







学术头条
撰文|马雪薇
编审|佩奇
前言
当前,在愈发火热的大模型行业,Scaling Law 被证明依然奏效。
问题是,一旦由人类生成的高质量数据(如书籍、文章、照片、视频等)用尽,大模型训练又该如何进行?
目前,一个被寄予厚望的方法是 “用大模型自己生成的数据来训练自己”。事实上,如果后代模型的训练数据也从网络中获取,就会不可避免地使用前代模型生成的数据**。**
然而,来自牛津大学和剑桥大学的研究团队及其合作者,却给这一设想 “泼了一盆冷水”。
他们给出了这样一个结论:模型在训练中使用自身生成的内容,会出现不可逆转的缺陷,逐渐忘记真实数据分布,从而导致模型性能下降。
即 “模型崩溃”(Model Collapse)。
相关研究论文以 “AI models collapse when trained on recursively generated data” 为题,已发表在权威科学期刊 Nature 上。

但他们也表示,用一个旧模型生成的数据去训练一个新模型,并非不可行,但必须对数据进行严格的过滤。
在一篇同期发表的新闻与观点文章中,来自杜克大学的 Emily Wenger 认为,“论文作者没有考虑模型在由其他模型生成的数据上训练时会发生什么,他们专注于模型在自身输出上训练的结果。一个模型在训练其他模型的输出时是否会崩溃还有待观察。因此,下一个挑战将是要搞清楚模型崩溃发生的机制。”
什么是模型崩溃?
本质上,当大模型生成的数据最终污染了后续模型的训练集时,就会发生 “模型崩溃”。
像 GMM 和 VAE 这样的小型模型通常是从头开始训练的,而 LLM 重新训练的成本非常高,因此通常使用如 BERT4、RoBERTa5 或 GPT-2 这样在大型文本语料库上预训练的模型进行初始化,然后针对各种下游任务进行微调。
那么当语言模型依次使用其他模型生成的数据进行微调时会发生什么?
为此,研究团队使用 OPT-125m 语言模型进行实验,并使用 wikitext2 数据集进行微调。**实验结果表明,无论是否保留原始数据,模型崩溃现象都发生了。**随着迭代次数的增加,模型生成的样本中低困惑度样本的数量开始积累,表明模型开始忘记真实数据分布中的尾部事件。并且,与原始模型相比,后续迭代模型的性能有所下降,表现为困惑度增加。此外,模型生成的数据中包含大量重复的短语。

图 | 受模型崩溃影响的 OPT-125m 模型的文本输出示例 - 模型在几代之间退化。
想象一下一个生成 AI 模型负责生成狗的图像。AI 模型会倾向于重现训练数据中最常见的狗的品种,因此可能会过多地呈现金毛,而非法斗。如果随后的模型在一个 AI 生成的数据集中进行训练,而这个数据集中过多地呈现了金毛,这个问题就会加剧。经过足够多轮次的过多呈现金毛后,模型将忘记诸如法斗这样的冷门品种的存在,只生成金毛的图像。最终,模型将崩溃,无法生成有意义的内容。
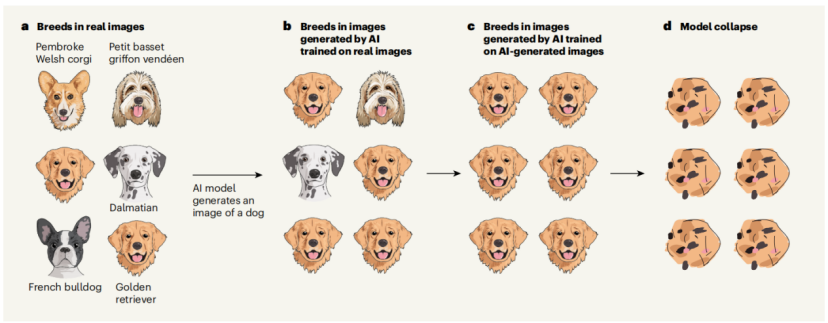
图 | 模型会逐渐忽视训练数据中不常见的元素。
总而言之,模型会逐渐忘记真实语言中出现的低概率事件,例如罕见词汇或短语。这会导致模型生成的内容缺乏多样性,并无法正确地模拟真实世界的复杂性。并且,模型会逐渐生成与真实世界不符的内容,例如错误的日期、地点或事件。这会导致模型生成的内容失去可信度,并无法用于可靠的信息检索或知识问答等任务。此外,模型会逐渐学习到训练数据中的偏见和歧视,并将其反映在生成的内容中。
为何会发生?
模型崩溃是一个退化过程,模型生成的内容会污染下一代的训练数据,导致模型逐渐失去对真实数据分布的记忆。模型崩溃分为早期和晚期两种情况:在早期阶段,模型开始失去对低概率事件的信息;到了晚期阶段,模型收敛到一个与原始分布差异很大的分布,通常方差显著减小。
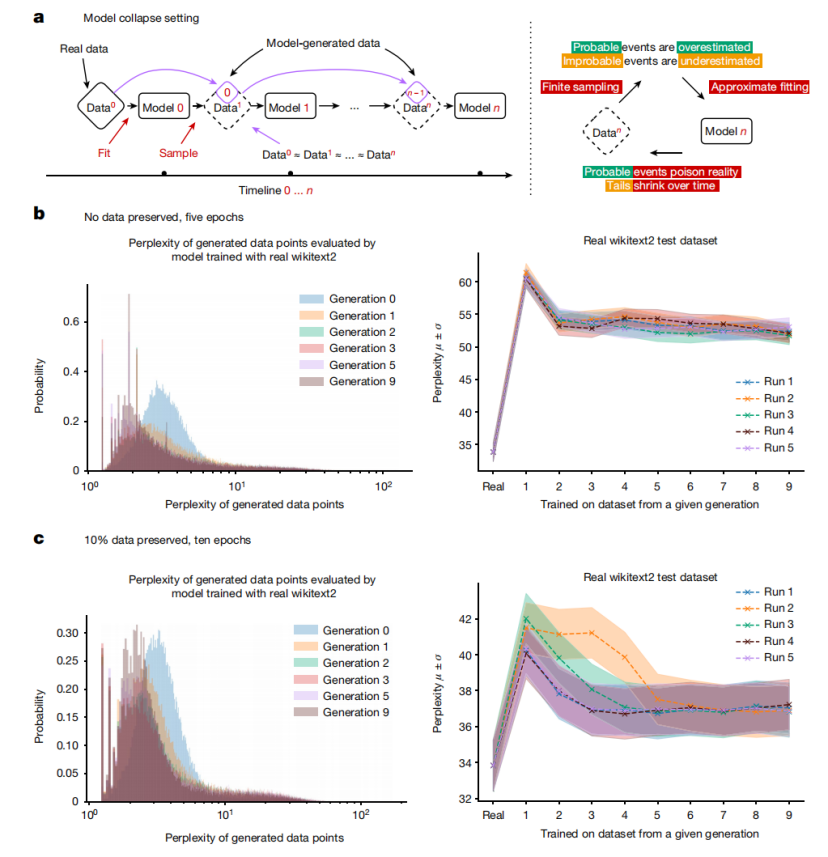
图 | 对学习过程中反馈机制的高层次描述。
随着代数的增加,模型倾向于生成由最初模型更可能生成的样本。同时,后代模型的样本分布尾部变得更长。后代模型开始生成原始模型绝不会生成的样本,即它们开始基于先前模型引入的错误误解现实。尽管在生成数据上训练的模型能够学习部分原始任务,但也会出现错误,如困惑度增加所示。
模型崩溃主要由三种误差累积导致:
1. 统计近似误差:
- 由于样本数量有限,模型无法完全捕捉到真实数据分布的所有细节。随着时间的推移,低概率事件(即分布的尾部)会逐渐消失,因为它们被采样的概率很低。
- 随着模型训练代数的增加,这种误差会不断累积,导致模型最终收敛到一个与原始分布完全不同的分布,其尾部几乎为零,方差也大大减小。
2. 函数表达能力误差:
- 神经网络等函数近似器的表达能力是有限的,无法完美地逼近任何分布。
- 这种误差会导致模型在逼近真实分布时产生偏差,例如,将高密度区域分配到低密度区域,或者将低密度区域分配到高密度区域。
- 随着模型训练代数的增加,这种误差会不断累积,导致模型最终收敛到一个与原始分布完全不同的分布,其尾部几乎为零,方差也大大减小。
3. 函数近似误差:
- 学习过程的局限性,例如随机梯度下降的结构偏差或目标函数的选择,也会导致模型产生误差。
- 这种误差会导致模型在逼近真实分布时产生偏差,例如,过拟合密度模型导致模型错误地外推数据,并将高密度区域分配到训练集支持范围之外的低密度区域。
- 随着模型训练代数的增加,这种误差会不断累积,导致模型最终收敛到一个与原始分布完全不同的分布,其尾部几乎为零,方差也大大减小。
可以避免吗?
研究团队认为,用 AI 生成数据训练一个模型并非不可能,但必须对数据进行严格过滤。
首先,在每一代模型的训练数据中,保留一定比例的原始数据,例如 10% 或 20%。这样可以确保模型始终接触到真实世界的样本,避免完全依赖于模型生成的内容。定期对原始数据进行重采样,并将其添加到训练数据中。这样可以保证训练数据始终保持新鲜,并且能够反映真实世界的最新变化。
其次,可以使用多样化的数据。例如,除了模型生成的内容,还应该使用人类产生的数据作为训练数据。**人类数据更加真实可靠,可以帮助模型更好地理解真实世界的复杂性和多样性。**此外,可以使用其他类型的机器学习模型生成的数据作为训练数据,例如强化学习模型或模拟器。这样可以保证训练数据来源的多样性,并避免过度依赖于单一类型的模型。
最后,可以尝试改进学习算法。研究更鲁棒的语言模型训练算法,例如对抗训练、知识蒸馏或终身学习。这些算法可以帮助模型更好地处理训练数据中的噪声和偏差,并提高模型的泛化能力。
尽管这一警示似乎对当前的生成式 AI 技术以及寻求通过它获利的公司来说都是令人担忧的,但是从中长期来看,或许能让人类内容创作者看到更多希望。
研究人员表示,在充满 AI 工具及其生成内容的未来世界,如果只是作为 AI 原始训练数据的来源,人类创造的内容将比今天更有价值。
via:
-
Nature 最新封面:AI 训练 AI?也许越来越笨 原创 学术头条 2024 年 07 月 25 日 00:16 北京


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









