







注: 英文引文,机翻未校。
中文引文,未整理去重。
此系列文章整理自不同时期,生料有重叠,未整理去重。
What is Byte and How Does it Work?
字节是什么以及它是如何工作的?
December 31, 2024 by UMATechnology
Introduction
简介
In the vast world of computers and digital technology, you frequently hear terms like bits, bytes, kilobytes, megabytes, and more. Among these, the byte stands out as a fundamental unit of data storage and communication. While most people use bytes daily, few understand their nuances, significance, and inner workings. This article will cover what a byte is, its history, structure, comparison with bits, how it works in data representation, and its role in modern computing.
在广阔的计算机和数字技术世界中,你经常会听到比特(bit)、字节(byte)、千字节(kilobyte)、兆字节(megabyte)等术语。在这些术语中,字节是数据存储和通信的基本单位,尤为突出。虽然大多数人每天都在使用字节,但很少有人了解字节的细微差别、重要性以及其内部工作原理。本文将涵盖字节是什么、它的历史、结构、与比特的比较、它在数据表示中的工作方式以及它在现代计算中的作用。
Defining a Byte
定义字节
A byte is a unit of digital information that consists of eight bits. A bit, the most basic unit of data in computing, can hold a value of 0 or 1. Thus, a byte can represent 256 different values, ranging from 0 to 255 (in decimal notation). This vast range makes the byte the primary building block for representing complex pieces of information such as characters, images, audio, and video.
字节是一种数字信息单位,由** 8 个比特**组成。比特是计算中最基本的数据单位,它可以存储值 0 或 1。因此,一个字节可以表示 256 种不同的值,范围从 0 到 255(以十进制表示)。这个广泛的取值范围使得字节成为表示复杂信息(如字符、图像、音频和视频)的主要组成部分。
A Brief History of Bytes
字节简史
The concept of a byte emerged in the early days of computing. In the 1950s, computer scientists were defining how data should be stored and processed. The term “byte” was first coined byDr. Werner Buchholz in 1956, who was a part of IBM’s team working on the IBM 7030 Stretch computer. Initially, a byte could be of a variable length depending on the architecture; however, as computing evolved, the eight-bit byte became a standard for data representation.
字节的概念出现在计算技术的早期。20世纪50年代,计算机科学家们正在定义数据应如何存储和处理。“字节” 这个术语最早是由沃纳·布赫霍尔茨(Werner Buchholz)博士在 1956 年创造的,他是 IBM 团队中致力于 IBM 7030 Stretch 计算机研究的一员。最初,根据不同的架构,一个字节的长度可以是可变的;然而,随着计算技术的发展, 8 位字节成为了数据表示的标准。
How Bytes Work in Data Representation
字节在数据表示中的工作方式
1. Encoding Characters
字符编码
One of the most fundamental uses of bytes is in character encoding. For instance, ASCII (American Standard Code for Information Interchange) is a character encoding standard that uses a single byte to represent various characters. With ASCII, the uppercase letter “A” is represented by the byte 01000001, which is 65 in decimal.
字节最基本的用途之一是在字符编码中。例如,ASCII(美国信息交换标准代码)是一种字符编码标准,它使用单个字节来表示各种字符。在 ASCII 中,大写字母 “A” 由字节 01000001 表示,其十进制值为 65。
With the evolution of technology and the need to support international characters, Unicode emerged. While the original version of Unicode used one or two bytes per character, platforms moved towards more efficient encoding schemes like UTF-8, which can use one to four bytes depending on the character. UTF-8 allows ASCII characters to be represented as a single byte while accommodating characters from virtually all writing systems in the world.
随着技术的发展以及对支持国际字符的需求,Unicode 应运而生。虽然 Unicode 的原始版本每个字符使用一到两个字节,但各种平台逐渐采用了更高效的编码方案,如 UTF-8,它可以根据字符的不同使用一到四个字节。UTF-8 允许 ASCII 字符用单个字节表示,同时也能容纳世界上几乎所有书写系统的字符。
2. Storing Images
存储图像
In the context of images, a byte plays a crucial role in defining pixel colors. For example, in an RGB (Red, Green, Blue) color model, each pixel’s color is represented using three bytes, one for each color. Each byte can represent values from 0 to 255, allowing for over 16 million different color combinations (256 x 256 x 256).
在图像领域,字节在定义像素颜色方面起着至关重要的作用。例如,在 RGB(红、绿、蓝)颜色模型中,每个像素的颜色使用三个字节来表示,每种颜色对应一个字节。每个字节可以表示从 0 到 255 的值,这使得可以有超过 1600 万种不同的颜色组合(256×256×256)。
3. Storing Audio and Video
存储音频和视频
When it comes to audio data, a byte represents various samples of sound. For instance, standard audio data is typically stored in PCM (Pulse-Code Modulation) format, where each sample is represented as a byte. Higher-quality audio may use more bytes per sample to capture the intricacies of sound.
对于音频数据,一个字节表示声音的各种样本。例如,标准音频数据通常以 PCM(脉冲编码调制)格式存储,其中每个样本用一个字节表示。更高质量的音频可能会为每个样本使用更多字节,以捕捉声音的细微差别。
For video, data is stored similarly, often compressing sequences of frames into formats like MPEG. Each frame is made up of bytes representing pixel colors, sound, and additional metadata, which results in a significant amount of data being processed every second.
对于视频,数据的存储方式类似,通常将帧序列压缩成 MPEG 等格式。每一帧都由表示像素颜色、声音和其他元数据的字节组成,这导致每秒都要处理大量的数据。
The Byte-Bit Relationship
字节与比特的关系
1. Understanding Bit vs. Byte
理解比特与字节
A bit is the smallest unit of data in computing, while a byte, consisting of eight bits, is used as a standard for data storage. For example, the bit string 10101011 is an eight-bit representation that forms one byte. Bits are primarily used to convey binary information, while bytes are used to represent more complex data types.
比特是计算中最小的数据单位,而由 8 个比特组成的字节则被用作数据存储的标准单位。例如,比特串 10101011 是一个 8 位的表示形式,构成一个字节。比特主要用于传达二进制信息,而字节则用于表示更复杂的数据类型。
2. Bit Rates and Byte Rates
比特率和字节率
When it comes to measuring data transfer speed, two common terms come into play: bit rate and byte rate. Bit rate refers to the number of bits transmitted in a given time period (usually measured in bits per second, or bps). In contrast, byte rate specifies the number of bytes transmitted per second. To convert between these units, remember that one byte equals eight bits. Thus, if you have a data transfer rate of 1 megabit per second (Mbps), that translates to 0.125 megabytes per second (MBps).
在衡量数据传输速度时,有两个常用术语:比特率和字节率。比特率是指在给定时间段内传输的比特数(通常以比特每秒,即 bps 为单位)。相比之下,字节率指定每秒传输的字节数。要在这些单位之间进行转换,请记住一个字节等于 8 个比特。因此,如果你的数据传输速率为 1 兆比特每秒(Mbps),那么换算成字节率就是 0.125 兆字节每秒(MBps)。
Applications of Bytes in Computing
字节在计算中的应用
1. File Sizes and Storage
文件大小和存储
Bytes are crucial in defining file sizes. Operating systems measure files in bytes, with the standard units being kilobytes (KB), megabytes (MB), gigabytes (GB), and terabytes (TB). This measurement system is critical for determining how much data can be stored on a device, whether it’s a hard drive, USB flash drive, or cloud storage.
字节在定义文件大小方面至关重要。操作系统以字节为单位来衡量文件大小,标准单位有千字节(KB)、兆字节(MB)、吉字节(GB)和太字节(TB)。这个测量系统对于确定设备(无论是硬盘驱动器、USB 闪存驱动器还是云存储)上可以存储多少数据至关重要。
2. Data Transmission
数据传输
In networking, bytes populate the datasets being transmitted across networks. Understanding how bytes function at the protocol level, such as TCP/IP, is essential for system administrators and network engineers. Data is encapsulated in packets that contain headers and payloads, all measured in bytes.
在网络中,字节构成了在网络中传输的数据集。对于系统管理员和网络工程师来说,了解字节在协议层(如 TCP/IP)的工作方式至关重要。数据被封装在包含头部和有效载荷的数据包中,所有这些都以字节为单位进行衡量。
3. Programming and Data Structures
编程和数据结构
In programming, bytes are often manipulated directly through various data types. For instance, languages such as C and C++ allow for direct byte manipulation using pointers. Other high-level languages abstract these details but still rely on bytes to represent strings, integers, structures, and arrays.
在编程中,字节通常通过各种数据类型直接进行操作。例如,C 和 C++ 等语言允许使用指针直接操作字节。其他高级语言会对这些细节进行抽象,但仍然依赖字节来表示字符串、整数、结构和数组。
The One, the Four, and Beyond: Multiple Bytes
一、四及更多:多个字节
1. Nibble
半字节(四位组)
A nibble is half a byte, consisting of four bits. Nibbles are typically used to represent hexadecimal numbers. In hexadecimal, a single digit can represent values from 0 to 15, which fits neatly into four bits. Nibbles are useful in contexts such as memory addressing and digital design.
半字节(nibble) 是半个字节,由四个比特组成。半字节通常用于表示十六进制数。在十六进制中,单个数字可以表示从 0 到 15 的值,正好可以用四个比特来表示。半字节在内存寻址和数字设计等方面很有用。
2. Word Sizes
字长
In computer architecture, devices may utilize varying word sizes. A word is a unit of data defined by the width of the CPU’s registers. For example, a 32-bit architecture has a word size of four bytes, while a 64-bit architecture has a word size of eight bytes. This distinction is crucial for the performance and capacity of the processor and memory interactions.
在计算机体系结构中,设备可能会使用不同的字长。字(word) 是由 CPU 寄存器的宽度定义的数据单位。例如,32 位架构的字长为四个字节,而 64 位架构的字长为 8 个字节。这种区别对于处理器的性能以及与内存交互的能力至关重要。
3. Data Structures: Arrays and Buffers
数据结构:数组和缓冲区
Bytes are the basis for more complex data structures like arrays and buffers. An array is a collection of bytes that can represent anything from integers to custom data objects. Buffers, often used in data streaming, temporarily hold bytes to manage data transfer across processes or hardware.
字节是更复杂的数据结构(如数组和缓冲区)的基础。数组是字节的集合,可以表示从整数到自定义数据对象的任何内容。缓冲区常用于数据流中,它临时存储字节,以管理跨进程或硬件的数据传输。
Conclusion
结论
Understanding the byte and its significance provides a window into the world of digital data. Every application, system, and piece of technology you interact with relies on bytes to convey information, whether it’s displaying a webpage or saving your digital photographs. As technology evolves, the role of bytes remains imperative, extending into realms such as artificial intelligence, big data, and blockchain, where large volumes of data are processed and manipulated. By comprehending what bytes are and how they work, you’re better equipped to navigate and understand the digital landscape around you.
了解字节及其重要性为我们打开了一扇通往数字数据世界的窗口。你所使用的每一个应用程序、系统和技术都依赖字节来传达信息,无论是显示网页还是保存你的数码照片。随着技术的发展,字节的作用仍然至关重要,并延伸到了人工智能、大数据和区块链等领域,在这些领域中,大量的数据被处理和操作。通过理解字节是什么以及它们是如何工作的,你就能更好地了解和驾驭你周围的数字环境。
字节(byte)
字节一词是 Werner Buchholz 于 1956 年 6 月在 IBM Stretch 计算机的早期设计阶段发明的。该计算机的寻址为位和可变字段长度(VFL)指令,指令中编码了字节大小。Byte 是从 bite 创造出来的,但为了避免突变为 bit,它被重新拼写为 Byte。
沃纳·布赫霍尔茨(Werner Buchholz,1922-2019)

沃纳·布赫霍尔茨(1922 年 10 月 24 日出生于德国代特莫尔德)是一位著名的美国计算机科学家。作为国际商业机器公司(IBM)设计 IBM 701 和 IBM 7030 Stretch(IBM 第一台晶体管超级计算机)团队的成员,他的工作为计算系统字符编码领域制定了标准。
- 1957–1958 IRE 电子计算机专业组主席
- 1990 年获计算机先锋奖
字节定义的历史演化
早期字节概念
字节是一种数字信息单位,用于描述一组有序的位,是计算机可以处理的最小数据量(比特)。从历史的观点上,“字节” 表示用于编码单个字符所需要的比特数量,因此它是许多计算机体系结构中最小的可寻址内存单元。历史上字节长度曾基于硬件为 1-48 bit 不等,最初通常使用 6 bit 或 9 bit 为一字节。
8 位字节的标准化
今日标准以 8 bit 作为一字节。为了消除常见 8 位定义中任意大小的字节的歧义, 8 个比特在一些规范(例如工业标准、计算机网络、电信技术等)中常被称为 8 位组(octet)。Internet 协议(RFC 791)将 8 位字节称为 8 位字节。国际电工委员会(IEC)和电气与电子工程师协会(IEEE)将字节的单位符号指定为大写字母 B。例如 MB 表示兆字节(megabyte);比特(bit)可缩写成 b,例如 Mb 表示兆比特(megabit),与字节进行区分。
国际上,单位 8 位字节(octet,符号 o)明确定义了 8 位的序列,消除了术语 “字节” 的潜在歧义。ISO/IEC 2382-1:1993 中记录的现代事实上的标准(8 位)是相对方便的 2 的幂,因为 2 的 8 次方是 256,允许一个字节使用 0 到 255 的二进制编码值。国际标准 IEC 80000-13 定义了这一常见含义。
在计算机领域中,一个 octet 是指以 8 个比特(bit)为一组的单位,其中文名称为 8 字节。
在计算机网络和数据传输中,“octet-stream” 是一个常见的术语,用于描述由八位字节组成的连续数据流,这些字节可以表示任何类型的数据,如文本、图像、音频、视频等未经解释的、原始的任意类型的二进制数据流。
- 定义:
- Octet:一个八位字节(8 bits),是计算机中数据的基本单位。
- Stream:表示数据的连续流动,通常是一个字节接一个字节的序列。
- 应用场景:
- 在网络协议中,如 HTTP、FTP 等,当需要传输未经过特殊编码的原始数据时,通常会使用“octet-stream”来描述这种数据流。
- 例如,在 HTTP 协议中,当服务器返回一个文件时,如果文件的内容类型未知或需要以原始二进制形式传输,服务器会将
Content-Type设置为application/octet-stream。- 特点:
- 通用性:由于“octet-stream”不指定数据的具体格式,因此它可以用于传输任何类型的数据。
- 灵活性:接收方可以根据需要对这些字节进行进一步的处理或解释,例如解码为特定格式的数据。
在法国和罗马尼亚,“octet” 这个词通常表示一个字节(byte)的含义;当我们提及一兆字节(megabyte,MB)时,在这些地区会将其称作 “megaoctet”。“bit” 和 “byte” 在法语中是异义同音字。
在某些早期计算机系统中,字节(byte)的长度并不是 8 位,而是其他长度,例如 6 位、7 位或 9 位。例如,早期的一些计算机系统(如 DEC-10)使用的是 10 位的字节,这与现代标准的 8 位字节不同。
为了避免这种混淆,特别是在网络协议和数据传输中,倾向于使用 “Octet” 来明确表示一个 8 位的字节。因此,除了上述提到的唯一例外情况之外,“Octet” 通常指一个具有 8 个比特的实体。
字节的多种表示
单位前缀
8 位字节可以与国际电工委员会(IEC)在 1998 年标准化的二进制前缀(2 的幂前缀)或 SI 前缀一起使用。
| 二进制前缀 | 单位 | 2 的幂 | 字节数 |
|---|---|---|---|
| kibi | Kio | 2 10 2^{10} 210 | 1,024 |
| mebi | Mio | 2 20 2^{20} 220 | 1,048,576 |
| gibi | Gio | 2 30 2^{30} 230 | 1,073,741,824 |
| tebi | Tio | 2 40 2^{40} 240 | 1,099,511,627,776 |
| pebi | Pio | 2 50 2^{50} 250 | 1,125,899,906,842,624 |
| exbi | Eio | 2 60 2^{60} 260 | 1,152,921,504,606,846,976 |
| zebi | Zio | 2 70 2^{70} 270 | 1,180,591,620,717,411,303,424 |
| yobi | Yio | 2 80 2^{80} 280 | 1,208,925,819,614,629,174,706,176 |
SI 前缀(如 kilo、mega、giga、tera 等)与所有 SI 单位相同,基于 10 的幂。在这种情况下:
| SI 前缀 | 单位 | 10 的幂 | 字节数 |
|---|---|---|---|
| kilo | ko | 1 0 3 10^{3} 103 | 1,000 |
| mega | Mo | 1 0 6 10^{6} 106 | 1,000,000 |
| giga | Go | 1 0 9 10^{9} 109 | 1,000,000,000 |
| tera | To | 1 0 12 10^{12} 1012 | 1,000,000,000,000 |
| peta | Po | 1 0 15 10^{15} 1015 | 1,000,000,000,000,000 |
| exa | Eo | 1 0 18 10^{18} 1018 | 1,000,000,000,000,000,000 |
| zetta | Zo | 1 0 21 10^{21} 1021 | 1,000,000,000,000,000,000,000 |
| yotta | Yo | 1 0 24 10^{24} 1024 | 1,000,000,000,000,000,000,000,000 |
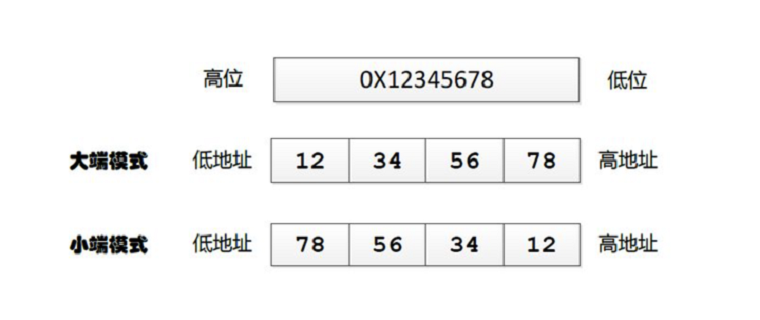
字节序
字节序(Endianness),也称为端序或字节顺序,是指多字节数据在计算机内存中存储或网络传输时各字节的顺序。字节序主要有两种类型:大端字节序(Big-endian)和小端字节序(Little-endian)。
大端字节序
在这种字节序中,高位字节存储在内存的低地址处,而低位字节存储在内存的高地址处。大端字节序接近于数字从左到右的书写方式。TCP/IP 协议规定在网络传输中使用大端字节序,因此大端字节序是网络传输中主要使用的顺序。使用大端字节序的处理器包含 Motorola 6800、Motorola 68000、PowerPC 970、System/370 等。
小端字节序
在这种字节序中,低位字节存储在内存的低地址处,而高位字节存储在内存的高地址处。小端字节序是多数处理器架构及其相关内存主要使用的顺序。使用小端字节序的处理器包含 x86、MOS Technology 6502、Z80、VAX、PDP-11、RISC-V 等。
字节在计算机技术中的应用
数据存储
字节在数据存储中起重要作用。存储设备(例如硬盘、SSD、USB 驱动器)的容量通常以字节为单位。在计算机内存中,每个字节都有一个唯一的地址,每个字节可以存储一个字符。
数据传输
在网络传输中,计算机和网络设备通常以字节为单位来处理和传输数据。网络协议,如 TCP/IP,定义了如何将数据分割成字节流,并通过网络传输到目的地。在传输过程中,字节也可以被用来检查数据完整性。例如,校验和算法会计算数据包中字节的和,并在接收端进行验证,以确保数据在传输过程中没有被篡改或损坏。
数据处理
在计算机中,字节是数据处理的基本单位。计算机的 CPU 按照字节来读取和写入数据,执行计算和处理指令。除了字节,CPU 还可以对更大的数据单元进行操作,例如字、双字等,这些数据单元通常由多个字节组成,可以表示更大范围的数据。CPU 通过对这些数据单元的操作,实现对更复杂的数据结构和算法的支持。
字符编码
字符编码是一种将字符映射到字节序列的规则,以便在计算机系统中存储、处理和传输文本数据。常用的字符编码方式有:
ASCII 编码
ASCII(美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语用于电子通信。ASCII 码使用单个字节(8 位)来表示每个字符,但实际上只使用了低 7 位,因此总共可以表示 128 个不同的字符。它包括大写和小写字母、数字、标点符号、控制字符和一些特殊符号。
Unicode 编码
Unicode 是一种字符集编码标准,旨在支持全球所有语言的字符。它为每种语言中的每个字符分配了一个唯一的编码,从而使得不同语言之间的文本处理和交换变得可能。Unicode 提供了多种不同的编码方式:
- UTF-8:一种可变长度的编码方式,使用 1 到 4 个字节来表示一个字符。
- UTF-16:使用 2 个或 4 个字节来表示一个字符。
- UTF-32:使用固定 4 个字节来表示一个字符,可以表示 Unicode 中的所有字符。
GB2312 编码
GB2312 是中华人民共和国国家标准汉字信息交换用编码,全称《信息交换用汉字编码字符集 — 基本集》,由国家标准总局发布,1981 年 5 月 1 日实施。它是中国大陆地区较早的汉字编码标准之一,对汉字的编码和传输起到了重要作用。GB2312 使用两个字节来表示一个汉字,每个字节的高位都是 1,这样就可以与 ASCII 码区分开来。因为 ASCII 码的最高位是 0。GB2312 包含 6763 个常用汉字和 682 个非汉字图形符号。
字节在网络中的应用
8 位字节用于表示 Internet 协议计算机网络地址。
- IPv4 地址:由四个 8 位字节组成,通常分别显示为一系列十进制值,范围从 0 到 255,每个十进制值之间用句号(点)分隔。使用设置了所有 8 位的 8 位字节,最高编号的 IPv4 地址的表示形式为 255.255.255.255。
- IPv6 地址:由 16 个 8 位字节组成,使用十六进制表示(每个 8 位字节两位数字)和冒号字符
(:)在每对 8 位字节后显示,以便于阅读,如 FE80:0000:0000:0000:0123:4567:89AB:CDEF。如果一对或多个连续 8 位字节等于零,则可以将其替换为以下两个冒号字符(::),但这只能在给定的 IPv6 地址中使用一次,以避免歧义。因此,先前给出的 IPv6 地址也可以写为 FE80::0123:4567:89AB:CDEF。
字节在计算机存储单元中的使用
zhongrg 于 2007-11-07 12:19:00 发布
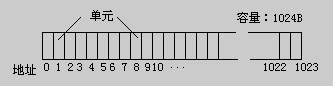
数据必须首先在计算机内被表示,然后才能被计算机处理。计算机表示数据的部件主要是存储设备;而存储数据的具体单位是存储单元;因此,了解存储单元的结构是十分必要的。
1、“位”(Bit)
计算机中最小的信息单位。1 “位” 只能表示 0 和 1 中的一个,即 1 个二进制位,或存储1 个二进制数位的单位。
2、“字节”(Byte)
由相连 8 个位组成的信息存储单位。

字节是目前计算机最基本的存储单位;也是计算机存储设备容量最基本的计量单位。
一个字节通常可以存储一个字符(如字母、数字等)。只有字节才有地址的概念。
对一种计算机的存储设备以字节为单位赋予的地址称为字节编址,也是目前计算机最基本的存储单元编址。
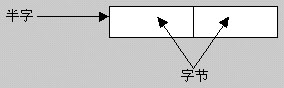
3、 “半字”(Half Word)
由相连两个字节(即 16 位)构成的信息存储单位。
半字的地址是组成字的第一个字节的地址除 2;因此该字节的地址必须能被 2 整除。
如下图
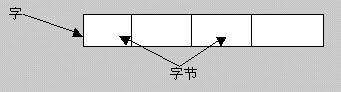
4、“字”(Word)
由相连4个字节(即32位)构成的信息存储单位。
字的地址是组成字的第一个字节的地址除4;因此该字节的地址必须能被4整除。
如下图
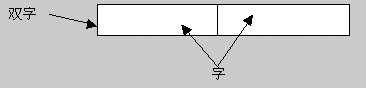
5、“双字”(Double Word)
由相连 2 个字(即 64 位)构成的信息存储单位。
双字的地址是组成双字的第一个字节的地址除 8;因此该字节的地址必须能被 8 整除。
如下图
via:
-
What is Byte and How Does it Work? - UMA Technology
https://umatechnology.org/what-is-byte-and-how-does-it-work/ -
八比特 - 维基百科,自由的百科全书
https://zh.wikipedia.org/wiki/八位元 -
什么是计算机的存储单元?_计算机存储单元-CSDN博客 zhongrg 于 2007-11-07 12:19:00 发布
https://blog.csdn.net/zhongrg/article/details/1871350 -
application/octet-stream,http服务器设置响应头让浏览器下载内容_动态设置content-type-CSDN博客
https://blog.csdn.net/xiaomogg/article/details/130829971

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









