







pandas详解可参考:http://pandas.pydata.org/pandas-docs/stable/10min.html
对应的中文译文:http://www.cnblogs.com/chaosimple/p/4153083.html
在这里对我近期用到的几个函数做一些记录与解析,若有使用不当之处望大家指出
date_range
这个函数的作用是创建一个时间序列的索引,其原型为:
pandas.data_range(start=None, end=None, periods=None, freq=’D’, tz=None, normalize=False, name=None, closed=None, **kwargs)| 参数 | 意义 |
|---|---|
| start | string类型,默认为None,表示时间起点 |
| end | 同上,表示时间终点 |
| periods | int类型,默认为None,表示日期索引个数。若为None,则start和end不能为空 |
| freq | string类型,默认为‘D’,表示计时单位(frequence),例如‘D’表示每隔1天,‘3H’表示每隔3小时 |
| tz | string类型,表示时区,默认为None |
| normalize | bool类型, 默认为False,若为True,则将强行将start和end转化为当天的0点 |
| name | string类型,给返回的时间索引值一个name |
| closed | string类型,默认为None,表示start和end这个区间的端点是否包含在内,‘left’表示左闭右开,‘right’表示右闭左开,None则表示两边都为闭区间 |
举例:

这里将freq设为5H,则每隔5小时计算一次,共periods=12次
再如下图的比较:
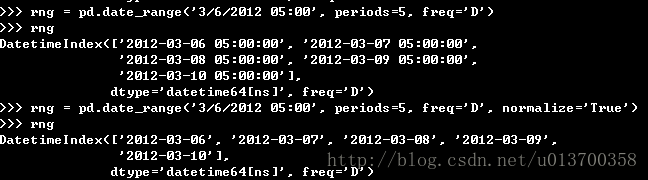
第二段将normalize设为True,则默认从当天0点计时,并不会有时分秒的显示
另外有点困惑:是否只能freq=’D’的时候才能看出normalize的差别?当我将其设为’H’时并没有明显的变化。
Series
Series是一个一位数组的结构,分为索引值(index)和对应的数据。其函数原型:
pandas.Series(data, index=index)若不指定index范围,则会默认从0开始计数,也可以人为对index进行指定,第三则可通过构建字典来创建Series对象,具体的使用方法都可见下图:
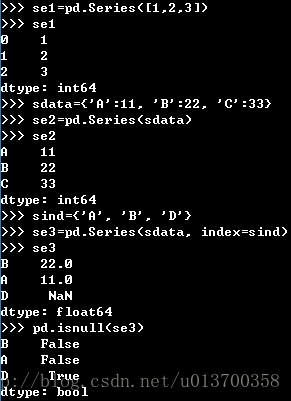
最后的isnull函数是用来判断在字典中是否存在索引值对应的值,存在返回False,不存在则返回True
但我这里不知道为什么在输出se3的时候是先输出B,然后才是A?
Timestamp
最后还有一个timestamp函数,用于转换日期格式
例如数字生成日期:
pd.Timestamp(datetime(2017, 3, 8))字符生成日期:
pd.Timestamp('2017-03-08')都可在前文提到的10 Minutes to pandas中找到。















 857
857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









