







第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器
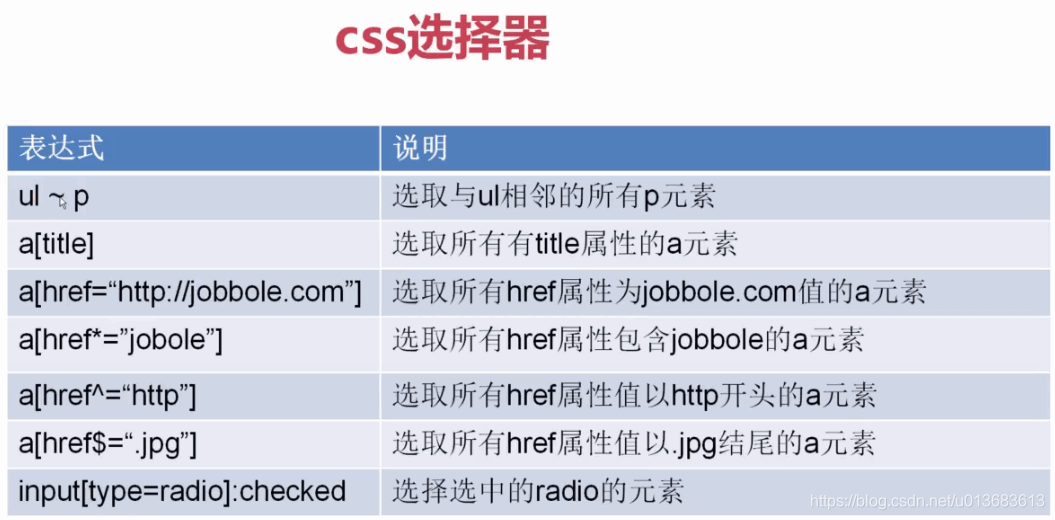
1、

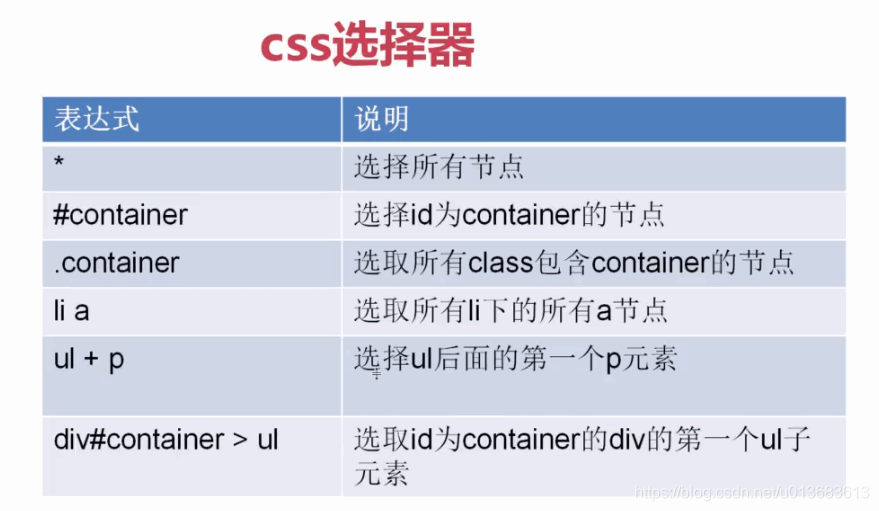
2、
3、
::attr()获取元素属性,css选择器
::text获取标签文本
举例:
extract_first(’’)获取过滤后的数据,返回字符串,有一个默认参数,也就是如果没有数据默认是什么,一般我们设置为空字符串
extract()获取过滤后的数据,返回字符串列表
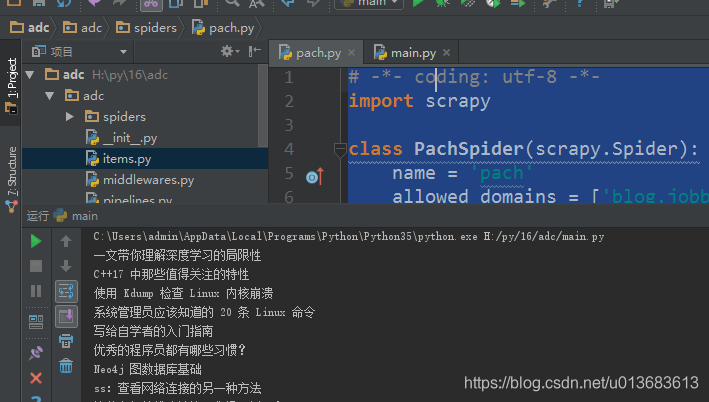
-- coding: utf-8 --
import scrapy
class PachSpider(scrapy.Spider):
name = ‘pach’
allowed_domains = [‘blog.jobbole.com’]
start_urls = [‘http://blog.jobbole.com/all-posts/’]
def parse(self, response):
asd = response.css('.archive-title::text').extract() #这里也可以用extract_first('')获取返回字符串
# print(asd)
for i in asd:
print(i)
转载目的:形成完整的学习笔记,备查回溯















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









