







注:本文为 “Context” 相关文章合辑。
中文引文,略作重排。
英文引文,机翻未校。
如有内容异常,请看原文。
揭秘 Context(上下文)
醒不了的星期八于 2019 - 03 - 08 00:03:13 发布
最熟悉的陌生人 ——Context
刚刚学习 Android 或者 JavaScript 等时,都会频繁看到 “Context” 这个字眼,其意为 “上下文” 。
本文主要探讨 Context 到底是什么、如何理解它、一个 APP 可以有几个 Context、Context 能干什么、Context 的作用域、如何获取 Context 以及全局获取 Context 的技巧 。
思考
在 Java 中,万物皆对象;在 Flutter 中,万物皆组件 。
有俗语说:“没对象吗?自己 new 一个啊~”
既然大多数情况下可以 new 一个实例,那么在 Android 中的 Activity 实例该如何获取呢?通过 Activity.instance 可以获取 activity 。既然 Activity 大致也归属于一个类,那么可不可以用 Activity activity = new Activity (); 呢?安卓并不像 Java 程序一样,随便创建一个类,写个 main() 方法就能运行。Android 应用模型是基于组件的应用设计模式,组件的运行要有一个完整的 Android 工程环境 。在这个环境下,Activity、Service 等系统组件才能正常工作,而这些组件不能采用普通的 Java 对象创建方式,仅仅 new 一下是不能创建实例的,而是要有它们各自的上下文环境,也就是 Context 。
所以说,Context 是维持 Android 各组件能够正常工作的一个核心功能类 。
what’s Context
(本图为沙拉查词给出的中文翻译)

这有些晦涩难懂。但在程序中,我们可将其理解为当前对象在程序中所处的一个环境,一个与系统交互的过程 。比如使用 QQ 和女朋友聊天时(没有女朋友的可跳过此举例),此时的 context 是指聊天界面以及相关的数据请求与传输,Context 在加载资源、启动 Activity、获取系统服务、创建 View 等操作中都要参与 。
所以,一个 Activity 就是一个 Context(getActivity () == getContext),一个 Service 也是一个 Context 。Android 把场景抽象为 Context 类,用户和操作系统的每一次交互都是一个场景,比如打电话、发短信等,都有 activity,还有一些我们肉眼看不见的后台服务。一个应用程序可以认为是一个工作环境,用户在这个环境中切换到不同的场景,这就像服务员,客户可能是外卖小哥、也可能是农民工等,这些就是不同的场景,而服务员就是一个应用程序。
How to understand the ‘Context’
将 Context 理解为 “上下文”/“场景”,可能还是很抽象。那么我们可以做一个比喻:
一个 APP 就如同仙剑奇侠传 3 电视剧,Activity、Service、BroadcastReceiver、ContentProvider 这四大组件就是电视剧的主角。它们是导演(系统)一开始就确定好试镜成功的人。换言之,不是我们每个人都能被导演认可的。有了演员,就要有镜头,这个镜头便是 Context 。通过镜头,我们才能看见帅气的胡歌。演员们都是在镜头(Context 环境)下表演的。那么 Button 这些组件子类型就是配角,它们没有那么重要,随便一个组件都能参与演出(即随便 new 一个实例),但是它们也需要参与镜头,不然一部戏只有主角多没意思,魔尊重楼还是要的,魔尊也要露面(工作在 Context 环境下),所以可以用代码 new Button ();或者通过 xml 布局定义一个 button 。
打开 AndroidStudio,输入 Context,然后 ctrl + 鼠标左键 追溯其源码(看源码一般都先看注释便于理解):import android.content.Context;

看注释,全是英文,那么笔者这里就用小学生英语水平来翻译一下:
Context 提供了关于应用环境全局信息的接口。它是一个抽象类,它的执行由 Android 系统提供,允许获取以应用为特征的资源和类型,是一个统领一些资源 APP 环境变量等的上下文。通过它可以获取应用程序的资源和类(包括应用级别操作,如启动 Activity,发广播,接收 intent 等)。抽象类会有它的实现类。在源码中,我们可以通过 AndroidStudio 去查看它的子类,得到以下关系:
它有 2 个具体实现子类:ContextImpl、ContextWrapper 。
- 其中,ContextWrapper 类,只是一个包装类,其构造函数中必须包含一个 Context 引用,同时它提供了
attachBaseContext ()用于给 ContextWrapper 对象中指定真正的 Context 对象,调用它的方法都会被转向其所包含的真正的 Context 对象。 - ContextThemeWrapper 类其内部包含了与主题相关的接口。主题就是清单文件中
android:theme为 Application 或 Activity 元素指定的主题。(Activity 才需要主题,Service 不需要,因为服务是没有界面的后台场景,所以服务直接继承 ContextWrapper。Application 同理。)而 Contextlmpl 类则是真正实现了 Context 中的所有函数,应用程序中所调用的各种 Context 类的方法,其实现均来自这个类。 - 换言之:Context 的 2 个实现子类是分工的,其中 ContextImpl 是 Context 的具体实现类,而 ContextWrapper 则是 Context 的包装类。Activity、Application、Service 都继承自 ContextWrapper(Activity 继承自 ContextWrapper 的子类 ContextThemeWrapper),但它们的初始化过程中都会创建 ContextImpl 对象,由 ContextImpl 实现 Context 中的方法。
How much has Context in a App
关键在于对 Context 的理解。从上面提到的实现子类可以看出,在 APP 中,Context 的具体实现子类是 Activity、Service、Applicaiton 。所以 Context’s number = Activity’s number + Service’s number + 1(1 个 APP 只有一个 Application)。为啥不是 4 大组件,上面不是说四大组件也是主角吗?看看 BroadcastReceiver 和 ContentProvider 的源码可以知道它们并不是 Context 的子类,它们持有的 Context 都是其他地方传递过去的(比如我们发送广播 intent 中的 context 就是外部传递过来的),所以不计数它们。
Context’s method
Context 哪里会用到它呢?刚开始了解 Android 的时候不知道它是个啥玩意儿,但是久了发现有些地方就不得不传这个参数。
比如 Toast、启动 Activity、启动 Service、发送广播、操作数据库等等都需要传 Context 参数,具体例子就不说了。详细可以看后文将提到的如何获取它。
Context’s 作用域
不是随便获取一个 Context 实例就可以的,它的使用有一些规则和限制。因为 Context 的具体实例是由 ContextImpl 类去实现的,因此,Activity、Service、Application3 种类型的 Context 都是等价的。但是,需要注意的是,有些场景,比如启动 Activity、弹出 Dialog 等。为了安全,Android 不允许 Activity 或者 Dialog 凭空出现,一个 Activity 的启动肯定是由另一个 Activity 负责的,也就是以此形成的返回栈(具体可以看看任主席的《Android 开发艺术探索》)而 Dialog 则必须是在一个 Activity 上弹出(系统 Alert 类型的 Dialog 除外),这种情况下,我们只能用 Activity 类型的 Context,否则报错。
| Context 作用域 | Application | Activity | Service |
|---|---|---|---|
| Show a Dialog | No | Yes | No |
| Start an Activity | 不推荐 | Yes | 不推荐 |
| Layout Inflation | 不推荐 | Yes | 不推荐 |
| Start a Service | Yes | Yes | Yes |
| Send a Broadcast | Yes | Yes | Yes |
| Register Broadcast Receiver | Yes | Yes | Yes |
| Load Resource Values | Yes | Yes | Yes |
Activity 继承自 ContextThemeWrapper,而 Application 和 Service 继承 ContextWrapper,所以 ContextThemeWrapper 在 ContextWrapper 的基础上作了一些操作,使得 Activity 更具特性。
关于表格中提到的 Application 和 Service 不推荐的 2 种情况:
- 如果用 ApplicationContext 去启动一个 LaunchMode 为 standard 的 Activity 的时候会报错:
androud,util.AndroidRuntimeException:Calling startActivity from outside of an Activity context require the FLAG_ACTIVITY_NEW_TASK flag。Is this really what you want?
翻译一下,并了解这个 FLAG 的都知道,此时的非 Activity 类型的 Context 并没有所谓的返回栈,因此待启动的 Activity 就找不到栈。它还给我们明确指出了 FLAG 的解决办法,这样启动的时候就为它创建一个新的任务栈,而此时 Activity 是以 Single Task 模式启动的。所以这种用 Application Context 启动 Activity 的方式不推荐,Service 同理。 - 在 Application 和 Service 中去 layout inflate 也是合法的,但是会使用系统默认的主题样式,如果自定义了某些样式可能不会被使用,所以也不推荐。
注:和 UI 相关的,都应该使用 Activity Context 来处理。其他的一些操作,Service、Activity、Application 等实例都是可以的。同时要注意 Context 的引用持有,防止内存泄漏。可在被销毁的时候,将 Context 置为 null 。
How to get the ‘Context’
常用 4 种方法获取 Context 对象:
View.getContext ():返回当前 View 对象的 Context 对象。通常是当前正在展示的 Activity 对象。Activity.getApplicationContext ()[后文会详细介绍这个方法]:获取当前 Activity 所在应用进程的 Context 对象,通常我们使用 Context 对象时,要优先考虑这个全局的进程 Context。ContextWrapper.getBaseContext ():用来获取一个 ContextWrapper 进行装饰之前的 Context。实际开发很少用,也不建议使用。Activity.this:返回当前 Activity 的实例,如果 UI 控件需要使用 Activity 作为 Context 对象,但默认的 Toast 实际上使用的 ApplicationContext 也可以。
在实现View.OnClick监听方法中,写 Toast,不要用this,因为this在onClick (View view)中指的是 view 对象而不是 Activity 实例,所以在这个方法中,应该使用 “当前的 Activity 名.this”,这是入门者比较容易混淆的地方。
getApplication ()和getApplicationContext ():
获取当前 Application 对象用getApplicationContext。但是getApplication又是什么呢?
我们可以自己写代码打印一下:
Application app=(Application) getApplication ();
Log.e (TAG,"getApplication is"+app);
Context context=getApplicationContext ();
Log.e (TAG,"getApplicationContext is"+ context);
运行后看 logcat,效果图就不贴了(电脑卡)。从打印结果可以看出它们 2 个的内存地址是相同的,即它们是同一个对象。因为 Application 本来就是一个 Context,那么这里获取的 getApplicationContext () 自然也是 Application 本身的实例了。那这 2 个相同方法存在的意义是什么呢?(双胞胎?)实际上这 2 个方法在作用域上有比较大的区别。getApplication()一看就知道是用来获取 Application 实例的(道理可以联想 getActivity ())。但 getApplication () 只有在 Activity 和 Service 中才能调用得到。对于比如 BroadcastReceiver 等中也想要获取 Application 实例,这时就需要 getApplicationContext () 方法。
// 继承 BroadcastReceiver 并重写 onReceive () 方法
@Override
public void onReceive (Context context.Intent intent){
Application app=(Application) context.getApplicationContext ();
}
内存泄漏之 Context
我们经常会遇到内存泄漏,比如 Activity 销毁了,但是 Context 还持有该 Activity 的引用,造成了内存泄漏(经常遇到)。
2 种典型的错误引用方式:
- 错误的单例模式:
public class Singleton {
private static Singleton instancel;
private Context context;
private Singleton (Context context){
this.context = context;
}
public static Singleton getInstance (Context context){
if (instance == null ){
instance = new Singleton (context);
}
return instance;
}
}
熟悉单例模式的都知道,这是一个非线程安全的单例模式,instance 作为静态对象,其生命周期要长于普通的对象(单例直到 APP 退出后台才销毁),其中也包含了 Activity 。比如 Activity A 去 getInstance () 得到 instance 对象,传入 this,常驻内存的 Singleton 保存了我们传入的 A 对象,并一直持有,即使 Activity 被销毁掉,但因为它的引用还存在于一个 Singleton 中,就不可能被 GC 掉,这样就导致了内存泄漏。比如典型的数据库操作,存储数据,需要重复的去索取数据,用单例保持数据和拿到 Activity 持有 context 引用,因为单例可以看作是上帝,它帮我们保存数据。所以即使 Activity 被 finish 掉,还有它的引用在 Singleton 中。
- View 持有 Activity 引用:
public class MainActivity extend Activity {
private static Drawable mDrawable;
@Override
protected void onCreate (Bundle saveInstanceState){
super.onCreate ();
setContentView (R.layout.activity_main);
ImageView imageview = new ImageView (this);// 通过代码动态的创建组件,而不是传统的 xml 配置组件,这里的 ImageView 持有当前 Activity 的引用。
mDrawable = getResources ().getDrawable (R.drawable.ic_launcher);
imageview.setImageDrawable (mDrawable);
}
}
上述代码中,有一个 static 的 Drawable 对象。当 ImageView 设置这个 Drawable 的时候,ImageView 保存了这个 mDrawable 的引用,而 ImageView 初始化的时候又传入了 this,此处的 this 是指 MainActivity 的 context 。因为被 static 修饰的 mDrawable 是常驻内存的(比类还要早加载)。MainActivity 是它的间接引用了,当 MainActivity 被销毁的时候,也不能被 GC 掉,就造成了内存泄漏。
How to get the context in the whole
大量的地方都需要使用 Context,我们常常会因为不知道怎么得到这个 Context 而苦恼。那么,全局获取 Context 无疑是最好的解决方案。
很多时候,我们也不是经常为得不到 Context 而发愁,毕竟我们很多的操作都是在活动中进行的,而活动本身就是一个 Context 对象。但 APP 架构复杂后,很多逻辑代码都脱离了 Activity 类,此时又需要使用 Context,所以我们需要采取全局获取 Context 的方法。
举例,我们平常经常会写网络工具类,比如下面的这些代码:
public class HttpUtil {
public static void sendHttpRequest (final String address,final HttpCallbackListener listener){
new Thread (new Runnable ()){
@Override
public void run (){
HttpURLConnection connection = null;
try {
URL url = new URL (address);
connection = (HttpURLConnection) url.openConnection ();
connection.setRequestMethod ("GET");
connection.setConnectTimeout (8000);
connection.setReadTimeout (8000);
connection.setDoInput (true);
connection.setDoOutput (true);
InputStream in = connection.getInputStream ();
BufferedReader reader = new BufferedReader (new InputStreamReader (in));
StringBuilder response = new StringBuilder ();
String line;
while ((line = reader.readLine ())!= null){
response.append (line);
}
if (listener!= null){
// 回调 onFinish ()
listener.onFinish (response.toString);
}
} catch (Execption e){
if (listener!= null){
// 回调 onError ()
listener.onError (e);
}
} finally {
if (connection!= null){
connection.disconnect ();
}
}
}
}.start ();
}
}
上述代码中使用 sendHttpRequest () 方法来发送 HTTP 请求显然没问题。并且还可以在回调方法中处理服务器返回的数据。但是这个方法还可以被优化。当检测不到网络存在的时候就给用户一个 Toast,并不再执行后面的代码。问题来了,Toast 需要一个 Context 参数,但是在本来没有可以传递的 Context 对象。
一般思路:在方法中添加一个 Context 参数:
public static void sendHttpRequest (final String address,final HttpCallbackListener listener,final Context context){
if (!isNetWorkAvailable ()){
Toast.makeText (context,……);
……
}
……
看似可以,但是有点 “甩锅”。我们将获取 Context 的任务转移到了 sendHttpRequest () 方法的调用方。至于调用方能不能得到 Context 对象就不是我们要考虑的问题了。
甩锅不一定是通用的解决方案。于是这里介绍一下如何获取全局 Context 的步骤,通过它在项目的任何地方都能轻松的获取到 Context:
- Android 提供了一个 Application 类,每当 APP 启动的时候,系统就会自动将这个类进行初始化。我们可以定制一个自己的 Application 类,以便管理程序内一些全局的状态信息,比如说全局 Context 。
- 定制一个自己的 Application 并不复杂,首先,需要创建一个
MyApplication类继承自系统的 Application:
public class MyApplication extends Application {
private static Context context;
@Override
public void onCreate (){
context = getApplicationContext ();
}
public static Context getContext (){
return context;
}
}
代码很简单,容易理解。重写了父类的 onCreate() 方法,并通过调用 getApplicationContext() 方法得到一个应用程序级别的 Context,然后又提供了一个静态的 getContext() 方法,在这里将刚才获取到的 Context 进行返回。
- 接下来,我们需要告诉系统,当程序启动的时候应该初始化
MyApplication类,而不是系统默认的Application类。这一步需要在清单文件里面实现,找到清单文件的<application>标签下进行指定就可以了:
<manifest ……>
<application
android:name="com.example.myContext.MyApplication"
<!-- 这里输入 `.MyApplication` 也可以,或者输入 `MyApplication` 根据 AS 提示自动补全包名 -->
...>
</application>
</manifest>
注意:这里一定要加上完整的包名,不然系统将无法找到这个类。
- 以上就实现了一种全局获取 Context 的机制,在这个项目的任何地方使用 Context,只需要调用
MyApplication.getContext()就可以了。
关于自定义 Application 和 LitePal 配置冲突的问题:
自定义需要在清单文件写出 android:name="……"。而为了让 LitePal 可以正常工作,也需要在清单文件下,配置:
android:name="org.litepal.LitePalApplication"
道理也是一样的,这样配置后,LitePal 就能在内部自动获取到 Context 了。
问题:当都已经配置过自定义的 Application 怎么办?岂不是和 LitePalApplication 冲突了?
解答:任何一个项目都只能配置一个 Application。对于这种情况,LitePalApplication 给出了很简单的解决方案,在自定义的 Application 中去调用 LitePal 的初始化方法就可以了:
public class MyApplication extends Application {
private static Context context;
@Override
public void onCreate (){
context = getApplicationContext ();
LitePalApplication.initialize (context);
}
public static Context getContext (){
return context;
}
}
这种写法就相当于我们把全局 Context 对象通过参数传递给了 LitePal,效果和在清单文件配置 LitePalApplication 是一样的。
总结,如何在程序中正确的使用 Context:
一般 Context 造成的内存泄漏,几乎都是当 Context 销毁的时候,因为被引用导致销毁失败。而 Application 的 Context 对象可以简单的理解为伴随着进程存在的(它的生命周期也很长,毕竟 APP 加载的时候先加载 Application,我们可以自定义 Application 然后继承系统的 Application)。
正确使用:
- 当 Application 的 Context 能搞定的情况下,并且生命周期长的对象,优先使用 Application 的 Context;
- 不要让生命周期长于 Activity 的对象持有 Activity 的引用;
- 尽量不要在 Activity 中使用非静态内部类。非静态内部类会隐式持有外部类实例的引用。如果使用静态内部类,将外部实例引用作为弱引用持有。
获取全局 context 的另一种思路
ActivityThread 是主进程的入口,它的 currentApplication 返回值是 application。
import android.app.Application;
import java.lang.reflect.InvocationTargetException;
/**
* 这种方式获取全局的 Application 是一种拓展思路。
* <p>
* 对于组件化项目,不可能把项目实际的 Application 下沉到 Base,而且各个 module 也不需要知道 Application 真实名字
* <p>
* 这种一次反射就能获取全局 Application 对象的方式相比于在 Application#OnCreate 保存一份的方式显示更加通用了
*/
public class AppGlobals {
private static Application sApplication;
public static Application getApplication () {
if (sApplication == null) {
try {
sApplication = (Application) Class.forName("android.app.ActivityThread")
.getMethod("currentApplication")
.invoke(null, (Object []) null);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
return sApplication;
}
}
关于 Context(上下文)的理解
天天进步一点点于 2019 - 07 - 01 16:18:40 发布
一直听到上下文一说,一直没弄清楚到底是啥意思,今天总结一下,不知道对不对。
感觉对 Context 这个词翻译的不太好,不应该叫上下文,应该直接就叫 “环境”,不过都这么叫,就叫上下文好了。
所谓的上下文就是指语境,每一段程序都有很多的外部变量。只有像 Add 这种简单的函数才是没有外部变量的。一旦写的一段程序中有了外部变量,这段程序就是不完整的,不能独立运行,要想让它运行,就必须把所有的外部变量的值一个一个的全部传进去,这些值的集合就叫上下文。
说的通俗一点就是一段程序的执行需要依赖于外部的一些环境(外部变量等等),如果没有这些外部环境,这段程序是运行不起来的。
子程序之于程序,进程之于操作系统,甚至 app 的一屏之于 app,都是一个道理。
当程序执行了一部分,要跳转到其他的地方,而跳转到的地方需要之前程序的一些结果(包括但不限于外部变量,外部对象等等)。
app 点击一个按钮进入一个新的界面,也要保存你是在那个屏幕跳过来的等等信息,以便你点击返回的时候能正确跳回。
上面这些都是上下文的典型例子,所以把 “上下文” 理解为环境就可以了。(而且上下文虽然是上下文,但是程序里面一般都只有上文而已,只是叫的好听叫上下文。进程中断在操作系统中是有上有下的)。
所以说,通俗一点理解就是,当程序从一个位置跳到另一个位置的时候,这个时候就叫上下文的切换(因为它要保存现场,各种的压栈,出栈等等),进程之间切换也叫上下文切换,因为也要保存现场,以便切换回之前的线程。
以我自己的认识水平来说,在 C 或者 C++ 中,context 一般就是一个结构体,用来存储一些关键信息,比如切换上下文时,要保存切换之前的状态和数据,这需要一个结构体来承担,然后将 context 中的状态和数据重新赋值为新的,这样就切换了,等运行完了之后,又要切换回来,那么之前保存的那些状态和数据又要重新启用了,就是这么回事。
我想之所以在多线程网络编程中,现在采用的多是 one loop per thread + thread poll,而不是采用一个 socket 一个线程,就是因为在切换线程(也就是切换上下文)的时候,需要保留大量的现场数据,而在重新切回到该线程时,又要恢复这个保存的数据(即保存的环境),保存 / 恢复都是需要花费 cpu 大量的资源和时间的,所以不如 one loop per thread + thread poll 的模式,当然 one loop per thread + thread poll 还有其他的好处,这只是其中一个好处,不需要大量的切换上下文,占用 cpu 大量的资源。
到底什么是上下文(Context)
caizir913 于 2020 - 09 - 27 14:33:57 发布
看代码经常能看到一些变量命名 XXXcontextXXXctx,或者一些博客中也总提到一个名词:上下文(context)。一直非常疑惑,到底什么叫上下文。也没太好意思问人,感觉就是很简单的概念。自己 google 下,发现也确实有很多人有同样的疑惑。
从字面理解,上下文 —— 就是上下的文意。语文中经常提到的一个名词。根据上下文来理解某个词,某段等等。但是具体到代码中,到底什么才是上下文呢?
先看看别人怎么解释上下文的:
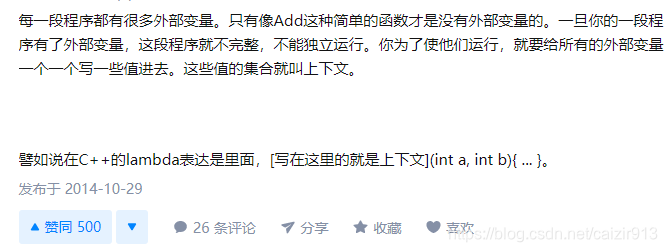
解读一:这 a,b 不就是我们常说的参数嘛,怎么这儿又叫上下文了呢。难道外部变量就是上下文嘛?

解读二:其实这个说的挺好的。只是明明说感性理解,具体到代码里,又有这么多真正的实现。感觉有点点近似佛学了。你悟了,也就知道了。不悟的时候,就有一种知道是什么,又不知道是什么的感觉。

解读三:这……

从维基百科上的解释,应该能说明 context 一词的由来。上下文是针对中断来体现其具体含义的,在内核设计者的眼中,当一个任务在中断时,CPU 会去执行中断对应的任务。中断结束后,再执行之前的 task 时,原有任务的相关数据(在处理原任务所需要的数据)需要保存下来,否则无法继续执行原有任务。如果把相关数据记录到一个变量里。那这个变量就可以称为原 task 的上下文了。作为一个菜鸟,如果我自己写这个变量的命名。我宁愿叫 priTaskInfo,感觉对一个新手来说,information 一词更能直观的表达这种场景对应的概念。但好像 info 太 low 了,而且 info 一词含义有点模糊,所有的相关数据都可以叫 info,概念太宽泛。所以刚开始写类名的时候,用的最多的就是 info,反观高手的代码用 info 的不多。
通俗的理解,上下文,也就是执行任务所需要的相关信息。这个任务可以是一段代码,一个线程,一个进程,一个函数。当这个 “任务”,相关信息需要保存下来,就可以使用 Context 来记录了。
一旦真正理解了上下文的概念,就像解读三描述的一样,只要想有个 object 来保存相关信息,就可以叫 context 了。这个看似高大上的名字,真的会给不理解 context 一词的人,造成一种距离感,难以直观的理解代码表述的含义,还以为有什么高深的用法。
如果不关心内核里上下文的概念(看内核代码的人,上下文这个词,理解的应该很透彻了),在 C++ 代码里,有些地方用 context 一词还是比较合理的。比如回调函数,当回调函数是带参数的时候,如 pCaller.SetCallBack(pFuncCallBack, m_FuncContext); 这个 m_FuncContext 上下文,还是比较能清晰的表达出本身的含义的。当这个回调函数被调用的时候,需要这些参数。这些参数就是这个回调函数的上下文。再比如多线程中,如果多线程某个线程都做同一件事,类似每个线程都打印 hello world,似乎也不需要上下文的概念。如果每个线程都处理一个消息,一般这个参数会被设置为 pHandleMsg。如果各个线程在处理任务时,需要根据线程的调用者来设置调用者相关的信息。那这个时候使用 context 来记录相关信息也感觉无比自然。
看到这儿应该对上下文有个更清晰的理解了吧。再反过来看上面各个解释,似乎说的都对。一旦理解这个词以后,滥用这个概念,想不出好名字,就用 context 来命名,还是挺让人难受的。所以如果仅仅是是一些简单的数据,建议还是按照含义来命名,不要处处都使用 context,写出的代码难以理解。代码还是应该自注释。
想到这儿不得不感叹一句,本来一个简单的概念含义本身是清晰的,一万人看完以后,又给出一万个解释,每个人的解释又不能说是错的。然后新人又不得不把这一万个解释理解了,归纳成自己的理解。什么是上下文,可惜书里从没记载,终于摸出来但岁月却不回来。
【操作系统】进程上下文和线程上下文
以放_于 2022 - 04 - 13 15:17:24 发布
进程
操作系统资源分配的基本单位,也就是指计算机中已执行的程序。
- 在面向进程设计的系统(如早期的 UNIX,Linux 2.4 及更早的版本)中,
进程是程序的基本执行实体; - 在面向线程设计的系统(如当代多数操作系统、Linux 2.6 及更新的版本)中,进程本身不是基本执行单位,而是
线程的容器。 - 程序本身只是指令、数据及其组织形式的描述,相当于一个名词,
进程才是程序(那些指令和数据)的真正执行实例。
进程上下文
进程上下文 就是表示 进程信息 的一系列东西,包括各种变量、寄存器以及进程的运行的环境。这样,当进程被切换后,下次再切换回来继续执行,能够知道原来的状态。
拿 Linux 进程 举例:
---- 进程的运行环境主要包括:
- 进程空间中的代码和数据、各种数据结构、进程堆栈和共享内存区等。
- 环境变量:提供进程运行所需的环境信息。
- 系统数据:进程空间中的对进程进行管理和控制所需的信息,包括进程任务结构体以及内核堆栈等。
- 进程访问设备或者文件时的权限。
- 各种硬件寄存器。
- 地址转换信息。
由上可知,进程的运行环境是动态变化的,尤其是硬件寄存器的值以及进程控制信息是随着进程的运行而不断变化的。在 Linux 中把系统提供给进程的的处于动态变化的运行环境总和称为进程上下文。
线程
操作系统能够进行运算调度的最小单位。
- 大部分情况下,它被包含在进程之中,是进程中的实际运作单位。
- 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
- 线程是独立调度和分派的基本单位。线程可以为操作系统内核调度的内核线程,如 Win32 线程;由用户进程自行调度的用户线程,如 Linux 平台的 POSIX Thread;或者由内核与用户进程,如 Windows 7 的线程,进行混合调度。
- 同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器环境(register context),自己的线程本地存储(thread - local storage)。
线程上下文
进程的上下文的多数信息都与地址空间的描述有关。进程的上下文使用很多系统资源,而且会花费一些时间来从一个进程的上下文切换到另一个进程的上下文。同样的,线程也有上下文。
当线程被抢占时,就会发生线程之间的上下文切换。
如果线程属于相同的进程,它们共享相同的地址空间,因为线程包含在它们所属于的进程的地址空间内。这样,进程需要恢复的多数信息对于线程而言是不需要的。尽管进程和它的线程共享了很多内容,但最为重要的是其地址空间和资源,有些信息对于线程而言是本地且唯一的,而线程的其他方面包含在进程的各个段的内部。
线程上下文与进程上下文对比
| 上下文内容 | 进程 | 线程 |
|---|---|---|
| 指向可执行文件的指针 | × | |
| 栈 | × | × |
| 内存(数据段和堆) | × | |
| 状态 | × | × |
| 优先级 | × | × |
| 程序 IO 的状态 | × | |
| 授予权限 | × | |
| 调度信息 | × | |
| 审计信息 | × | |
| 文件描述符 | × | |
| 文件读 / 写指针 | × | |
| 寄存器组 | × | × |
篇外 关于 “Context” 的讨论
The term “Context” in programming? [closed]
编程中的术语“上下文”?
I have been programming for some months now and a frequently used word is “context” in classes. Like ServletContext (Java), Activity (Android), Service (Java, Android), NSManagedContext (Objective-C, iOS).
我从事编程已有几个月了,在课堂上经常会遇到“context”这个词。比如 ServletContext(Java 语言)、Activity(安卓开发)、Service(Java 和安卓开发中都有)、NSManagedContext(Objective-C 语言,用于 iOS 开发)。
By looking in dictionaries I see that the word means: situation, environment, circumstances etc. However, because I am not a native English speaker I do not understand what I should translate it directly to. For instance, if I were to write a class that either was named SomeClassContext, or a method that had a context parameter, I would not understand when I should name it context because I do not understand it.
通过查阅字典,我发现这个词的意思是:情形、环境、状况等等。然而,由于我的母语不是英语,我不明白该把它直接翻译成什么合适。例如,如果我要编写一个名为 SomeClassContext 的类,或者一个带有 context 参数的方法,我无法理解何时应该用“context”来命名,因为我对这个概念还不理解。
I have been searching for context on Stack Overflow, but no question/answers was able to help me.
I would be very happy if someone could provide me with the explanation.
我一直在 Stack Overflow 上搜索关于“上下文”的解释,但没有找到任何能帮到我的问题或答案。如果有人能给我解释一下,我会非常高兴。
edited Jul 27, 2017 at 18:20
Bill the Lizard
asked May 26, 2011 at 21:08
user772058
Context is saying: the area within which this object acts.
上下文的意思是:这个对象起作用的范围。
– Blundell
Commented May 26, 2011 at 21:18
Context is the state of an object or system, at a point in time
上下文是对象或系统在某一时刻的状态。
– Matt
Commented May 26, 2011 at 22:21
Whenever I’ve seen context in a programming situation, it has usually been (outside of a context menu, which is idiomatic) a giant bag of data+functions. It’s basically a way to namespace global values. People are trained to think “global = BAD,” so they wrap it in a bag in an attempt to get the rule-of-thumb police to look the other way. Kinda like how people wrap liquor in bags hoping nobody knows what’s inside.
每当我在编程场景中看到“context”时,它通常(在惯用的上下文菜单之外)是一大包数据和函数的集合。它本质上是一种对全局值进行命名空间划分的方式。人们被灌输“全局变量不好”的观念,所以他们把相关内容打包成一个整体,试图让那些遵循经验法则的人忽视这其实是类似全局变量的东西。有点像人们把烈酒装在袋子里,希望没人知道里面装的是什么。
– SO_fix_the_vote_sorting_bug-
Commented Jul 26, 2023 at 22:39
Let’s say you go to the dentist to have a tooth pulled out.
假设你去看牙医准备拔牙。
When the receptionist asks you for your name, that’s information they need in order to begin the appointment. In this example, your name is *contextual information*. So in the *context* of visiting the dentist, you need to provide your name to get your tooth pulled.
当接待员询问你的名字时,这是他们为了安排预约所需要的信息。在这个例子中,你的名字就是“上下文信息”。所以在看牙医这个“上下文”情境中,你需要提供你的名字才能拔牙。
Now let’s say you walk over to the bank.
现在假设你去银行。
At the bank, you ask to withdraw $100. The teller needs to establish your identity before giving you money, so you’ll probably have to show them a driver’s license or swipe your ATM card and enter your PIN number. Either way, what you’re providing is context. The teller uses this information to move the transaction forward. They may then ask you which account you’d like to withdraw from. When you answer, “My savings account”, that’s even more context.
在银行,你要求取出 100 美元。出纳员在给你钱之前需要确认你的身份,所以你可能得给他们出示驾照,或者刷你的银行卡并输入密码。不管哪种方式,你提供的这些信息就是“上下文”。出纳员利用这些信息来推进交易。然后他们可能会问你要从哪个账户取款。当你回答“我的储蓄账户”时,这就提供了更多的“上下文”信息。
The more context you give, the more knowledge the other party has to help deal with your request. Sometimes context is optional (like typing more and more words into your Google search to get better results) and sometimes it’s required (like providing your PIN number at the ATM). Either way, it’s information that usually helps to get stuff done.
你提供的上下文信息越多,对方就有越多的信息来帮助处理你的请求。有时候上下文信息是可选的(比如在谷歌搜索中输入越来越多的关键词以获得更好的搜索结果),而有时候它是必需的(比如在自动取款机上输入你的密码)。不管怎样,这些信息通常都有助于事情的完成。
Now let’s say you take your $100 and buy a plane ticket to fly somewhere warm while your mouth heals.
现在假设你拿着取出的 100 美元买了一张机票,在你嘴巴伤口愈合期间飞往一个温暖的地方。
You arrive at a nice sunny destination, but your bag doesn’t make it. It’s lost somewhere in the airport system. So, you take your “baggage claim ticket” (that sticker with the barcode on it) to the “Lost Baggage office”. The first thing the person behind the desk will ask for is that ticket with your baggage number on it. That’s an example of some required context.
你到达了一个阳光明媚的目的地,但你的行李没到。它在机场的系统中丢失了。于是,你拿着你的“行李领取票”(就是那张带有条形码的标签)去“失物招领处”。柜台后面的工作人员首先会要你出示那张带有行李编号的票。这就是一个“必需的上下文”信息的例子。
But then the baggage person asks you for more information about your bag like so they can find it more easily. They ask, "What color is it? What size is it? Does it have wheels? Is it hard or soft? While they don’t necessarily need those pieces of information, it helps narrow things down if you provide them. It reduces the problem area. It makes the search much faster. That’s optional context.
然后行李处理人员会询问你更多关于你行李的信息,以便他们能更容易地找到它。他们会问:“它是什么颜色的?多大尺寸?有没有轮子?是硬壳的还是软质的?”虽然他们不一定非要这些信息,但如果你提供了,就能帮助缩小寻找的范围。这会缩小问题的范围,让搜索速度快很多。这就是“可选的上下文”信息。
Here’s the interesting part: for a lot of software and APIs, the required context usually ends up as actual parameters in a method signature, and optional context goes somewhere else, like a flexible key-value map that can contain anything (and may be empty) or into thread-local storage where it can be accessed if needed.
有趣的是:对于很多软件和应用程序接口(API)来说,“必需的上下文”信息通常最终会成为方法签名中的实际参数,而“可选的上下文”信息则会放在其他地方,比如一个可以包含任何内容(也可能为空)的灵活键值映射表,或者放在线程本地存储中,以便在需要时可以访问。
The examples above are from real life, but you can easily map them to areas within computer science. For example, HTTP headers contain contextual information. Each header relates to information about the request being made. Or when you’re sending along a global transaction ID as part of a two-phase commit process_, that transaction ID is context. It helps the transaction manager coordinate the work because it’s information about the overall task at hand._
上面的例子都来自现实生活,但你可以很容易地将它们与计算机科学领域联系起来。例如,HTTP 头部包含上下文信息。每个头部都与所发出请求的相关信息有关。或者当你在一个两阶段提交过程中发送一个全局事务 ID 时,这个事务 ID 就是上下文信息。它有助于事务管理器协调工作,因为它是关于当前整体任务的信息。
edited Dec 24, 2022 at 20:29
starball
answered May 27, 2011 at 1:01
Brian Kelly
@Brian:From your post and the other answers given here I think I may start to understand it. An object that carries state information about an event, is a “Context” object? Would that be correct? So a RequestContext object will carry information about a specific request, correct? And when another request come the information attached to the RequestContext-object will change. Is it wrong to say that a context-object is a bit like a DTO (data transfer object)? However a context carries information about different related “things” while DTO’s carry information of an object such as a person?Thanks
@布莱恩:从你的帖子以及这里给出的其他答案中,我觉得我可能开始理解了。一个携带有关某个事件的状态信息的对象,就是一个“上下文”对象吗?这样理解对吗?所以一个 RequestContext 对象会携带关于某个特定请求的信息,对吗?而且当另一个请求到来时,附着在 RequestContext 对象上的信息会发生变化。说上下文对象有点像数据传输对象(DTO),这种说法错吗?不过,上下文携带的是关于不同相关“事物”的信息,而 DTO 携带的是像一个人这样的单个对象的信息?谢谢
– user772058
Commented May 27, 2011 at 9:23
You’ve nailed it, that’s exactly right. A RequestContext will indeed carry information about the request in progress (for example, the locale of the client). Contexts are similar to DTO/VO but are usually not as strongly-typed. But you’ve got the concept alright.
你理解得很准确,完全正确。RequestContext 确实会携带关于正在进行的请求的信息(比如,客户端的区域设置)。上下文与数据传输对象(DTO)或值对象(VO)类似,但通常没有那么强的类型约束。不过你已经掌握这个概念了。
– Brian Kelly
Commented May 27, 2011 at 13:28
@Brian: One more question was brought to mind, when talking about context-menus, the meaning of context as I learned from this answer does not make sense in my head. As I understand now context is (short) for carry state about something. So, what does it mean when using the word “context” in this way?
@布莱恩:我又想到一个问题,当谈到上下文菜单时,我从这个答案中学到的“上下文”的含义在我脑子里不太说得通。据我现在的理解,“context” 是表示携带关于某事物的状态(的简称)。那么,在“上下文菜单” 中这样使用“context”这个词是什么意思呢?
– user772058
Commented May 27, 2011 at 18:01
Good question. The meaning of “context” within “context menu” is, “the stuff you’ll see on the menu is dependent on where you click, when you clicked and what else is happening in your application”. Those pieces of information (where/when/what you clicked) represent the context and would be sent to the GUI code so that it can decide what things to offer on the menu.
问得好。“上下文菜单” 中“上下文” 的意思是,“你在菜单上看到的内容取决于你点击的位置、点击的时间以及你的应用程序中正在发生的其他事情”。这些信息(你点击的位置、时间、内容)就代表了上下文,并且会被发送给图形用户界面(GUI)代码,以便它能决定在菜单上显示哪些内容。
– Brian Kelly
Commented May 27, 2011 at 18:12
So, parameters of the method are context. Am I wrong?
那么,方法的参数就是上下文。我错了吗?
– Can Aydoğan
Commented Oct 10, 2013 at 20:36
Context can be seen as a bucket to pass information around. It is typically used to pass things not necessarily tied directly to a method call, but could still be pertinent. A layperson way of describing it might be “stuff you may care about”.
上下文可以被看作是一个用于传递信息的容器。它通常用于传递那些不一定与方法调用直接相关,但仍然可能相关的信息。用外行人的话来描述,它可能是“你可能会关心的东西”。
For e.g. if you were writing a service to update a value in a db, you’d probably pass in the record id, and the new value.
例如,如果你正在编写一个用于更新数据库中某个值的服务,你可能会传入记录的 ID 和新的值。
If you want generic interfaces, you may also define a context to pass, such that the service can perform arbitrary business logic. So you may include a user authentication, the user’s session state, etc… in the context, as the service may perform additional logic dependent on these values.
如果你想要通用的接口,你也可以定义一个要传递的上下文,这样服务就可以执行任意的业务逻辑。所以你可以在上下文中包含用户认证信息、用户的会话状态等等,因为服务可能会根据这些值来执行额外的逻辑。
answered May 26, 2011 at 21:15
Taylor
Another useful way to think about it is “information about what is happening”. Or more academically, it’s “meta information”. That’s a pretty academic phrase, but it’s accurate. In this context.
另一种理解它的有用方式是将其视为“关于正在发生之事的信息”。或者更学术一点来说,它是“元信息”。 这是个相当学术的表述,但却很准确。在这种情况下(指关于“上下文”的解释情境)。
– Brian Kelly
Commented May 26, 2011 at 21:27
its basically the state at a point in time, no more complex than that
它基本上就是某个时间点的状态,没什么比这更复杂的了。
– Matt
Commented May 26, 2011 at 21:57
This is 2015 - may years after this thread began.
现在是 2015 年,距离这个话题开始已经过去好几年了。
Nonetheless, I am posting this message to help anyone out there like me that is Struggled to understand “Context”
尽管如此,我发布这条信息是为了帮助像我一样在理解“上下文”这个概念上有困难的人。
By no means do I claim to have used Context in Java programs - so its entirely up to you to write Context out in hard coding So here goes :-
我绝不是说自己在 Java 程序中使用过“上下文”,所以是否在硬编码中实现“上下文”完全取决于你。所以接下来是:
“Conceptually context” is the same “as tell me more” When a client makes a request to server - in order to carry out the request the server says “give me some more info so that i can help you”. Thus, alongwith the request, the client provides a bundle of details. The server picks and chooses from the bundle all pieces of info required to serve the request. This bundle is what is called “Context”
“从概念上讲,‘上下文’与‘多告诉我一些信息’是一样的。当客户端向服务器发出请求时,为了处理这个请求,服务器会说‘给我更多信息,这样我才能帮你’。因此,客户端会在发出请求的同时提供一系列详细信息。服务器会从这些信息中挑选出处理该请求所需的所有信息。这个信息集合就是所谓的‘上下文’。
E.g.
例如:
Patient goes to doc and says treat_me ( “I have a headache” ) Doc office gives the patient a form to fill. Patient fills form. The form is used by the doctor to carry out the “treat_me” request.
病人去看医生并说“治疗我(我头疼)”。医生办公室给病人一张表格让其填写。病人填好了表格。医生会用这张表格来处理“治疗我”这个请求。
Here is how the request now looks :
现在这个请求看起来是这样的:
treat_me ( “i have a headache”, filled_form_num_23321 )
治疗我(“我头疼”,已填写的表格编号 23321)
Here is how filled_form_num_23321 looks :
这是已填写的表格编号 23321(filled_form_num_23321)的内容:
Q.What lead to the condition? A. 10 pegs of neat Scotch last nite
问:是什么导致了这种情况?答:昨晚喝了 10 杯纯苏格兰威士忌
Q.Patient name? A. Joe Bigdrinker
问:病人姓名?答:乔·比格德林克(Joe Bigdrinker)
Q.Age? 98
问:年龄?98 岁
In this transaction filled_form_num_23321 is the “context”.
在这个事务中,已填写的表格编号 23321(filled_form_num_23321)就是“上下文”。
Hope this helps in clarifying the concept of “Context”.
希望这有助于阐明“上下文”这个概念。
edited Mar 20, 2015 at 16:16
Ram answered Mar 20, 2015 at 15:27
Ram
i always think of context as a particular state relevant to the object or construct i am working with.
我一直把“上下文”看作是与我正在处理的对象或结构相关的特定状态。
For example, when you are using drawRect in a view (where all drawing must be done for a view) you must always get the currentGraphicsContext into which you will issue your core graphics statements. This context contains things like bounds of the view, the stroke colour, the stroke thickness for drawing a line, the fill color for filling a closed Path etc. this context (like most others) is just the current state at this point in time. so think of the graphics context in this case as just a set of state such as
例如,当你在一个视图中使用 drawRect 方法时(在这个视图中所有的绘图操作都要进行),你必须获取当前的图形上下文(currentGraphicsContext),然后在其中发出你的核心图形绘制语句。这个上下文包含诸如视图的边界、笔画颜色、绘制线条的笔触粗细、填充闭合路径的填充颜色等信息。这个上下文(和大多数其他上下文一样)只是此时的当前状态。所以在这种情况下,可以把图形上下文看作是一组状态信息,比如:
stroke thickenss is 1.5 pixels fill color is black bounds of view is (155, 200) stroke color is Red
笔触粗细为 1.5 像素,填充颜色为黑色,视图边界为(155,200),笔画颜色为红色
Its basically the state at the current point in time …
它基本上是当前时间点的状态…
answered May 26, 2011 at 21:57
Matt
Context refers to the execution context, which is the symbols reachable from a given point in the code, and the value of those symbols in that particular execution.
“上下文(Context)”指的是“执行上下文”,它是指从代码中某个给定点可访问的符号,以及在特定执行过程中这些符号的值。
Context is an important concept because:
上下文是一个重要的概念,原因如下:
- Executable units (functions, procedures, instructions) may produce different results or behave differently under different contexts.
- 可执行单元(函数、过程、指令)在不同的上下文中可能会产生不同的结果或表现出不同的行为。
- The larger or more complex the context, the more difficult to understand what a piece of code does (that’s why global variables are shunned upon).
- 上下文越大或越复杂,就越难以理解一段代码的功能(这就是为什么全局变量不受欢迎的原因)。
You do not have to write context classes or pass context parameters. Any parameter passed to a function/method becomes part of the execution context when it is invoked.
你不必编写“上下文”类或传递“上下文”参数。任何传递给函数或方法的参数在被调用时都会成为执行上下文的一部分。
Even though you’re not an English speaker, I recommend you go through a copy of Code Complete for a gentle yet thorough introduction to concepts like context, modularity, coupling, cohesion, and so forth.
即使你不是以英语为母语的人,我也建议你阅读一下《代码大全》(Code Complete),它会对“上下文”、“模块化”、“耦合”、“内聚”等概念进行温和而全面的介绍。
edited Aug 17, 2015 at 17:00
answered May 27, 2011 at 19:23
Apalala
I see there is a second edition. Can I read find it there too?
我看到有第二版。我在那里面也能找到相关内容吗?
– user772058
Commented May 27, 2011 at 19:43
I browsed the second edition at the book store, and decided to stick with the original. I don’t remember why.
我在书店浏览了第二版,然后决定还是看原版。我不记得原因了。
– Apalala Commented Jun 15, 2011 at 17:26
To give a practical example. Lets say you have a certain webpage to fetch/render some information based on the user (thats logged on) and language of the browser. The logic of fetching the information is independent from the user and the language. Your page will receive a user and a language … for the logic it doesnt matter if it is me or you or english or spanish.
举个实际的例子。假设你有一个特定的网页,它要根据(已登录的)用户以及浏览器的语言来获取和呈现一些信息。获取信息的逻辑与用户和语言本身无关。你的页面会接收一个用户信息和一种语言信息……对于这个逻辑来说,无论是我还是你,或者是英语还是西班牙语都没有关系。
Some pseudo code: 一些伪代码:
class FooPage
{
void handleRequest(RequestContext context)
{
User user = context.getUser();
Locale locale = context.getLocale();
… do some logic based on the context
}
}
Its not that difficult, but it takes some time to understand the concept
这并不是很难理解,但理解这个概念需要一些时间。
answered May 26, 2011 at 21:49
lukin
Context in your case is the environment where your application is running.
在你的例子中,“上下文”就是你的应用程序运行的环境。
It provides information / services / abilities your application will need in order to run properly.
它提供了你的应用程序为了正常运行所需要的信息、服务或功能。
HTH(Hope This Helps,希望这有所帮助)
answered Jul 30, 2016 at 3:12
user6656519
3 yrs later so maybe a little late, but, maybe this thread would help you. It illustrates that the word “context” has a technical meaning in programming (not just a plain English meaning).
三年后了,可能有点晚,但也许这个讨论串能帮到你。它说明了“上下文(context)”这个词在编程中有一个技术层面的含义(而不仅仅是普通英语中的意思)。
What programming languages are context-free?
哪些编程语言是无上下文的?
Not sure if you can use it as an example and pull some information out of it or not. I too would love to hear a language agnostic explanation of the technical programming term “context”
不确定你是否能把它当作一个例子并从中获取一些信息。我也很想听到一个与语言无关的关于编程技术术语“上下文”的解释。
Edit : Or it at least shows that the term “context” can be applied in a technical, programming context (no punn intended). Possibly in more than one concrete application of the term.
编辑:或者至少它表明了“上下文”这个术语可以应用于技术编程的情境中(无意双关)。可能在这个术语的多个具体应用中都有体现。
edited May 23, 2017 at 12:34
answered Jan 21, 2015 at 18:09 Jake
What programming languages are context-free?
哪些编程语言是无上下文的?
Asked 15 years, 10 months ago
Modified 3 years, 2 months ago
Or, to be a little more precise: which programming languages are defined by a context-free grammar?
或者,更准确一点说:哪些编程语言是由无上下文语法定义的呢?
From what I gather C++ is not context-free due to things like macros and templates. My gut tells me that functional languages might be context free, but I don’t have any hard data to back that up with.
据我了解,由于宏和模板等因素,C++ 不是无上下文的。我直觉上觉得函数式语言可能是无上下文的,但我没有确凿的数据来支持这一点。
Extra rep for concise examples
对于简洁的例子会额外加分哦
“rep” 是 “reputation” 的缩写,常见于一些论坛或社区语境中,意思是 “声誉;声望;积分” 等。
· compiler-theory_ 编译器理论
· context-free-grammar_ 无上下文语法
edited May 22, 2009 at 16:43
asked May 22, 2009 at 15:31
n3rd
The short version: There are hardly any real-world programming languages that are context-free in any meaning of the word. Whether a language is context-free or not has nothing to do with it being functional. It is simply a matter of how complex the syntax is.
简而言之:几乎没有任何现实世界中的编程语言在任何意义上是无上下文的。一种语言是否无上下文与它是否是函数式语言毫无关系。这仅仅取决于其语法的复杂程度。
Here’s a CFG for the imperative language Brainfuck_:
这是命令式语言 Brainfuck 的一个无上下文语法(CFG):
Program → Instr Program | ε
Instr → '+' | '-' | '>' | '<' | ',' | '.' | '[' Program ']'
And here’s a CFG for the functional SKI combinator calculus_:
这是函数式 SKI 组合子演算(SKI combinator calculus) 的一个无上下文语法(CFG):
Program → E
E → 'S' E E E
E → 'K' E E
E → 'I'
E → '(' E ')'
These CFGs recognize all valid programs of the two languages because they’re so simple.
这些无上下文语法(CFG)能够识别这两种语言的所有有效程序,因为它们非常简单。
The longer version: Usually, context-free grammars (CFGs) are only used to roughly specify the syntax of a language. One must distinguish between syntactically correct programs and programs that compile/evaluate correctly. Most commonly, compilers split language analysis into syntax analysis that builds and verifies the general structure of a piece of code, and semantic analysis that verifies the meaning of the program.
详细版本:通常,无上下文语法(CFG)仅用于粗略地指定一种语言的语法。我们必须区分“语法正确的程序”和“能够正确编译/求值的程序”。最常见的情况是,编译器将语言分析分为“语法分析”(构建并验证一段代码的总体结构)和“语义分析”(验证程序的含义)。
If by “context-free language” you mean “… for which all programs compile”, then the answer is: hardly any. Languages that fit this bill hardly have any rules or complicated features, like the existence of variables, whitespace-sensitivity, a type system, or any other context: Information defined in one place and relied upon in another.
如果“无上下文语言”你指的是“……所有程序都能编译的语言”,那么答案是:几乎没有。符合这一条件的语言几乎没有任何规则或复杂的特性,比如变量的存在、对空白字符的敏感性、类型系统,或者任何其他“上下文”信息:即在一个地方定义并在另一个地方依赖的信息。
If, on the other hand, “context-free language” only means “… for which all programs pass syntax analysis”, the answer is a matter of how complex the syntax alone is. There are many syntactic features that are hard or impossible to describe with a CFG alone. Some of these are overcome by adding additional state to parsers for keeping track of counters, lookup tables, and so on.
另一方面,如果“无上下文语言”仅表示“……所有程序都能通过语法分析的语言”,那么答案就取决于仅语法本身的复杂程度。有许多语法特性很难或不可能仅用无上下文语法(CFG)来描述。其中一些问题可以通过向解析器添加额外的状态来解决,以便跟踪计数器、查找表等等。
Examples of syntactic features that are not possible to express with a CFG:
无法用无上下文语法(CFG)表达的语法特性示例:
· Indentation- and whitespace-sensitive languages like Python and Haskell. Keeping track of arbitrarily nested indentation levels is essentially context-sensitive and requires separate counters for the indentation level; both how many spaces that are used for each level and how many levels there are.
· 像 Python 和 Haskell 这样对缩进和空白字符敏感的语言。跟踪任意嵌套的缩进级别本质上是上下文相关的,并且需要为缩进级别设置单独的计数器;既要记录每个级别使用了多少个空格,也要记录有多少个缩进级别。
Allowing only a fixed level of indentation using a fixed amount of spaces would work by duplicating the grammar for each level of indentation, but in practice this is inconvenient.
仅允许使用固定数量的空格进行固定级别的缩进,这种情况可以通过为每个缩进级别复制语法来处理,但在实际应用中,这样做并不方便。
· The C Typedef Parsing Problem_ says that C programs are ambiguous during lexical analysis because it cannot know from the grammar alone if something is a regular identifier or a typedef alias for an existing type._
· C 语言的 typedef 解析问题表明,C 程序在词法分析过程中存在歧义,因为仅从语法本身无法确定某个东西是常规标识符还是现有类型的 typedef 别名。
The example is:
示例如下:
typedef int my_int;
my_int x;
At the semicolon, the type environment needs to be updated with an entry for my_int. But if the lexer has already looked ahead to my_int, it will have lexed it as an identifier rather than a type name.
typedef int my_int;(定义 int 类型的别名 my_int)
my_int x;(声明一个 my_int 类型的变量 x)
在分号处,类型环境需要使用 my_int 的条目进行更新。但是,如果词法分析器已经预读了 my_int,它会将其词法化为一个标识符,而不是一个类型名。
In context-free grammar terms, the X → … rule that would trigger on my_int is ambiguous: It could be either one that produces an identifier, or one that produces a typedef’ed type; knowing which one relies on a lookup table (context) beyond the grammar itself.
从无上下文语法的角度来看,在 my_int 上触发的 X → … 规则是有歧义的:它既可以生成一个标识符,也可以生成一个 typedef 定义的类型;要确定是哪一种情况,需要依赖于语法本身之外的查找表(上下文)。
· Macro- and template-based languages like Lisp, C++, Template Haskell, Nim, and so on. Since the syntax changes as it is being parsed, one solution is to make the parser into a self-modifying program. See also Is C++ context-free or context-sensitive?__
· 像 Lisp、C++、Template Haskell、Nim 等基于宏和模板的语言。由于在解析过程中语法会发生变化,一种解决方案是将解析器变成一个自我修改的程序。
· Often, operator precedence and associativity are not expressed directly in CFGs even though it is possible. For example, a CFG for a small expression grammar where ^ binds tighter than ×, and × binds tighter than +, might look like this:
· 通常,即使运算符的优先级和结合性可以在无上下文语法(CFG)中表示,但实际上它们并不总是直接表示出来。例如,对于一个小型表达式语法,其中 ^ 的绑定比 × 更紧密,× 的绑定比 + 更紧密,其无上下文语法(CFG)可能如下所示:
E → E ^ E
E → E × E
E → E + E
E → (E)
E → num
This CFG is ambiguous_, however, and is often accompanied by a precedence / associativity table_ saying e.g. that ^ binds tightest, × binds tighter than +, that ^ is right-associative, and that × and + are left-associative.
然而,这个无上下文语法(CFG)是有歧义的,并且通常会附带一个优先级/结合性表,例如说明 ^ 的绑定最紧密,× 的绑定比 + 更紧密,^ 是右结合的,而 × 和 + 是左结合的。
Precedence and associativity can be encoded into a CFG in a mechanical way such that it is unambiguous and only produces syntax trees where the operators behave correctly. An example of this for the grammar above:
优先级和结合性可以通过一种机械的方式编码到无上下文语法(CFG)中,使得语法是明确的,并且只生成运算符行为正确的语法树。对于上面的语法,一个示例如下:
E₀ → EA E₁
EA → E₁ + EA
EA → ε
E₁ → EM E₂
EM → E₂ × EM
EM → ε
E₂ → E₃ EP
EP → ^ E₃ EP
E₃ → num
E₃ → (E₀)
But ambiguous CFGs + precedence / associativity tables are common because they’re more readable and because various types of LR parser_ generator libraries can produce more efficient parsers by eliminating shift/reduce conflicts_ instead of dealing with an unambiguous, transformed grammar of a larger size._
但是,有歧义的无上下文语法(CFG)加上优先级/结合性表的组合很常见,因为它们更具可读性,并且各种类型的 LR 解析器生成器库可以通过消除移进/归约冲突,而不是处理一个更大规模的明确的、转换后的语法,来生成更高效的解析器。
In theory, all finite sets of strings are regular languages, and so all legal programs of bounded size are regular. Since regular languages are a subset of context-free languages, all programs of bounded size are context-free. The argument continues,
理论上,所有有限的字符串集合都是正则语言,因此所有大小有界的合法程序都是正则的。由于正则语言是无上下文语言的一个子集,所以所有大小有界的程序都是无上下文的。争论还在继续,
While it can be argued that it would be an acceptable limitation for a language to allow only programs of less than a million lines, it is not practical to describe a programming language as a regular language: The description would be far too large.
— Torben Morgensen’s Basics of Compiler Design, ch. 2.10.2._
虽然可以认为,对于一种语言来说,只允许编写少于一百万行的程序是一个可以接受的限制,但将一种编程语言描述为正则语言是不切实际的:因为这样的描述会过于庞大。
— 托本·摩根森(Torben Morgensen)的《编译器设计基础》,第 2.10.2 章
The same goes for CFGs. To address your sub-question a little differently,
对于无上下文语法(CFG)也是如此。换一种方式来回答你的子问题,
Which programming languages are defined by a context-free grammar?
哪些编程语言是由无上下文语法定义的呢?
Most real-world programming languages are defined by their implementations, and most parsers for real-world programming languages are either hand-written or uses a parser generator that extends context-free parsing. It is unfortunately not that common to find an exact CFG for your favourite language. When you do, it’s usually in Backus-Naur form_ (BNF), or a parser specification that most likely isn’t purely context-free.
大多数现实世界中的编程语言是由它们的实现来定义的,并且大多数用于现实世界编程语言的解析器要么是手写的,要么是使用扩展了无上下文解析的解析器生成器生成的。不幸的是,为你喜欢的编程语言找到一个精确的无上下文语法(CFG)并不是那么常见。当你找到的时候,它通常是巴科斯范式(Backus-Naur form)(BNF),或者是一个很可能并非完全无上下文的解析器规范。
Examples of grammar specifications from the wild:
来自实际应用中的语法规范示例:
· BNF for Standard ML._用于标准 ML 的 BNF
· BNF-like for Haskell._ Haskell 的类似巴科斯范式的语法规范
· BNF for SQL._ 适用于 SQL 的 BNF
· Yacc grammar for PHP._ PHP 的 Yacc 语法
edited Dec 18, 2021 at 18:44
answered Jul 16, 2013 at 20:18
sshine
agree and added relevant comment on Dave’s answer about this, +1
同意,并在戴夫(Dave)关于此问题的答案上添加了相关评论,+1
– Nikos M.
Commented Jun 8, 2015 at 19:46
Another advantage of the CFG + associativity table is that some language has user-defined operator and these operators can have their own precedence set by the use. This is also cannot be parsed by CFG alone.
无上下文语法(CFG)加上结合性表的另一个优点是,有些语言具有用户定义的运算符,并且这些运算符可以由用户设置自己的优先级。这也是仅靠无上下文语法(CFG)无法解析的。
– Xwtek
Commented Nov 25, 2021 at 17:25
Are you saying that BNF and/or Bison’s grammar specification are not “purely” context-free? If so, what do you mean by that? BNF is certainly a way of writing a context-free grammar; it cannot represent a grammar which is not context-free. Bison’s only real extension feature is operator-precedence declarations, which do not alter the set of recognised inputs; all they do is resolve certain ambiguities. (Context-free grammars can be ambiguous. That might be a problem for practical parsing, but it doesn’t make the grammar or the language not context-free.)
你是说巴科斯范式(BNF)和/或 Bison 的语法规范不是“纯粹”的无上下文语法吗?如果是这样,你是什么意思呢?巴科斯范式(BNF)当然是一种编写无上下文语法的方式;它不能表示非无上下文的语法。Bison 唯一真正的扩展特性是运算符优先级声明,它不会改变已识别的输入集合;它们所做的只是解决某些歧义。(无上下文语法可能存在歧义。这对于实际的解析可能是个问题,但这并不意味着该语法或语言就不是无上下文的。)
– rici Commented Dec 18, 2021 at 22:24
@Xwtek: Bison’s precedence/associativity rules are static, not dynamic, so they don’t add anything to the set of languages which can be parsed. If you have a language --like Swift-- with dynamic precedence, you can still parse it with a context-free grammar (sort of) as long as there is a predefined finite set of precedence levels. The grammar then only refers to precedence levels; the tokeniser then needs to return each operator with the syntactic class of its associated precedence level (which I agree isn’t strictly context-free, but it’s in some sense outside of the parser.)
@Xwtek:Bison 的优先级/结合性规则是静态的,而非动态的,所以它们不会给可解析语言的集合增添任何内容。如果你有一种语言——比如 Swift——具有动态优先级,只要存在一组预定义的有限优先级级别,你仍然(在某种程度上)可以使用无上下文语法来解析它。如此一来,该语法就仅涉及优先级级别;接着,词法分析器需要返回每个运算符及其相关优先级级别的语法类别(我承认这并非严格意义上的无上下文,但从某种角度而言,它超出了解析器的范畴)。
– rici Commented Dec 18, 2021 at 22:30
The set of programs that are syntactically correct is context-free for almost all languages.
对于几乎所有语言来说,语法上正确的程序集是无上下文的。
The set of programs that compile is not context-free for almost all languages. For example, if the set of all compiling C programs were context free, then by intersecting with a regular language (also known as a regex), the set of all compiling C programs that match
对于几乎所有语言而言,能够编译的程序集并非是无上下文的。例如,如果所有能编译的 C 程序的集合是无上下文的,那么通过与一种正则语言(也称为正则表达式)相交,所有符合以下模式的能编译的 C 程序的集合
^int main\(void\) { int a+; a+ = a+; return 0; }$
would be context-free, but this is clearly isomorphic to the language a^kba^kba^k, which is well-known not to be context-free.
将是无上下文的,但这显然与语言 a^kba^kba^k 同构,而众所周知该语言并不是无上下文的。
answered May 22, 2009 at 15:37
Dave
+1 for the answer which is true. The accepted answer is misleading.
该答案正确,加 1 分。已采纳的答案具有误导性。
– Derrick Turk Commented Feb 23, 2010 at 20:27
If anyone desires to see a proof that the language { a^k b a^k b a^k b | k >= 0 } is not regular, see Torben Mogensen’s Basics of Compiler Design chapter 2.10.2: diku.dk/~torbenm/Basics
如果有人希望看到语言 { a^k b a^k b a^k b | k >= 0 } 不是正则语言的证明,请参阅托本·莫根森(Torben Mogensen)的《编译器设计基础》第 2.10.2 章:diku.dk/~torbenm/Basics
– sshine Commented Jul 16, 2013 at 18:49
hmm the distinction between syntacticaly valid programs and semanticaly valid programs is misleading, since the latter is expressed syntacticaly in context-sensitive grammars (for cases of interest in programming languages). Saying a program is syntacticaly valid because a CFG can accept it, is wrong since the fact that the language of valid programs requires conditions which limit the strings accepted by merely CFGs, means they cannot be described by CFGs. Anyway +1
嗯,句法上有效程序和语义上有效程序之间的区别具有误导性,因为对于编程语言中令人关注的情况而言,后者是通过上下文相关语法以句法形式表达的。说一个程序在句法上是有效的,是因为无上下文语法(CFG)可以接受它,这种说法是错误的,因为有效程序的语言需要一些条件来限制仅仅由无上下文语法(CFG)所接受的字符串,这意味着它们无法用无上下文语法(CFG)来描述。不管怎样,加 1 分。
– Nikos M.Commented Jun 8, 2015 at 19:44
The first sentence doesn’t make much sense. When is a program syntactically correct? Usually when the compiler accepts it without “syntax errors” and is able to generate code. You argue correctly that most languages are not context-free in this sense. If, on the other hand, you define “syntactically correct” as “accepted by the parsing pass of a compiler”, then the sentence is tautological, since the parser uses a context-free grammar and thus accepts a context-free super-set of the programming language.
第一句话没什么意义。一个程序何时在句法上是正确的呢?通常是当编译器在没有“语法错误”的情况下接受它并且能够生成代码的时候。你正确地指出,从这个意义上来说,大多数语言都不是无上下文的。另一方面,如果你将“句法上正确”定义为“被编译器的解析阶段所接受”,那么这个句子就是同义反复的,因为解析器使用的是无上下文语法,因此接受的是编程语言的一个无上下文的超集。
– gernot Commented Jun 29, 2021 at 14:40
Depending on how you understand the question, the answer changes. But IMNSHO, the proper answer is that all modern programming languages are in fact context sensitive. For example there is no context free grammar that accepts only syntactically correct C programs. People who point to yacc/bison context free grammars for C are missing the point.
根据你对这个问题的理解方式,答案会有所不同。但在我个人浅见(IMNSHO)中,正确的答案是所有现代编程语言实际上都是上下文相关的。例如,不存在只接受语法正确的 C 程序的无上下文语法。那些指出 C 语言的 yacc/bison 无上下文语法的人没有抓住重点。
answered Aug 2, 2011 at 6:50
starflyer
To go for the most dramatic example of a non-context-free grammar, Perl’s grammar is, as I understand it, turing-complete.._
举一个非无上下文语法的最具代表性的例子,据我所知,Perl 的语法是图灵完备的。
answered Aug 18, 2009 at 3:14
Devin Jeanpierre
If I understand your question, you are looking for programming languages which can be described by context free grammars (cfg) so that the cfg generates all valid programs and only valid programs.
如果我理解正确的话,你正在寻找那些可以用无上下文语法(cfg)来描述的编程语言,这样无上下文语法(cfg)就能生成所有有效程序,并且仅仅生成有效程序。
I believe that most (if not all) modern programming languages are therefore not context free. For example, once you have user defined types (very common in modern languages) you are automatically context sensitive.
我认为因此大多数(如果不是全部的话)现代编程语言都不是无上下文的。例如,一旦你拥有了用户定义的类型(这在现代语言中非常常见),你就自动处于上下文相关的情况了。
There is a difference between verifying syntax and verifying semantic correctness of a program. Checking syntax is context free, whereas checking semantic correctness isn’t (again, in most languages).
验证一个程序的语法和验证其语义正确性之间是有区别的。检查语法是无上下文的,而检查语义正确性则不是(同样,在大多数语言中是这样)。
This, however, does not mean that such a language cannot exist. Untyped lambda calculus., for example, can be described using a context free grammar, and is, of course, Turing complete._
然而,这并不意味着这样的语言不可能存在。例如,无类型的lambda 演算可以用无上下文语法来描述,并且它当然是图灵完备的。
edited Jun 25, 2012 at 13:57
answered Jun 25, 2012 at 13:46
Ginandi
ost of the modern programming languages are not context-free languages. As a proof, if I delve into the root of CFL its corresponding machine PDA can’t process string matchings like {ww | w is a string}. So most programming languages require that.
大多数现代编程语言都不是无上下文语言。作为一个证明,如果我深入研究上下文无关语言(CFL)的根源,其对应的机器——下推自动机(PDA)无法处理像 {ww | w 是一个字符串} 这样的字符串匹配。所以大多数编程语言都有这样的需求。
Example:
int fa; // w
fa=1; // ww as parser treat it like this
因为解析器会这样处理它
edited Mar 1, 2017 at 19:39
nbro answered Apr 1, 2013 at 14:51
P.R.
VHDL is somewhat context sensitive:
VHDL 在某种程度上是上下文相关的:
VHDL is context-sensitive in a mean way. Consider this statement inside a process:
VHDL 在某种程度上是上下文相关的。考虑在一个进程中的这个语句:
jinx := foo(1);
Well, depending on the objects defined in the scope of the process (and its enclosing scopes), this can be either:
嗯,根据在进程范围(及其封闭范围)中定义的对象,这可能是:
-
A function call
一个函数调用
-
Indexing an array
对一个数组进行索引
-
Indexing an array returned by a parameter-less function call
对一个无参数函数调用返回的数组进行索引
To parse this correctly, a parser has to carry a hierarchical symbol table (with enclosing scopes), and the current file isn’t even enough. foo can be a function defined in a package. So the parser should first analyze the packages imported by the file it’s parsing, and figure out the symbols defined in them.
为了正确解析这个语句,一个解析器必须携带一个分层符号表(带有封闭范围),而且仅仅当前文件是不够的。foo 可以是在一个包中定义的函数。所以解析器应该首先分析它正在解析的文件所导入的包,并弄清楚在其中定义的符号。
This is just an example. The VHDL type/subtype system is a similarly context-sensitive mess that’s very difficult to parse.
这只是一个例子。VHDL 的类型/子类型系统同样是一个上下文相关的混乱情况,非常难以解析。
(Eli Bendersky, “Parsing VHDL is very hard”., 2009)
(伊莱·本德斯基(Eli Bendersky),“解析 VHDL 是非常困难的”,2009 年)
edited Mar 4, 2019 at 7:50
9999years answered May 22, 2009 at 15:46 Graham Gimbert
I’m a new user and am not allowed to post links.
我是一个新用户,不允许发布链接。
– Graham Gimbert Commented May 22, 2009 at 16:21
@Graham: no, you absolutely may. There’s no restriction for new users on posting links.
@格雷厄姆:不,你绝对可以。新用户发布链接没有限制。
– Konrad Rudolph Commented May 23, 2009 at 8:53
Let’s take Swift, where the user can define operators including operator precedence and associativity. For example, the operators + and * are actually defined in the standard library.
我们以 Swift 为例,在 Swift 中用户可以定义运算符,包括运算符的优先级和结合性。例如,运算符 + 和 * 实际上是在标准库中定义的。
A context free grammar and a lexer may be able to parse a + b - c * d + e, but the semantics is “five operands a, b, c, d and e, separated by the operators +, -, * and +”. That’s what a parser can achieve without knowing about operators. A context free grammar and a lexer may also be able to parse a ±+ b -± c, which is three operands a, b and c separated by operators ±+ and -±.
一个无上下文语法和一个词法分析器也许能够解析 a + b - c * d + e,但语义是“五个操作数 a、b、c、d 和 e,由运算符 +、-、* 和 + 分隔”。这就是一个解析器在不知道运算符(优先级和结合性)的情况下所能做到的。一个无上下文语法和一个词法分析器也许还能够解析 a ±+ b -± c,这是三个操作数 a、b 和 c,由运算符 ±+ 和 -± 分隔。
A parser can “parse” a source file according to a context-free Swift grammar, but that’s nowhere near the job done. Another step would be collecting knowledge about operators, and then change the semantics of a + b - c * d + e to be the same as operator+ (operator- (operator+ (operator+ (a, b), operator* (c, d)), e).
解析器可以依据无上下文的 Swift 语法对源文件进行“解析”,但这远远未完成解析工作。接下来还需要收集有关运算符的信息,然后将 a + b - c * d + e 的语义转换为与 operator+ (operator- (operator+ (operator+ (a, b), operator* (c, d)), e) 一致。
So there exists (or perhaps exists, I haven’t double checked) a context-free grammar, but it only gets you so far in parsing a program.
所以,(可能)存在一个无上下文语法(我还没仔细核实),但在解析程序时,它能起的作用也就到此为止了。
answered Sep 8, 2020 at 22:13 gnasher729
Are modern programming languages context-free?
现代编程语言是上下文无关的吗?
Which language class are today’s modern programming languages like Java, JavaScript, and Python in?
如今像 Java、JavaScript 和 Python 这样的现代编程语言属于哪类语言呢?
It appears (?) they are not context-free and not regular languages.
看起来(?)它们既不是上下文无关语言,也不是正则语言。
Are these programming languages context-sensitive or decidable languages? I am very confused!
这些编程语言是上下文相关语言还是可判定语言呢?我非常困惑!
I know that context-free is more powerful than regular languages and that context-sensitive is more powerful than context-free.
我知道上下文无关语言比正则语言表达能力更强,上下文相关语言比上下文无关语言表达能力更强。
Are modern programming languages both context-free and context-sensitive?
现代编程语言既是上下文无关的又是上下文相关的吗?
edited May 11, 2021 at 8:46
Adam Burke asked May 8, 2021 at 20:36
Jonte YH
@nirshahar “It has a grammar therefore it is context free” is not correct. It is fine and easy to define grammars which describe a language that is not context free.
@nirshahar “因为它有语法规则,所以它是上下文无关的”这种说法是不正确的。定义描述非上下文无关语言的语法规则是很容易的。
– Daniel Wagner CommentedMay 9, 2021 at 19:28
Practically no programming language, modern or ancient, is truly context-free, regardless of what people will tell you. But it hardly matters. Every programming language can be parsed; otherwise, it wouldn’t be very useful. So all the deviations from context freeness have been dealt with.
实际上,无论别人怎么说,没有哪种编程语言,无论是现代的还是古老的,是真正上下文无关的。但这其实没那么重要。每种编程语言都可以被解析;否则,它就没什么用了。所以所有与上下文无关性的偏差都已经得到处理。
What people usually mean when they tell you that programming languages are context-free because somewhere in the documentation there’s a context-free grammar, is that the set of well-formed programs (that is, the “language” in the sense of formal language theory) is a subset of a context-free grammar, conditioned by a set of constraints written in the rest of the language documentation. That’s mostly how programs are parsed: a context-free grammar is used, which recognises all valid and some invalid programs, and then the resulting parse tree is traversed to apply the constraints.
当人们告诉你编程语言是上下文无关的,因为文档中某个地方有上下文无关语法时,他们通常的意思是,格式良好的程序集合(即形式语言理论意义上的“语言”)是上下文无关语法的一个子集,该子集受语言文档其余部分所写的一组约束条件限制。程序解析大多是这样进行的:使用上下文无关语法,它能识别所有有效的和一些无效的程序,然后遍历得到的解析树来应用这些约束条件。
To justify describing the language as “context-free”, there’s a tendency to say that these constraints are “semantic” (and therefore not part of the language syntax). [Note 1] But that’s not a very meaningful use of the word “semantic”, since rules like “every variable must be declared” (which is common, if by no means universal) is certainly syntactic in the sense that you can easily apply it without knowing anything about the meaning of the various language constructs. All it requires is verifying that a symbol used in some scope also appears in a declaration in an enclosing scope. However, the “also appears” part makes this rule context-sensitive.
为了证明将语言描述为“上下文无关”是合理的,人们倾向于说这些约束是“语义上的”(因此不属于语言语法的一部分)。[注 1] 但这种对“语义”一词的使用没什么意义,因为像“每个变量都必须声明”这样的规则(虽然并非普遍适用,但很常见),从你可以在不了解各种语言结构含义的情况下轻松应用它这个意义上来说,肯定是语法层面的。它只需要验证在某个作用域中使用的符号也出现在包含该作用域的声明中。然而,“也出现”这部分使得该规则具有上下文相关性。
That rule is somewhat similar to the constraints mentioned in this post about Javascript_ (linked to from one of your comments to your question): that neither a Javascript object definition nor a function parameter list can define the same identifier twice, another rule which is both clearly context-sensitive and clearly syntactic.
该规则与这篇关于 JavaScript 的帖子.(在你对问题的一条评论中链接到)中提到的约束有些类似:JavaScript 对象定义和函数参数列表都不能两次定义相同的标识符,这也是一条既明显具有上下文相关性又明显属于语法层面的规则。
In addition, many languages require non-context-free transformations prior to the parse; these transformations are as much part of the grammar of the language as anything else. For example:
此外,许多语言在解析之前需要进行非上下文无关的转换;这些转换与语言语法的其他部分一样重要。例如:
- Layout sensitive block syntax, as in Python, Haskell and many data description languages. (Context-sensitive because parsing requires that all whitespace prefixes in a block be the same length.)
- 像 Python、Haskell 和许多数据描述语言那样的对布局敏感的块语法。(具有上下文相关性,因为解析要求块中所有的空白前缀长度相同。)
- Macros, as in Rust, C-family languages, Scheme and Lisp, and a vast number of others. Also, template expansion, at least in the way that it is done in C++.
- 如 Rust、C 系列语言、Scheme 和 Lisp 等许多语言中的宏。还有模板展开,至少在 C++ 中的实现方式是这样。
- User-definable operators with user-definable precedences, as in Haskell, Swift and Scala. (Scala doesn’t really have user-definable precedence, but I think it is still context-sensitive. I might be wrong, though.)
- 像 Haskell、Swift 和 Scala 那样允许用户定义运算符及其优先级。(Scala 实际上没有用户可定义的优先级,但我认为它仍然具有上下文相关性。不过我可能错了。)
None of this in any way diminishes the value of context-free parsing, neither in practical nor theoretical terms. Most parsers are and will continue to be fundamentally based on some context-free algorithm. Despite a lot of trying, no-one yet has come up with a grammar formalism which is both more powerful than context-free grammars and associated with an algorithm for transforming a grammar into a parser without adding hand-written code. (To be clear: the goal I refer to is a formalism which is more powerful than context-free grammars, so that it can handle constraints like “variables must be declared before they are used” and the other features mentioned above, but without being so powerful that it is Turing complete and therefore undecidable.)
无论从实践还是理论角度来看,这些都丝毫不会降低上下文无关解析的价值。大多数解析器过去是、将来也会继续从根本上基于某种上下文无关算法。尽管人们做了很多尝试,但还没有人提出一种语法形式,它既比上下文无关语法更强大,又能关联一种无需添加手写代码就能将语法转换为解析器的算法。(明确地说:我所指的目标是一种比上下文无关语法更强大的形式,这样它就能处理像“变量在使用前必须声明”这样的约束以及上述提到的其他特性,但又不会强大到成为图灵完备的,从而导致不可判定。)
Notes
- Excluding rules which cannot be implemented in a context-free grammar in order to say that the language is context-free strikes me as a most peculiar way to define context-freeness. Of course, if you remove all context-sensitive aspects of a language, you end up with a context-free superset, but it’s no longer the same language.
为了说一种语言是上下文无关的而排除那些无法用上下文无关语法实现的规则,在我看来,这是一种非常奇特的定义上下文无关性的方式。当然,如果你去除一种语言的所有上下文相关方面,最终会得到一个上下文无关的超集,但这就不再是同一种语言了。
edited May 11, 2021 at 22:59
answered May 8, 2021 at 22:41 rici
FWIW, I’ve seen claims that the C++ grammar is undecidable, even if I never found a proof for that. Template metaprogramming, being Turing powerful, does make type checking undecidable, but I don’t know if it also interferes with parsing that much to make it undecidable as well.
顺便说一下,我曾看到有人声称 C++ 语法是不可判定的,尽管我从未找到相关证明。模板元编程具有图灵完备性,确实会使类型检查变得不可判定,但我不知道它是否也会对解析产生如此大的干扰,以至于使解析也变得不可判定。
– chi CommentedMay 9, 2021 at 7:59
@chi: there’s an old answer of mine on SO which shows the idea. You define a template class with a single boolean template argument and specialise the two possibilities. The specialisation on true has a public template member class named x. In the other one, the member x is an integer. Then you instantiate templ.x<42>(0). Now you need to figure out if pred is true or false in order to know whether x<42>(0) is a call to a templated constructor of member type x, or the comparison between 0 and the comparison of scalar member x with 42.
@奇:我在 Stack Overflow 上有一个旧回答展示了这个思路。你定义一个带有单个布尔模板参数的模板类,并对两种可能情况进行特化。特化为 true 时,有一个名为 x 的公共模板成员类。在另一种情况下,成员 x 是一个整数。然后你实例化 templ.x<42>(0)。现在你需要弄清楚 pred 是 true 还是 false,才能知道 x<42>(0) 是对成员类型 x 的模板构造函数的调用,还是 0 与标量成员 x 和 42 的比较结果的比较。
– rici CommentedMay 9, 2021 at 8:17
Or you can leave out the 0. Then it’s well-formed if pred is true and a syntax error if it’s false. In any case, the parse is determined by the compile time evaluation of pred; if that’s undecidable, so is the parse.
或者你可以省略 0。那么如果 pred 为 true,它就是格式良好的;如果为 false,就是语法错误。无论如何,解析结果取决于 pred 在编译时的求值;如果这个求值是不可判定的,那么解析也是不可判定的。
– rici CommentedMay 9, 2021 at 8:19
Great answer. Similar remarks hold about how the word “regular expressions” are used in practical programming languages. They go beyond literal regular expressions but have enough basic similarity to justify the terminology.
回答得很棒。关于“正则表达式”这个词在实际编程语言中的使用也有类似的情况。它们超出了字面意义上的正则表达式,但有足够的基本相似性来证明这个术语的合理性。
– John Coleman CommentedMay 9, 2021 at 11:38
@gnasher729: pretty well any language can be parsed by first transforming the input using a context free transducer and then passing the result through an ad hoc computation performed by Turing complete mechanism. That makes the cfg useful. But it doesn’t make the language context-free. A language is context free iff you can determine whether or not a sentence is part of the language using a PDA. This question is tagged formal-languages and in that context, Swift is not a context-free language. That’s not a criticism of Swift nor does it say cfg parsing is pointless. It’s just a fact.
@gnasher729:几乎任何语言都可以通过首先使用上下文无关转换器对输入进行转换,然后将结果通过图灵完备机制进行的临时计算来解析。这使得上下文无关文法很有用。但这并不意味着该语言是上下文无关的。当且仅当你可以使用下推自动机(PDA)来确定一个句子是否属于该语言时,该语言才是上下文无关的。这个问题被标记为形式语言,在这个语境下,Swift 不是上下文无关语言。这不是对 Swift 的批评,也不是说上下文无关文法解析毫无意义。这只是一个事实。
– rici CommentedMay 10, 2021 at 13:56
The boundary between context-free and context-sensitive is only determined by one thing: whether or not it can be decided with a nondeterministic pushdown automata.
上下文无关和上下文相关之间的界限仅由一件事决定:是否可以用非确定性下推自动机来判定。
With respect to grammar specifically, most practical programming languages are almost context-free if not context-free, but the context-free/context-sensitive distinction isn’t nearly as important as the ease of parsing. It’s possible to create a context-free language that is difficult to parse or is ambiguous, and it is also possible to create a context-sensitive language that is easy to parse. Remember, the computers we use to parse programming languages are functionally equivalent to Turing machines (if given infinite memory) and are limited by the fact that they are deterministic. The determinism is the practical limiting factor that informs our choice in grammars that programming languages will use, so the boundary between context-free and context-sensitive is less practically interesting than the boundary between deterministic and nondeterministic.
具体就语法而言,大多数实用的编程语言即使不是上下文无关的,也几乎是上下文无关的,但上下文无关/上下文相关的区别远不如解析的难易程度重要。有可能创建一种难以解析或有歧义的上下文无关语言,也有可能创建一种易于解析的上下文相关语言。请记住,我们用于解析编程语言的计算机在功能上等同于图灵机(如果有无限内存),并且受限于它们是确定性的这一事实。这种确定性是实际的限制因素,它影响着我们对编程语言所使用的语法的选择,因此上下文无关和上下文相关之间的界限在实际中不如确定性和非确定性之间的界限有趣。
L
L
k
LL_k
LLk and
L
A
L
R
k
LALR_k
LALRk grammars form specific subsets of deterministic context-free grammars that can be parsed with generated tables within programs that simulate a deterministic pushdown automaton (which is less powerful than a nondeterministic one).
L
L
k
LL_k
LLk 和
L
A
L
R
k
LALR_k
LALRk 文法构成了确定性上下文无关文法的特定子集,这些子集可以在模拟确定性下推自动机(其能力比非确定性下推自动机弱)的程序中使用生成的表进行解析。
On the other hand, PEG grammars have a handful of features that technically fall under the context-sensitive umbrella, however they can be parsed in linear time* with generated code, which outperforms generalized nondeterministic context-free parsing (The best known algorithm for CFGs is somewhere between quadratic and cubic time. This class of grammars includes certain obscure features that are technically context-free but are hard to parse- I don’t know of any examples off the top of my head). PEGs have become quite popular for modern languages, and even Python has adopted its use for upcoming versions and new languages such as Zig have been using them from the beginning.
另一方面,PEG(解析表达式文法)有一些在技术上属于上下文相关范畴的特性,然而它们可以使用生成的代码在线性时间内解析*,这比广义的非确定性上下文无关解析性能更好(已知的上下文无关文法的最佳算法时间复杂度在二次到三次之间。这类文法包含一些在技术上是上下文无关但难以解析的晦涩特性——我一时想不出任何例子)。PEG 在现代语言中变得相当流行,甚至 Python 在即将推出的版本中也采用了它,像 Zig 这样的新语言从一开始就使用它。
Having a “more powerful” grammar doesn’t matter at all for the power of a programming language because the computing model they represent can simulate a Turing machine. In fact, it’s often the opposite because “more powerful” grammars tend to be more difficult to parse and are therefore less friendly to both machines and computers (and slower to compile). C++ is a particularly notorious offender in this realm, with templates (and how they are expanded) having the ability to affect the parse tree. In fact, C++ is not even decidable because templates are Turing complete.
拥有“更强大”的语法对于编程语言的能力来说根本无关紧要,因为它们所代表的计算模型都可以模拟图灵机。实际上,情况往往相反,因为“更强大”的语法往往更难解析,因此对机器和程序员都不太友好(编译速度也更慢)。C++ 在这方面是一个特别臭名昭著的例子,模板(及其展开方式)能够影响解析树。事实上,C++ 甚至是不可判定的,因为模板是图灵完备的。
*: Technically, there are some pathological cases that can cause catastrophic backtracking and explode the parsing to exponential time, however for most useful grammars and programs, this is not an issue. In addition, since PEG parsers typically cache intermediate parsing results, two rules that only differ slightly will not cause a tremendous amount of backtracking in order to properly select the correct rule, and smart code generators can mitigate the worst backtracks.
*: 从技术上讲,存在一些极端情况会导致灾难性的回溯,使解析时间呈指数级增长,但对于大多数实用的语法和程序来说,这不是问题。此外,由于 PEG 解析器通常会缓存中间解析结果,只有细微差异的两条规则不会为了正确选择规则而导致大量的回溯,而且智能的代码生成器可以减轻最严重的回溯问题。
edited Oct 16, 2023 at 17:20
answered May 11, 2021 at 18:29 Beefster
In conclusion, the concept of context in programming encompasses a wide range of meanings and applications. From the execution context that determines the symbols and their values reachable from a given point in code, to the various forms of context in different programming scenarios like request contexts, graphics contexts, and more.
总之,编程中的“上下文”概念涵盖了广泛的含义和应用。从决定代码中某一特定点可访问的符号及其值的执行上下文,到不同编程场景下的各类上下文形式,如请求上下文、图形上下文等等。
Understanding context is crucial for writing modular, maintainable code. It helps in managing the state and dependencies of different parts of a program, and in ensuring that operations are carried out correctly within the appropriate environment.
理解上下文对于编写模块化、可维护的代码至关重要。它有助于管理程序不同部分的状态和依赖关系,并确保操作在合适的环境中正确执行。
When it comes to the question of whether programming languages are context-free or context-sensitive, the answer is not straightforward. While some simple languages or subsets of languages can be described by context-free grammars, most modern programming languages with their complex features such as user-defined types, macros, templates, and dynamic operator precedence are in fact context-sensitive.
当谈及编程语言是无上下文的还是上下文相关的这个问题时,答案并非一目了然。虽然一些简单的语言或语言的子集可以用无上下文语法来描述,但大多数具有复杂特性(如用户定义类型、宏、模板和动态运算符优先级)的现代编程语言实际上是上下文相关的。
This complexity reflects the power and flexibility of modern programming languages, but also poses challenges in terms of parsing, compilation, and understanding the behavior of programs. By being aware of the role of context and the nature of language grammars, programmers can make more informed decisions and write better code that adheres to the requirements and constraints of the programming environment.
这种复杂性既体现了现代编程语言的强大功能和灵活性,也在解析、编译以及理解程序行为方面带来了挑战。通过了解上下文的作用和语言语法的性质,程序员能够做出更明智的决策,并编写出更符合编程环境要求和约束的优质代码。
via:
-
揭秘 Context(上下文)_context 上下文 - CSDN 博客
https://blog.csdn.net/qq_39969226/article/details/88324722 -
关于 Context(上下文)的理解_c++ context - CSDN 博客
https://blog.csdn.net/u013196348/article/details/94395205 -
到底什么是上下文(Context) - CSDN 博客
https://blog.csdn.net/caizir913/article/details/108826764 -
【操作系统】进程上下文和线程上下文_如何理解操作系统的上下文 - CSDN 博客
https://blog.csdn.net/qq_56914146/article/details/124145153 -
language agnostic - The term “Context” in programming?
https://stackoverflow.com/questions/6145091/the-term-context-in-programming -
compiler theory - What programming languages are context-free?
https://stackoverflow.com/questions/898489/what-programming-languages-are-context-free -
Are modern programming languages context-free?
https://cs.stackexchange.com/questions/140078/are-modern-programming-languages-context-free


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









