最近在看机器学习实战这本书,写下博客作为笔记以帮助记忆。
主要内容
一、K-近邻算法概述
二、K-近邻算法–用于平面上的点的分类
三、K-近邻算法–用于手写数字的识别
四、归一化数值的重要性
一、K-近邻算法概述
概括的说,K-近邻算法采用测量不同特征值之间的距离的方法进行分类。
它的工作原理是:存在一个样本数据集合,也称训练样本集,并且样本集中每个数据存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中的数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,只选择样本数据集中前k个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。最后,选择最相似数据中出现次数最多的分类,作为新数据的分类。
说白了,就是将新数据和训练集中每个数据进行比较,找到距离新数据最近的K个数据,对这K个数据的标签进行统计,支持数最高的标签即可认为是新数据的标签。比如K=10,其中有9的标签是A类,1个的标签是B类,那么这个新数据的标签被认为是A。
二、K-近邻算法–用于平面上的点的分类
1.分析数据:
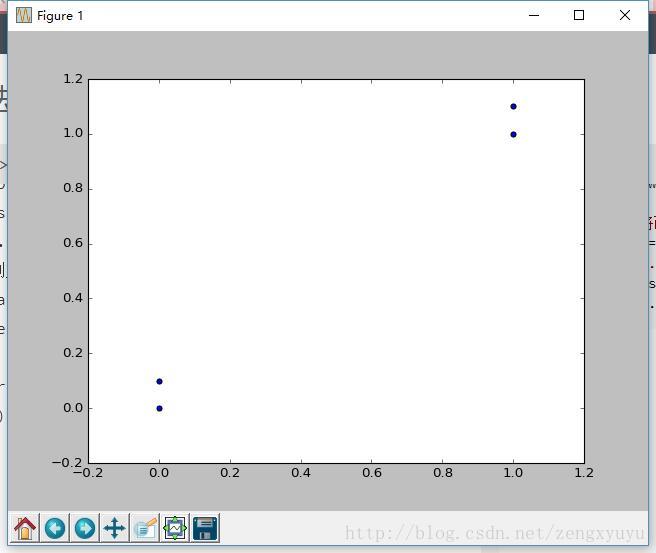
使用matplotlib创建散点图,目的是为了更好的观察数据。
我们使用这些数据
[[1.0,1.1],[1.0,1.0],[0.0,0.0],[0.0,0.1]]
标签分别为
[‘A’,’A’,’B’,’B’]
def createDataset():
group = array([[1.0,1.1],[1.0,1.0],[0.0,0.0],[0.0,0.1]])
labels = ['A','A','B','B']
return group,labels
def draw(xs,ys):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xs, ys)
plt.show()
if __name__ == "__main__":
group,label = createDataset()
draw(group[:,0],group[:,1])
得到下图
2.实施KNN算法
(1)伪代码如下:
对未知类别属性的数据集中每个点依次执行一下操作:
①计算已知类别数据集中的点与当前点之间的距离
②按照距离递增次序排序
③选取与当前点距离最小的K个点
④确定前K个点所在类别出现的频率
⑤返回前K个点出现频率最高的类别作为当前点的预测分类
(2)
欧式距离公式,计算两个向量点xA和xB之间的距离
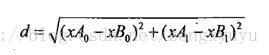
(3)代码
def classify(inX,dataset,labels,k):
datasetSize = dataset.shape[0]
diffMat = tile(inX,(datasetSize,1))-dataset
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
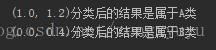
3.测试分类器
新数据(1.0, 1.2)
from numpy import *
import operator
from os import listdir
import matplotlib.pyplot as plt
def classify(inX,dataset,labels,k):
datasetSize = dataset.shape[0]
diffMat = tile(inX,(datasetSize,1))-dataset
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createDataset():
group = array([[1.0,1.1],[1.0,1.0],[0.0,0.0],[0.0,0.1]])
labels = ['A','A','B','B']
return group,labels
def firstTest():
test1 = (1.0, 1.2)
test2 = (0.0, 0.4)
dataset, labels = createDataset()
conclusion1 = classify(test1, dataset, labels, 3)
conclusion2 = classify(test2, dataset, labels, 3)
print(str(test1) + "分类后的结果是属于" + conclusion1 + "类")
print(str(test2) + "分类后的结果是属于" + conclusion2 + "类")
if __name__ == "__main__":
firstTest()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
得到的结果如下图
三、K-近邻算法–用于手写数字的识别
1.准备数据
①目录trainingdigits中包含大约2000个例子,所以数字0-9,每个数字大约有200个样本;目录testdigits中包含大约900个测试数据;我们使用目录trainingdigits中的数据训练分类器,使用目录testdigits中的数据测试分类器的效果。
②将32*32的二进制图像矩阵转换为1*1024的向量
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
linestr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(linestr[j])
return returnVect
2.测试算法
from numpy import *
import operator
from os import listdir
import matplotlib.pyplot as plt
def classify(inX,dataset,labels,k):
datasetSize = dataset.shape[0]
diffMat = tile(inX,(datasetSize,1))-dataset
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
linestr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(linestr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('digits/trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split(".")[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('digits/trainingDigits/%s' % fileNameStr)
testFileList = listdir('digits/testDigits')
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('digits/testDigits/%s' % fileNameStr)
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print("\nthe total number of errors is: %d" % errorCount)
print("\nthe total error rate is: %f" % (errorCount / float(mTest)))
if __name__ == "__main__":
handwritingClassTest()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
3.结果如下:

4.改变K的值,修改函数随机选取训练样本,改变训练样本的数目,都会对K-邻近算法的错误率产生影响
四、归一化数值的重要性
1.为什么要归一化数值?
如图:

要计算样本3和4之间的距离,可以使用下面的方法
(0−67)2+(20000−32000)2+(1.1−0.1)2−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−√
上面方程中数字差值最大的属性对计算结果的影响最大,仅仅是因为飞行常客里程数远大于其他特征值。然而我们认为这三种特征同样重要,因此作为三个等权重的特征。
2.下面的公式可以将任意取值范围的特征值转化为0到1区间内的值:
newValue = (oldValue-min)/(max-min)
3.代码
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1))
return normDataSet, ranges, minVals





















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









