







上一篇文章中,我们分析了ipcbinder框架的基本原理,简要的说就是我们client端的binder向BD写入数据,然后BD再向server端传递数据,那么问题来了,这中间是不是发生了两次数据拷贝呢?
这个问题比较深刻,然而事实也比较深刻,只有一次数据拷贝,这是google对binder做了一次优化的结果,一次的拷贝发生在client向BD的数据拷贝,那么server如果不从BD中拷贝数据,它又怎么可以接收到数据呢,不要忘了,我们linux的内核有一种叫做技能叫做内存映射mmap(),先上个原理图分析下:
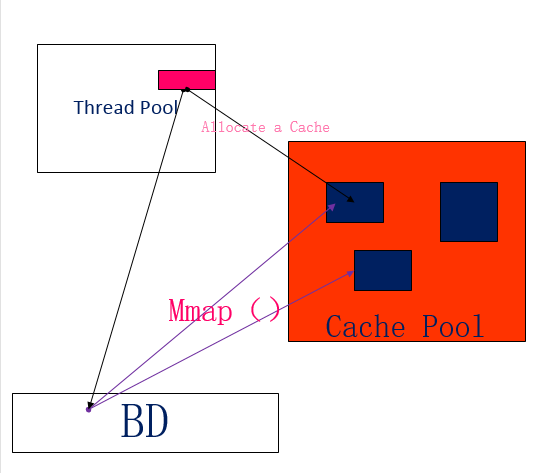
事实上,linux中并没有用户空间直接往用户空间拷贝的做法,一般都是需要通过内核空间作为中转站,首先在server端,会有一个缓存池,专门用来存放线程们接受来的数据,缓存池必须要足够大,不然溢出什么的造成的数据包丢失后果想想就可怕,BD作为驱动,在linux内核层中是以一个文件节点存在,挂在“dev/binder”文件节点中,当然这个是需要用代码来操作的,这个等下详细分析,内核中代码通过文件描述符:
d = open("/dev/binder", O_RDWR);就可以连接驱动,再看看通过mmap()系统调用做了什么:
mmap(NULL, MAP_SIZE, PROT_READ, MAP_PRIVATE, fd, 0);这个函数映射了一块MAP_SIZE大小的内存空间,就是在server端的缓存池,PROT_READ参数说明这个空间为可读类型,由于这个函数完成了从内核空间到用户空间的映射,所以缓存池空间是由驱动管理的,用户并不能进行写操作,故为只读类型,接受到数据包后,解析完消息头,就会解析data中buffer,即消息主体的指针,这个指针必须指向缓存池中的一个合法地址,如果指针越界那这消息就白发送了,这块空间也变的无法管理了,接收方的线程会根据数据包的大小在缓存池中分配一块最合适的空间,比较合理的利用内存碎片。
所以这个过程比较神奇,先是调用copy_from_user() 函数把数据包从client端拷贝到内核空间(BD),由于mmap()完成了内核空间到server端用户空间的映射,所以这一次拷贝等效于直接拷贝进了server端的用户空间,在server端的缓存池直接可以进行空间分配,无需再来一次内核空间到用户空间的拷贝。所以,binder优化之后只需要一次数据拷贝~
上一篇对于processState类的分析不够深入,这里继续深入分一下这个类到底干了什么,首先看看它的构造函数:
ProcessState::ProcessState()
//连接驱动,获得文件节点描述符
: mDriverFD(open_driver())
//内存映射的起始地址
, mVMStart(MAP_FAILED)
, mThreadCountLock(PTHREAD_MUTEX_INITIALIZER)
, mThreadCountDecrement(PTHREAD_COND_INITIALIZER)
, mExecutingThreadsCount(0)
//线程池最大工作线程数
, mMaxThreads(DEFAULT_MAX_BINDER_THREADS)
, mManagesContexts(false)
, mBinderContextCheckFunc(NULL)
, mBinderContextUserData(NULL)
, mThreadPoolStarted(false)
, mThreadPoolSeq(1)
{
if (mDriverFD >= 0) {
// mmap the binder, providing a chunk of virtual address space to receive transactions.
mVMStart = mmap(0, BINDER_VM_SIZE, PROT_READ, MAP_PRIVATE | MAP_NORESERVE, mDriverFD, 0);
if (mVMStart == MAP_FAILED) {
// *sigh*
ALOGE("Using /dev/binder failed: unable to mmap transaction memory.\n");
close(mDriverFD);
mDriverFD = -1;
}
}
LOG_ALWAYS_FATAL_IF(mDriverFD < 0, "Binder driver could not be opened. Terminating.");
}构造函数暴露了这个类的主要职责,就是负责binder(CS两端的Binder对象都是它)跟BD的通信,上面所说的binder优化内存映射也是这个类负责的,我们首先看看初始化列表,首先打开驱动设备并进行连接,然后
mVMStart成员设定了进行内存映射的起始地址以及初始值,当mmap()没能执行成功时,就进行aloge报错,关闭驱动连接,成功了就说明设备文件节点成功映射到了server端的缓存池,看来ipc对接收方的要求还是有点高,又是映射缓存池又是最佳匹配空间,深表同情~~
回想一下,通信的前提是cilent需要有一个BpBinder对象,来完成向BD的数据拷贝,也是构造本地代理接口对象(proxy)的参数,那么我们通过SM等手段获取远程进程的handle之后,怎么构造BpBinder对象呢,这还是processState对象的功劳,这个的实现在一个并不复杂的函数里,看下代码:
sp<IBinder> ProcessState::getStrongProxyForHandle(int32_t handle)
{
sp<IBinder> result;
//安全锁就不多说了,这里有线程池。。。肯定需要锁
AutoMutex _l(mLock);
//BpBinder对象聚合在handle_entry类里面,e->binder
handle_entry* e = lookupHandleLocked(handle);
if (e != NULL) {
// We need to create a new BpBinder if there isn't currently one, OR we
// are unable to acquire a weak reference on this current one. See comment
// in getWeakProxyForHandle() for more info about this.
IBinder* b = e->binder;
//如果此时并没BpBinder对象而且连弱引用都没有
if (b == NULL || !e->refs->attemptIncWeak(this)) {
//handle=0就是跟SM(context manager)的通信了,这个
//context manager对象有点不一样,本质上,它也是一个binder
//然而它的handle一定为0,从来未被模仿,所以不需要保证handle
//的引用存在,而且这个对象肯定是需要在我们获得本地binder之前
//构造,不然我们不知道远程进程的handle。
if (handle == 0) {
//数据打包
Parcel data;
//线程池调用可用线程向BD拷贝数据
//PING_TRANSACTION作为命令参数告诉sm我是想看看
//我的通信目标是否存在。
//反正sm的本地代理接口对象也会这么干,我这里提前
//一步ping一下~
status_t status = IPCThreadState::self()->transact(
0, IBinder::PING_TRANSACTION, data, NULL, 0);
if (status == DEAD_OBJECT)
return NULL;
}
//就在这里构造了BpBinder
b = new BpBinder(handle);
e->binder = b;
if (b) e->refs = b->getWeakRefs();
result = b;
} else {
// This little bit of nastyness is to allow us to add a primary
// reference to the remote proxy when this team doesn't have one
// but another team is sending the handle to us.
result.force_set(b);
e->refs->decWeak(this);
}
}
return result;
}对于handle为0的情况,起始BpBinder是可以直接以handle=0构造的,在作为参数构造出BpServiceManager对象,就可以在本地完成sm的一切操作了比如service偶尔作为client端向sm注册服务,当然内部还是通过transact()函数,来看看注册服务的代码:
virtual status_t addService(const String16& name, const sp<IBinder>& service,bool allowIsolated)
{
//数据打包
Parcel data, reply;
data.writeInterfaceToken(IServiceManager::getInterfaceDescriptor());
//服务的name键值,用于sm服务的查找
data.writeString16(name);
data.writeStrongBinder(service);
data.writeInt32(allowIsolated ? 1 : 0);
//获得BpBinder指针,然后调用transact()函数
status_t err = remote()->transact(ADD_SERVICE_TRANSACTION, data, &reply);
return err == NO_ERROR ? reply.readExceptionCode() : err;
}我们知道这个类父类继承了BpBinder,而BpBinder继承自RefBase引用基类,通过基类函数remote()可以获得父类实例指针,然后调用transact()通过ADD_SERVICE_TRANSACTION 的命令参数向BD发送数据就完成了跟sm的通信。
我们留意到,在代码里多次出现了self()函数,我们来看看它的代码:
sp<ProcessState> ProcessState::self()
{
//安全锁
Mutex::Autolock _l(gProcessMutex);
//不会重复构造对象实例
if (gProcess != NULL) {
return gProcess;
}
gProcess = new ProcessState;
return gProcess;
}很明显可以发现,这个processState跟IPCThreadState 对象殊途同归,都是单例模式,如果是单例,肯定会管理所有的binder对象,所以,它会维护一个handle_entry的vector<>,这就意味着binder的复用,这对于多次的数据交换肯定是必要的,binder聚合在一个名叫handle_entry 类中,是可以以handle为key进行查找的,这个也是processState实现的,代码如下:
ProcessState::handle_entry* ProcessState::lookupHandleLocked(int32_t handle)
{
const size_t N=mHandleToObject.size();
//直接以handle为key
if (N <= (size_t)handle) {
handle_entry e;
e.binder = NULL;
e.refs = NULL;
//如果没有这个binder,就创建一个handle_entry 对象
//插入到vector的后面
status_t err = mHandleToObject.insertAt(e, N, handle+1-N);
if (err < NO_ERROR) return NULL;
}
return &mHandleToObject.editItemAt(handle);
}其实这个函数实现更像一个以handle直接为索引的哈希表,vector为bucket。
processState类的功能分析的差不多了,基本就是负责跟BD的数据发送,BpBinder调用它的transact()函数,它调用线程池可用线程,通过IPCThreadState 对象再写入数据到BD:
为了完成使命,ProcessState 中有 2 个比较关键 Parcel 成员, mIn 和 mOut , Pool thread 会不停的查询 BD 中是否有数据可读,如果有将其读出并保存到 mIn ,同时不停的检查 mOut 是否有数据需要向 BD 发送,如果有,则将其内容写入到 BD 中,总而言之,从 BD 中读出的数据保存到 mIn ,待写入到 BD 中的数据保存在了 mOut 中,这其中满满的都是可怕的轮询操作,真是辛苦她了。。。
我们可以来看看其中的一个轮询操作,就是mIn不断轮询BD有没有来自server端的reply数据的函数:
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
uint32_t cmd;
int32_t err;
//这是一个轮询操作
while (1) {
//不断检测轮询BD有没有返回的数据
if ((err=talkWithDriver()) < NO_ERROR) break;
//错误检测
err = mIn.errorCheck();
if (err < NO_ERROR) break;
//还没有数据被写入BD,接收方跟BD已经进行了内存映射
//继续轮询
if (mIn.dataAvail() == 0) continue;
//接收到来自server的数据,解析命令参数
cmd = (uint32_t)mIn.readInt32();
IF_LOG_COMMANDS() {
alog << "Processing waitForResponse Command: "
<< getReturnString(cmd) << endl;
}
switch (cmd) {
//本次接收会话结束
case BR_TRANSACTION_COMPLETE:
if (!reply && !acquireResult) goto finish;
break;
//binder死亡,会话毫无意义。。。
case BR_DEAD_REPLY:
err = DEAD_OBJECT;
goto finish;
//接收失败提示
case BR_FAILED_REPLY:
err = FAILED_TRANSACTION;
goto finish;
case BR_ACQUIRE_RESULT:
{
ALOG_ASSERT(acquireResult != NULL, "Unexpected brACQUIRE_RESULT");
const int32_t result = mIn.readInt32();
if (!acquireResult) continue;
*acquireResult = result ? NO_ERROR : INVALID_OPERATION;
}
goto finish;
//这才是关键的接收
case BR_REPLY:
{
//binder协议的规定结构类型binder_transaction_data类
binder_transaction_data tr;
//向BD读取数据包,虚拟内存vma操作即可
err = mIn.read(&tr, sizeof(tr));
ALOG_ASSERT(err == NO_ERROR, "Not enough command data for brREPLY");
if (err != NO_ERROR) goto finish;
if (reply) {
//如果是应答模式,接收的数据会在缓存池的映射空间进行内存分配。
if ((tr.flags & TF_STATUS_CODE) == 0) {
//接收线程解析tr.data.ptr字段为server返回的binder实体的指针
//reinterpret_cast强行指针转换,转换为binder实体,binder作为ipc
//的唯一token。
reply->ipcSetDataReference(
//binder实体的起始地址。
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
//binder实体的基址偏移量。
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t),
freeBuffer, this);
} else {
err = *reinterpret_cast<const status_t*>(tr.data.ptr.buffer);
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), this);
}
} else {
//ipc没有需要,可以释放掉缓存池的空间,以便回收利用。
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), this);
//继续进行下一个会话的轮询
continue;
}
}
goto finish;
default:
//在这里执行解析的命令参数
err = executeCommand(cmd);
if (err != NO_ERROR) goto finish;
break;
}
}
finish:
//错误处理
if (err != NO_ERROR) {
if (acquireResult) *acquireResult = err;
if (reply) reply->setError(err);
mLastError = err;
}
return err;
}其实经过内存映射后,接收方会跟BD进行一块物理内存的共享,这个下一篇会深入分析,也就是轮询自己的vm也是可以的。reinterpret_cast这个强行转换为binder实体安全也足够体现了C++指针的粗暴。。。
我们最后来详细分析一下线程的等待机制,首先一个进程里面里面一共有三种队列,一个是全局接收队列(to-do),专门用来接受没有指定发往哪个线程的数据包,一个是全局等待线程队列,所有等待接收数据包的线程都会在这里排队,在数据队列中找到属于自己数据包,放到自己的私有队列中进行处理,每一个线程都有自己的私有队列,属于这个线程处理的线程都会在这个队列中排队等着自己命中注定的数据包,这个逻辑比较奇特,属于自己的任务就是自己处理的啊,所以不会有其他线程这么仁慈来帮你处理本来属于你的任务,所以按照这个逻辑,每一个线程的私有队列中有且仅有一个线程,那就是它自己。
具体怎么操作呢,按照一般的逻辑,client向server端的请求的数据包都会堆在server进程的全局to-do队列中,然而这样还需要从线程池中安排一个可用线程进行接单,事实上并不是这样,binder经过优化后变得聪明了一点,与其先放全局队列中,然后线程接单都转移到线程的私有队列,还不如直接选择一个可用线程,然后数据包直接投放到它的私有队列,好吧,这样看来,进程的全局队列似乎没什么用武之地了。。
这是一条潜规则,比如P1中的T1向P2发送数据包,我可以先从P2的线程池中挑选一个可用线程T2,ok,数据包直接投放到T2的私有队列中处理(其实就是由P2自己处理),然后T1也不会在P1的全局to-do队列中等待了,它必须在T1的私有队列中排队才能接收来自T2的返回数据包,不然就丢包了,因为T2给P1返回的数据同样不会投放在P1的全局等待队列让所有线程看着办,这样被别的线程抢了谁也不好受,所以也会直接投放到T1的私有队列中。
依我看,全局队列的用武之地可能会发生在异步请求上,毕竟上面binder的优化针对的是同步请求,异步请求的数据包发送之后P1也不在乎什么时候能得到回应,所以会放在P2的全局队列,谁有空就谁处理咯,对于异步,BD有一个专门为限流的字段async_todo,这是一个异步限流阻塞队列的引用,毕竟同步才是binder ipc的主流,异步的只能允许一个在P2的线程池中处理,剩下的。。。不好意思,请在BD中排队,等什么时候同步请求处理的差不多了,空闲的线程比较多再来下一个异步请求数据包,毕竟异步请求高并发的可能性还是比较大的,万一把线程池的线程耗尽了,那问题就严重了。
前面说过连接远程服务的最大贡献者sm本质上也是一个binder性质的进程,那么它是怎么被构建的,binder驱动又是完成最开始的注册,下一篇文章将会深入内核进行ipc的底层分析,~~ok,本文结束~














 3451
3451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









