







还记得 Meta 的「分割一切模型」吗?这个模型在去年 4 月发布,被很多人认为是颠覆传统 CV 任务的研究。
时隔一年多,刚刚,Meta 在 SIGGRAPH 上重磅宣布 Segment Anything Model 2 (SAM 2) 来了。在其前身的基础上,SAM 2 的诞生代表了领域内的一次重大进步 —— 为静态图像和动态视频内容提供实时、可提示的对象分割,将图像和视频分割功能统一到一个强大的系统中。

SAM 2 可以分割任何视频或图像中的任何对象 —— 甚至是它以前没有见过的对象和视觉域,从而支持各种不同的用例,而无需自定义适配。
在与黄仁勋的对话中,扎克伯格提到了 SAM 2:「能够在视频中做到这一点,而且是在零样本的前提下,告诉它你想要什么,这非常酷。」

Meta 多次强调了最新模型 SAM 2 是首个用于实时、可提示的图像和视频对象分割的统一模型,它使视频分割体验发生了重大变化,并可在图像和视频应用程序中无缝使用。SAM 2 在图像分割准确率方面超越了之前的功能,并且实现了比现有工作更好的视频分割性能,同时所需的交互时间为原来的 1/3。
该模型的架构采用创新的流式内存(streaming memory)设计,使其能够按顺序处理视频帧。这种方法使 SAM 2 特别适合实时应用,为各个行业开辟了新的可能性。
当然,处理视频对算力的要求要高得多。SAM 2 仍然是一个庞大的模型,也只有像 Meta 这样的能提供强大硬件的巨头才能运行,但这种进步还是说明了一些问题:一年前,这种快速、灵活的分割几乎是不可能的。SAM 2 可以在不借助数据中心的情况下运行,证明了整个行业在计算效率方面的进步。
模型需要大量的数据来训练,Meta 还发布了一个大型带注释数据库,包括大约 51,000 个真实世界视频和超过 600,000 个 masklets。与现有最大的视频分割数据集相比,其视频数量多 4.5 倍,注释多 53 倍,Meta 根据 CC BY 4.0 许可分享 SA-V。在 SAM 2 的论文中,另一个包含超过 100,000 个「内部可用」视频的数据库也用于训练,但没有公开。
与 SAM 一样,SAM 2 也会开源并免费使用,并在 Amazon SageMaker 等平台上托管。为了履行对开源 AI 的承诺,Meta 使用宽松的 Apache 2.0 协议共享代码和模型权重,并根据 BSD-3 许可分享 SAM 2 评估代码。
目前,Meta 已经提供了一个 Web 的演示体验地址:https://sam2.metademolab.com/demo

基于 web 的 SAM 2 演示预览,它允许分割和跟踪视频中的对象。
正如扎克伯格上周在一封公开信中指出的那样,开源人工智能比任何其他现代技术都更具有潜力,可以提高人类的生产力、创造力和生活质量,同时还能加速经济增长并推动突破性的医学和科学研究。人工智能社区利用 SAM 取得的进展给我们留下了深刻的印象, SAM 2 必将释放更多令人兴奋的可能性。

SAM 2 可立即应用于各种各样的实际用例 - 例如,跟踪对象(左)或分割显微镜捕获的视频中的移动细胞以辅助科学研究(右)。
 未来,SAM 2 可以作为更大型 AI 系统的一部分,通过 AR 眼镜识别日常物品,并向用户提供提醒和说明。
未来,SAM 2 可以作为更大型 AI 系统的一部分,通过 AR 眼镜识别日常物品,并向用户提供提醒和说明。
SAM 2 前脚刚上线,大家就迫不及待的用起来了:「在 Meta 未提供的测试视频上试用 SAM 2。效果好得令人瞠目结舌。」
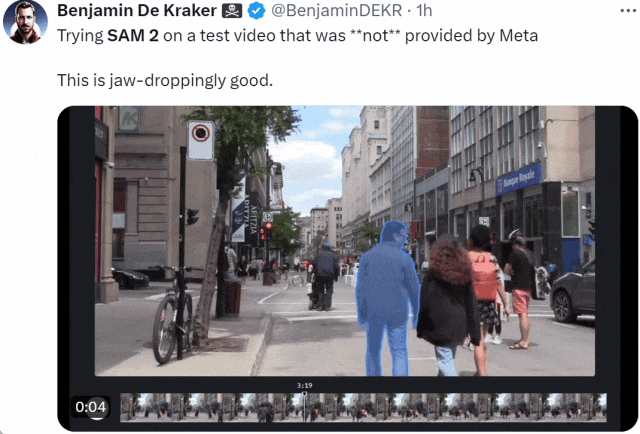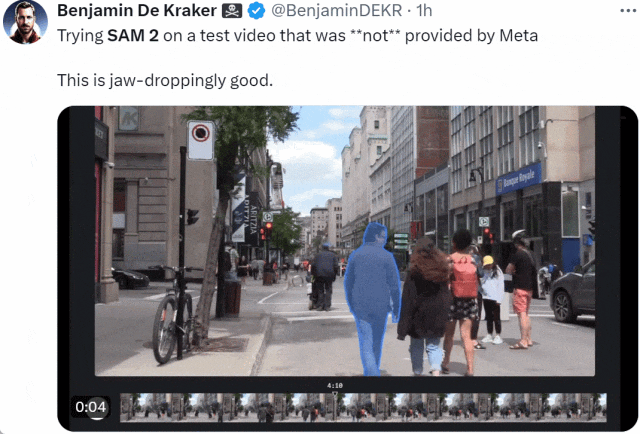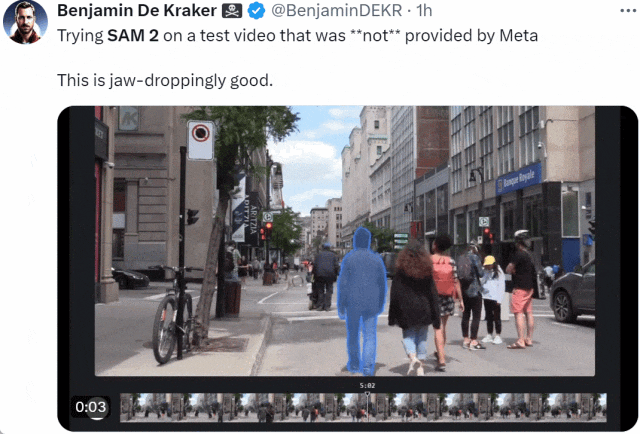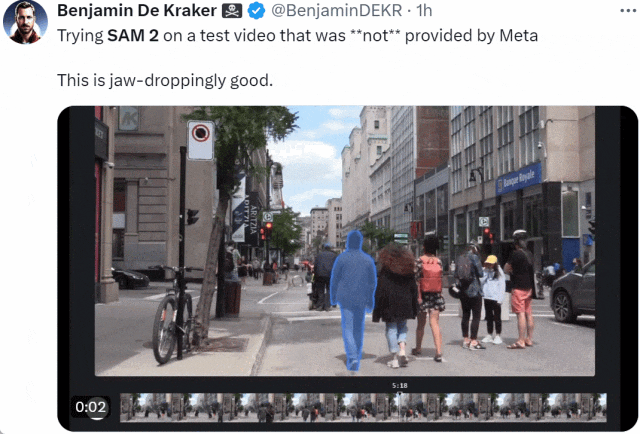
来源:https://x.com/BenjaminDEKR/status/1818066956173664710
还有网友认为,SAM 2 的出现可能会使其他相关技术黯然失色。

如何构建 SAM 2?
SAM 能够了解图像中对象的一般概念。然而,图像只是动态现实世界的静态快照。许多重要的现实用例需要在视频数据中进行准确的对象分割,例如混合现实、机器人、自动驾驶车辆和视频编辑。Meta 认为通用的分割模型应该适用于图像和视频。
图像可以被视为具有单帧的非常短的视频。Meta 基于这个观点开发了一个统一的模型,无缝支持图像和视频输入。处理视频的唯一区别是,模型需要依靠内存来调用该视频之前处理的信息,以便在当前时间步准确地分割对象。
视频中对象的成功分割需要了解实体在空间和时间上的位置。与图像分割相比,视频提出了重大的新挑战。对象运动、变形、遮挡、光照变化和其他因素可能会因帧而异。由于摄像机运动、模糊和分辨率较低,视频的质量通常低于图像,这增加了难度。因此,现有的视频分割模型和数据集在为视频提供可比的「分割任何内容」功能方面存在不足。
Meta 构建 SAM 2 和新 SA-V 数据集来解决这些挑战。
与用于 SAM 的方法类似,Meta 对视频分割功能的研究涉及设计新任务、模型和数据集。
研究团队首先开发了可提示的(promptable)视觉分割任务并设计了一个能够执行该任务的模型 ——SAM 2。
然后,研究团队使用 SAM 2 来帮助创建视频对象分割数据集 ——SA-V,该数据集比当前存在的任何数据集大一个数量级。研究团队使用它来训练 SAM 2 以实现 SOTA 性能。
可提示的视觉分割

SAM 2 支持在任何视频帧中选择和细化对象。
研究团队设计了一个可提示的视觉分割任务,将图像分割任务推广到视频领域。SAM 经过训练,以图像中的输入点、框或掩码来定义目标对象并预测分割掩码。该研究训练 SAM 2 在视频的任何帧中获取输入提示来定义要预测的时空掩码(即「masklet」)。
SAM 2 根据输入提示立即预测当前帧上的掩码,并将其临时传播(temporally propagate)以生成跨所有视频帧的目标对象的 masklet。一旦预测出初始 masklet,就可以通过在任何帧中向 SAM 2 提供附加提示来迭代完善它。这可以根据需要重复多次,直到获得所需的 masklet。
统一架构中的图像和视频分割

从 SAM 到 SAM 2 的架构演变。
SAM 2 架构可以看作是 SAM 从图像领域到视频领域的推广。
SAM 2 可以通过点击、边界框或掩码被提示,以定义给定帧中对象的范围。轻量级掩码解码器采用当前帧的图像嵌入和编码提示来输出该帧的分割掩码。在视频设置中,SAM 2 将此掩码预测传播到所有视频帧以生成 masklet,然后在任何后续帧上迭代添加提示以细化 masklet 预测。
为了准确预测所有视频帧的掩码,研究团队引入了一种由记忆编码器、记忆库(memory bank)和记忆注意力模块组成的记忆机制。当应用于图像时,内存组件为空,模型的行为类似于 SAM。对于视频,记忆组件能够存储关于该会话中的对象和先前用户交互的信息,从而允许 SAM 2 在整个视频中生成 masklet 预测。如果在其他帧上提供了额外的提示,SAM 2 可以根据对象存储的记忆上下文有效地纠正其预测。
帧的记忆由记忆编码器根据当前掩码预测创建,并放置在记忆库中以用于分割后续帧。记忆库由先前帧和提示帧的记忆组成。记忆注意力操作从图像编码器获取每帧嵌入,并根据记忆库进行调整以产生嵌入,然后将其传递到掩码解码器以生成该帧的掩码预测。对于所有后续帧重复此操作。
Meta 采用流式架构,这是 SAM 在视频领域的自然推广,一次处理一个视频帧并将有关分割对象的信息存储在记忆中。在每个新处理的帧上,SAM 2 使用记忆注意力模块来关注目标对象之前的记忆。这种设计允许实时处理任意长的视频,这不仅对于 SA-V 数据集的注释收集效率很重要,而且对于现实世界的应用(例如在机器人领域)也很重要。
当图像中被分割的对象存在模糊性时,SAM 会输出多个有效掩码。例如,当一个人点击自行车轮胎时,模型可以将这次点击解释为仅指轮胎或整个自行车,并输出多个预测。在视频中,这种模糊性可能会扩展到视频帧中。例如,如果在一帧中只有轮胎可见,则轮胎上的点击可能仅与轮胎相关,或者随着自行车的更多部分在后续帧中变得可见,这种点击可能是针对整个自行车的。为了处理这种模糊性,SAM 2 在视频的每个步骤创建多个掩码。如果进一步的提示不能解决歧义,模型会选择置信度最高的掩码,以便在视频中进一步传播。

SAM 2 架构中的遮挡 head 用于预测对象是否可见,即使对象暂时被遮挡,也能帮助分割对象。
在图像分割任务中,在给定积极提示的情况下,帧中始终存在可分割的有效对象。在视频中,特定帧上可能不存在有效对象,例如由于对象被遮挡或从视图中消失。为了解释这种新的输出模式,研究团队添加了一个额外的模型输出(「遮挡 head(occlusion head)」),用于预测当前帧中是否存在感兴趣的对象。这使得 SAM 2 能够有效地处理遮挡。
SA-V:Meta 构建了最大的视频分割数据集
来自 SA-V 数据集的视频和掩码注释。
为了收集一个大型且多样化的视频分割数据集,Meta 建立了一个数据引擎,其中注释员使用 SAM 2 交互地在视频中注释 masklet,然后将新注释的数据用于更新 SAM 2。他们多次重复这一循环,以迭代地改进模型和数据集。与 SAM 类似,Meta 不对注释的 masklet 施加语义约束,注重的是完整的物体(如人)和物体的部分(如人的帽子)。
借助 SAM 2,收集新的视频对象分割掩码比以往更快,比每帧使用 SAM 快约 8.4 倍。此外,Meta 发布的 SA-V 数据集的注释数量是现有视频对象分割数据集的十倍以上,视频数量大约是其 4.5 倍。
总结而言,SA-V 数据集的亮点包括:
- 在大约 51,000 个视频中有超过 600,000 个 masklet 注释;
- 视频展示了地理上不同的真实场景,收集自 47 个国家;
- 覆盖整个对象、对象中的一部分,以及在物体被遮挡、消失和重新出现的情况下具有挑战性的实例。
结果
下方两个模型都是用第一帧中的 T 恤蒙版初始化的。对于 baseline,Meta 使用来自 SAM 的蒙版,问题是过度分割并包括人的头部,而不是仅跟踪 T 恤。相比之下,SAM 2 能够在整个视频中准确跟踪对象部分。

为了创建统一的图像和视频分割模型,Meta 将图像视为单帧视频,在图像和视频数据上联合训练 SAM 2。团队利用了去年作为 Segment Anything 项目的一部分发布的 SA-1B 图像数据集、SA-V 数据集以及额外的内部许可视频数据集。

SAM 2(右)提高了 SAM(左)图像中的对象分割精度。
SAM 2 论文也展示了该模型的多项提升:
1、SAM 2 在 17 个零样本视频数据集的交互式视频分割方面表现明显优于以前的方法,并且所需的人机交互减少了大约三倍。

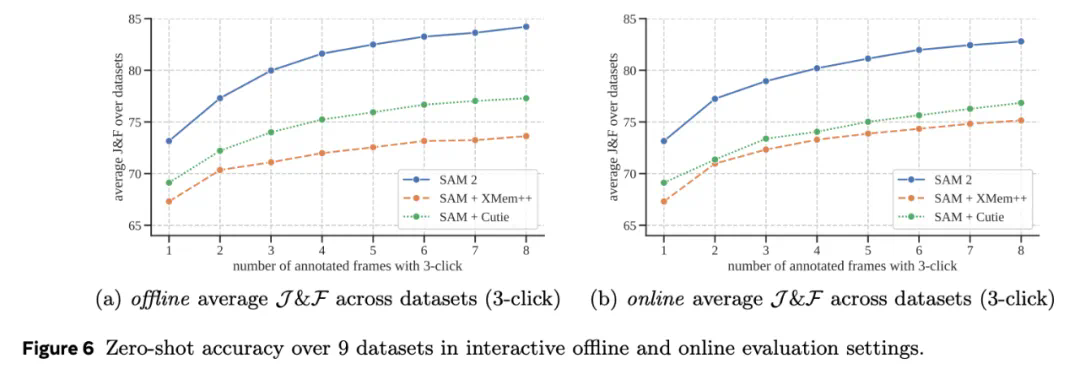
2、SAM 2 在 23 个数据集零样本基准测试套件上的表现优于 SAM,而且速度快了六倍。

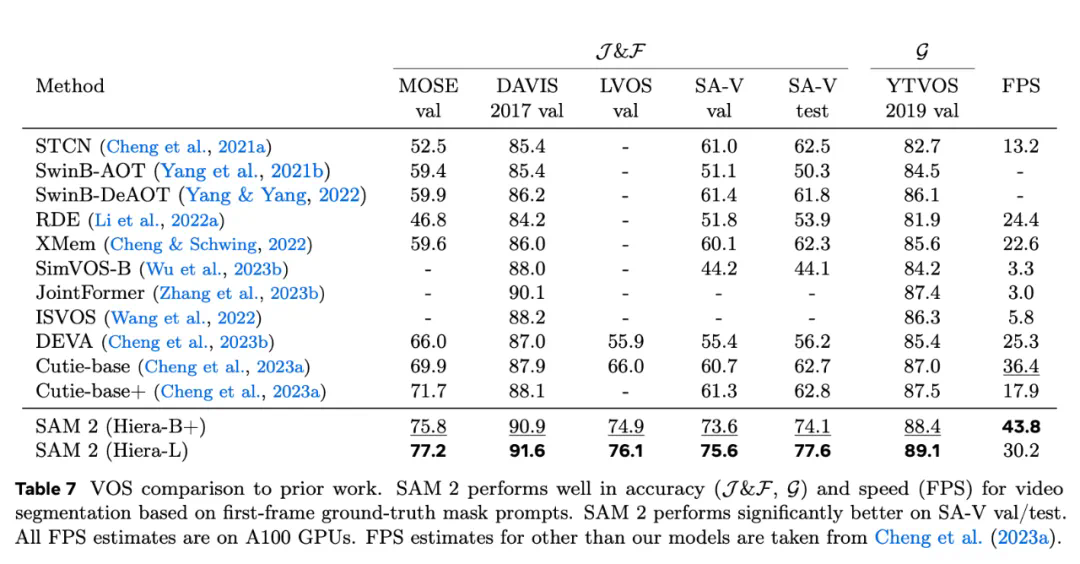
3、与之前的最先进模型相比,SAM 2 在现有的视频对象分割基准(DAVIS、MOSE、LVOS、YouTube-VOS)上表现出色。
4、使用 SAM 2 进行推理感觉很实时,速度大约为每秒 44 帧。
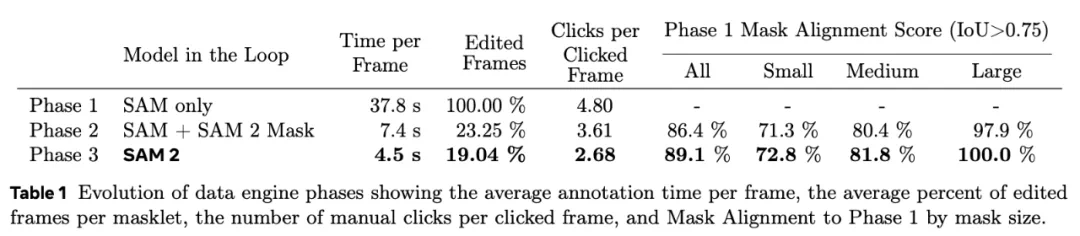
5、循环中使用 SAM 2 进行视频分割注释的速度比使用 SAM 进行手动每帧注释快 8.4 倍。
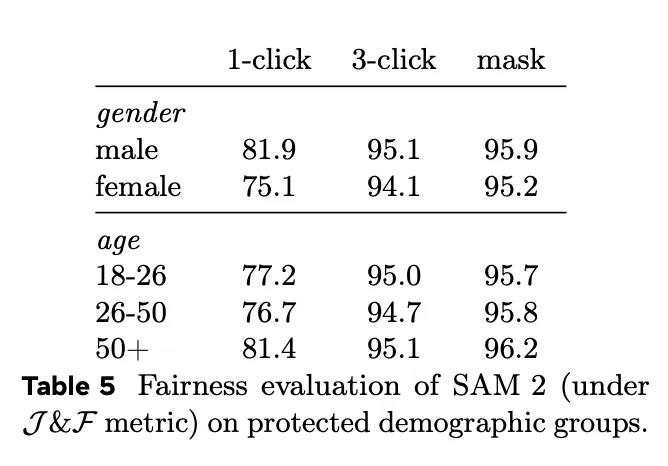
6、为了衡量 SAM 2 的公平性,Meta 对特定人群的模型性能进行了评估。结果表明,在感知性别和 18-25 岁、26-50 岁和 50 岁以上三个感知年龄组评估中,模型显示的差异很小。
更多结果,请查看论文。
局限性
虽然 SAM 2 在分割图像和短视频中的对象方面表现出色,但仍然会遇到诸多挑战。
SAM 2 可能会在摄像机视角发生剧烈变化、长时间遮挡、拥挤的场景或较长的视频中失去对对象的追踪。
在实际应用中,Meta 设计了交互式模型来缓解这一问题,并通过在任意帧中点击校正来实现人工干预,从而恢复目标对象。

在拥挤的场景中,SAM 2 有时会混淆多个外观相似的对象。
当目标对象只在一帧中指定时,SAM 2 有时会混淆对象,无法正确分割目标,如上述视频中的马匹所示。在许多情况下,通过在未来帧中进行额外的细化提示,这一问题可以完全解决,并在整个视频中获得正确的 masklet。
虽然 SAM 2 支持同时分割多个单独对象的功能,但模型的效率却大大降低。实际上,SAM 2 对每个对象进行单独处理,只利用共享的每帧嵌入,不进行对象间通信。虽然这简化了模型,但纳入共享的对象级上下文信息有助于提高效率。

SAM 2 的预测可能会错过快速移动对象的细节。
对于复杂的快速运动对象,SAM 2 有时会漏掉一些细节,而且预测结果在帧之间可能不稳定,如上文骑自行车者的视频所示。
在同一帧或其他帧中添加进一步的提示来优化预测只能部分缓解此问题。在训练过程中,如果模型预测在帧间抖动,不会对其进行任何惩罚,因此无法保证时间上的平滑性。提高这种能力可以促进需要对精细结构进行详细定位的实际应用。
虽然 Meta 的数据引擎在循环中使用了 SAM 2,且在自动 masklet 生成方面也取得了长足进步,但仍然依赖人工注释来完成一些步骤,例如验证 masklet 质量和选择需要校正的帧。
因此,未来的发展需要进一步自动化这个数据注释过程,以提高效率。要推动这项研究,还有很多工作要做。
参考链接:
https://ai.meta.com/blog/segment-anything-2-video/
via:
-
刚刚,Meta开源「分割一切」2.0模型,视频也能分割了 | 机器之心 机器之心原创 2024/07/30 11:38















 882
882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









