







马尔科夫过程:
该过程中,每个状态的转移只依赖于之前的 n 个状态,这个过程被称为1个 n 阶的模型,其中 n 是影响转移状态的数目。
如果是1阶:
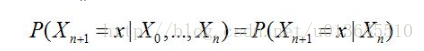
状态只与前一时刻状态有关。
隐马尔科夫模型:
状态不可获得,称作隐藏状态,但能够由观测状态推断隐藏状态,即可以观察到的状态序列和隐藏的状态序列是概率相关的。
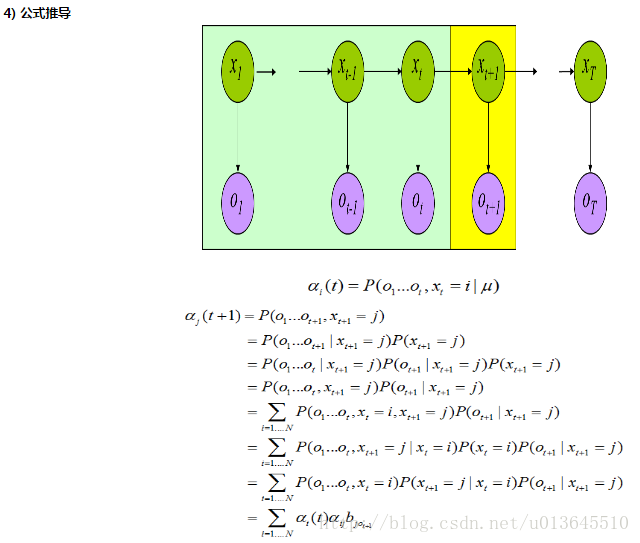
于是我们可以将这种类型的过程建模为有一个隐藏的马尔科夫过程和一个与这个隐藏马尔科夫过程概率相关的并且可以观察到的状态集合。这就是本文重点介绍的隐马尔可夫模型。
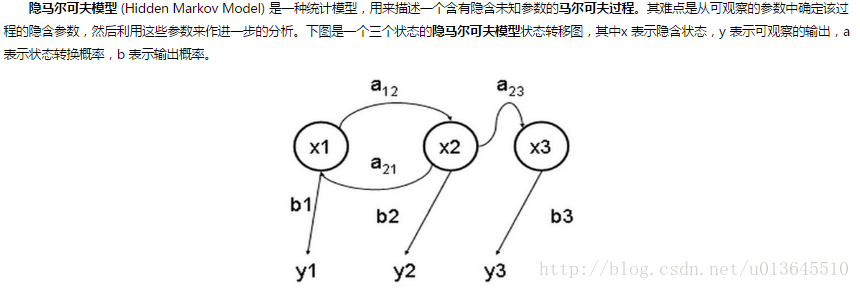
HMM的假设

状态转移矩阵、混淆矩阵
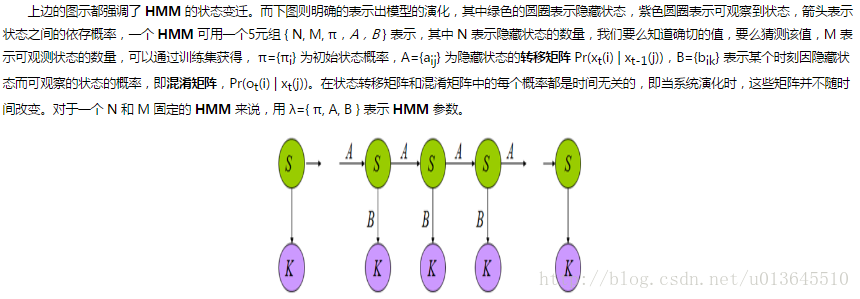
HMM三个典型问题
(一) 已知模型参数,计算某一给定可观察状态序列的概率

在特定HMM模型下,可计算可观察序列的概率。有多个HMM模型,通过可观察序列的概率,判断最有可能实现这个观察序列的HMM模型。
例如:通常我们会使用很多 HMM,每一个针对一个特别的单词。一个可观察状态的序列是从一个可以听到的单词向前得到的,然后这个单词就可以通过找到满足这个可观察状态序列的最大概率的 HMM 来识别。
前向算法
(1)穷举法,计算所有隐藏状态下出现这个观察序列的概率,相加求和。但是该算法计算效率低,我们可以利用概率不随时间变化这个假设来降低时间的开销。
(2)使用递归来降低复杂度
我们可以首先定义一个部分概率,表示达到某个中间状态的概率。

a) 计算 t=1时候的部分概率
当 t=1 的时候,没有路径到某个状态,所以这里是初始概率,Pr(状态 j | t=0) = π(状态 j ),这样我们就可以计算 t=1 时候的部分概率为:
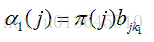
k1 表示第一个观察状态,bjk1 表示隐藏状态是 j,但是观察成 k1 的概率,是混淆矩阵里值。
b) 计算 t>1 时候的部分概率
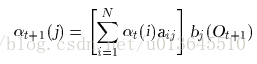
t+1时刻到达状态j,t时刻的观察状态可来自所有隐藏状态(t时刻的观察状态来自某个隐藏状态正好为t时刻的部分概率),之后t时刻隐藏状态再转移到t+1时刻隐藏状态j。所以公式大括号部分,为t+1时刻到达状态j的所有路径概率。
(二)根据可观察状态的序列找到一个最可能的隐藏状态序列
和上面一个问题相似的并且更有趣的是根据可观察序列找到隐藏序列,使用 Viterbi 算法来根据可观察序列得到最优可能的隐藏状态的序列。
应用实例:一个广泛使用 Viterbi 算法的领域是自然语言处理中的词性标注。句子中的单词是可以观察到的,词性是隐藏的状态。通过根据语句的上下文找到一句话中的单词序列的最有可能的隐藏状态序列,我们就可以得到一个单词的词性(可能性最大)。这样我们就可以用这种信息来完成其他一些工作。
如何找到可能性最大的隐藏状态序列?
(1)穷举法
根据观察序列,计算所有可能的隐藏序列的概率,我们可以找到一个可能性最大的隐藏序列。
(2)递归算法
我们可以先定义一个部分概率 δ,即到达某个中间状态的概率。接下来我们将讨论如何计算 t=1 和 t=n (n>1) 的部分概率。
注意这里的部分概率和前向算法中的部分概率是不一样的,这里的部分概率表示的是在t时刻最可能到达某个观察状态的一条路径的概率,而不是所有概率之和。
a) 部分概率和部分最优路径
我们可以用 δ(i, t) 来表示在t时刻,到状态i的所有可能的序列(路径)中概率最大的序列的概率,部分最优路径就是达到这个最大概率的路径,对于每一个时刻的每一个状态都有这样一个概率和部分最优路径。
b)计算 t=1 时刻的部分概率
当 t=1 时刻的时候,到达某个状态最大可能的路径还不存在,但是我们可以直接使用在 t=1 时刻某个状态的概率和这个状态到可观察序列 k1 的转移概率:
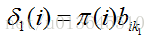
c) 计算 t>1 时刻的部分概率

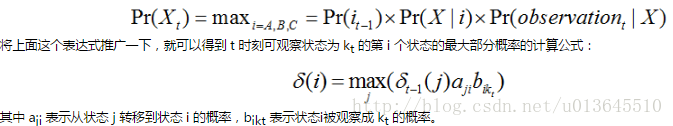
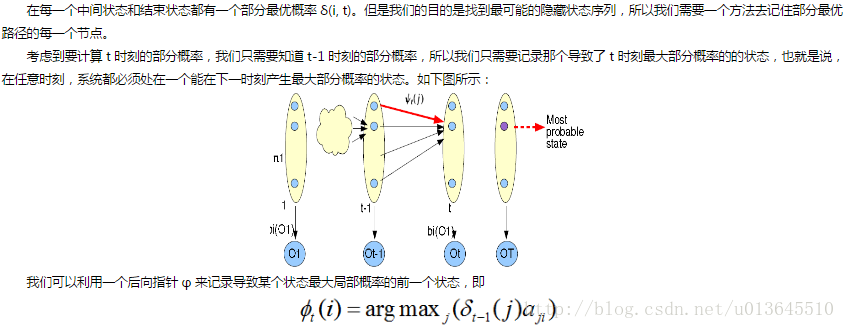

(三) 根据观察到的序列集来找到一个最有可能的 HMM。
通过EM算法等,更新HMM参数模型。
HMM的三大应用
应用(Uses associated with HMMs)
一旦一个系统可以作为HMM被描述,就可以用来解决三个基本问题。其中前两个是模式识别的问题:给定HMM求一个观察序列的概率(评估);搜索最有可能生成一个观察序列的隐藏状态序列(解码)。第三个问题是给定观察序列生成一个HMM(学习)。
a) 评估(Evaluation)
考虑这样的问题,我们有一些描述不同系统的隐马尔科夫模型(也就是一些( pi,A,B)三元组的集合)及一个观察序列。我们想知道哪一个HMM最有可能产生了这个给定的观察序列。例如,对于海藻来说,我们也许会有一个“夏季”模型和一个“冬季”模型,因为不同季节之间的情况是不同的——我们也许想根据海藻湿度的观察序列来确定当前的季节。
我们使用前向算法(forward algorithm)来计算给定隐马尔科夫模型(HMM)后的一个观察序列的概率,并因此选择最合适的隐马尔科夫模型(HMM)。
在语音识别中这种类型的问题发生在当一大堆数目的马尔科夫模型被使用,并且每一个模型都对一个特殊的单词进行建模时。一个观察序列从一个发音单词中形成,并且通过寻找对于此观察序列最有可能的隐马尔科夫模型(HMM)识别这个单词。
b) 解码( Decoding)
给定观察序列搜索最可能的隐藏状态序列。
另一个相关问题,也是最感兴趣的一个,就是搜索生成输出序列的隐藏状态序列。在许多情况下我们对于模型中的隐藏状态更感兴趣,因为它们代表了一些更有价值的东西,而这些东西通常不能直接观察到。
考虑海藻和天气这个例子,一个盲人隐士只能感觉到海藻的状态,但是他更想知道天气的情况,天气状态在这里就是隐藏状态。
我们使用Viterbi 算法(Viterbi algorithm)确定(搜索)已知观察序列及HMM下最可能的隐藏状态序列。
Viterbi算法(Viterbi algorithm)的另一广泛应用是自然语言处理中的词性标注。在词性标注中,句子中的单词是观察状态,词性(语法类别)是隐藏状态(注意对于许多单词,如wind,fish拥有不止一个词性)。对于每句话中的单词,通过搜索其最可能的隐藏状态,我们就可以在给定的上下文中找到每个单词最可能的词性标注。
C)学习(Learning)
根据观察序列生成隐马尔科夫模型。
第三个问题,也是与HMM相关的问题中最难的,根据一个观察序列(来自于已知的集合),以及与其有关的一个隐藏状态集,估计一个最合适的隐马尔科夫模型(HMM),也就是确定对已知序列描述的最合适的(pi,A,B)三元组。
当矩阵A和B不能够直接被(估计)测量时,前向-后向算法(forward-backward algorithm)被用来进行学习(参数估计),这也是实际应用中常见的情况。
感谢博客:隐马尔可夫模型(HMM)攻略
http://blog.csdn.net/likelet/article/details/7056068















 270
270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









