







 本文探讨大数据存储系统中的Document Store,重点分析Google Protocol Buffers,一种起源于网络协议表达的数据结构,并将其与JSON进行对比。同时,提到了MongoDB如何在SQL功能基础上提供简单易用的接口。
本文探讨大数据存储系统中的Document Store,重点分析Google Protocol Buffers,一种起源于网络协议表达的数据结构,并将其与JSON进行对比。同时,提到了MongoDB如何在SQL功能基础上提供简单易用的接口。
Document Store
一、数据模型
1、 JSON:JavaScript Object Notation
JSON是一个低成本的数据交换格式;是JavaScript程序语言标准(1993年)的子集。JSON对应于程序语言中的结构与数组。
(1)JSON格式定义
Value:基础类型、Object、Array
Object:{“key1”:value1,……,”keyn”:valuen}
Array:[value1, ……, valuen]
JSON的数据类型定义是完全动态的,一个JSON记录本身自定义了自己的类型,不需要事先声明schema。
一、数据模型
1、 JSON:JavaScript Object Notation
JSON是一个低成本的数据交换格式;是JavaScript程序语言标准(1993年)的子集。JSON对应于程序语言中的结构与数组。
(1)JSON格式定义
Value:基础类型、Object、Array
Object:{“key1”:value1,……,”keyn”:valuen}
Array:[value1, ……, valuen]
JSON的数据类型定义是完全动态的,一个JSON记录本身自定义了自己的类型,不需要事先声明schema。
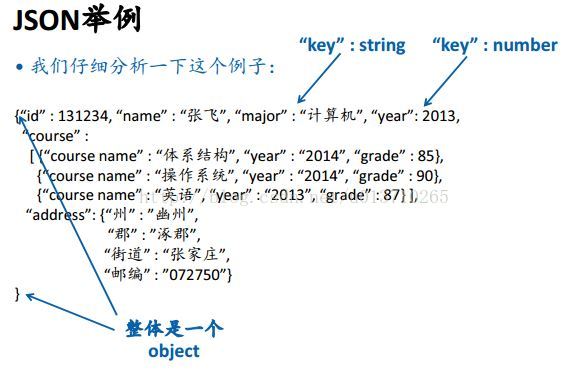
2、Google Protocol Buffers
Google推出,最初用于实现网络协议,所以叫protocol buffers。可以用于表达程序设计语言中的结构和数组。要求先定义类型,然后才可以表达数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7828
7828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









