在削弱甚至舍弃,以下内容也是大概介绍一些缓存的配置参数,望大家理解!
1.全局缓存 --> 针对MySql整体而言
-
key_buffer_size
只能在MyIASM中使用,读取索引文件存储
-
innodb_buffer_pool_size
设置MySql分页信息的缓存的大小

-
innodb_additional_mem_pool_size
用来设置存储MySql内部数据的结构缓存区域,如果表很对,建议调大一下!
-
innodb_log_buffer_size
设置Innodb日志文件的缓冲区大小

2.局部缓存 --> 针对MySql的表
-
read_buffer_size
对数据库表进行顺序扫描,读取的缓冲区,如果经常做顺序扫描建议调 大 一点!
-
sort_buffer_size
排序的缓冲区,如果查询中 排序的需求很对,就把这个调大点
- read_rnd_buffer_size
随机读取的缓冲区,如果需要排序大量数据,可适当调高该值。
-
tmp_table_size
临时表缓冲区,表连接查询的时候会出现临时表,如果频繁操作表链接查 询的时候,建议调大点!
-
record_buffer
线程对表进行扫描的时候,为这个线程开辟的缓冲区,如果经常做顺序扫描,建议调大点!
3.其他缓存
-
table_cache
表的高速缓存,当访问一个表的时候,MySql会为这个表开辟一个高速缓存, 如果缓存已满,MySql会 热点数据缓存机制,会将那些不经常用的表的缓存清除掉
-
thread_cache_size
可以理解为Mysql 数据库的线程池当连接断开时,Mysql 会保留处理连接的线程信息,当再次有信的请求过来时,会复用 对数据库表进行顺序扫描,读取的缓冲区,如果经常做顺序扫描建议调 大 一点!
-
sort_buffer_size
排序的缓冲区,如果查询中 排序的需求很对,就把这个调大点
- read_rnd_buffer_size
随机读取的缓冲区,如果需要排序大量数据,可适当调高该值。
-
tmp_table_size
临时表缓冲区,表连接查询的时候会出现临时表,如果频繁操作表链接查 询的时候,建议调大点!
-
record_buffer
线程对表进行扫描的时候,为这个线程开辟的缓冲区,如果经常做顺序扫描,建议调大点!
3.其他缓存
-
table_cache
表的高速缓存,当访问一个表的时候,MySql会为这个表开辟一个高速缓存, 如果缓存已满,MySql会 热点数据缓存机制,会将那些不经常用的表的缓存清除掉
-
thread_cache_size
可以理解为Mysql 数据库的线程池当连接断开时,Mysql 会保留处理连接的线程信息,当再次有信的请求过来时,会复用















 575
575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









