







想要了解更多Linux 内存相关知识敬请关注:Linux内存笔记公众号,期待与大家的更多交流与学习。原创文章,转载请注明出处。
一、背景
内存allocate、reclaim的过程需要衡量当前系统内存状态,内存watermark水位就能很好的衡量系统内存状态,内存状态的划分分三个层次:HIGH、LOW、MIN。系统针对内存不同的状态就会做不同的内存行为,对系统内存状态进行管控。
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
~ # cat /proc/zoneinfo | grep -E "Node|min|low|high|managed"
Node 0, zone DMA
min 1555
low 2318
high 3081
managed 763429
Node 0, zone Normal
min 492
low 733
high 974
managed 241968
~ # cat /proc/sys/vm/min_free_kbytes
8192
二、原理
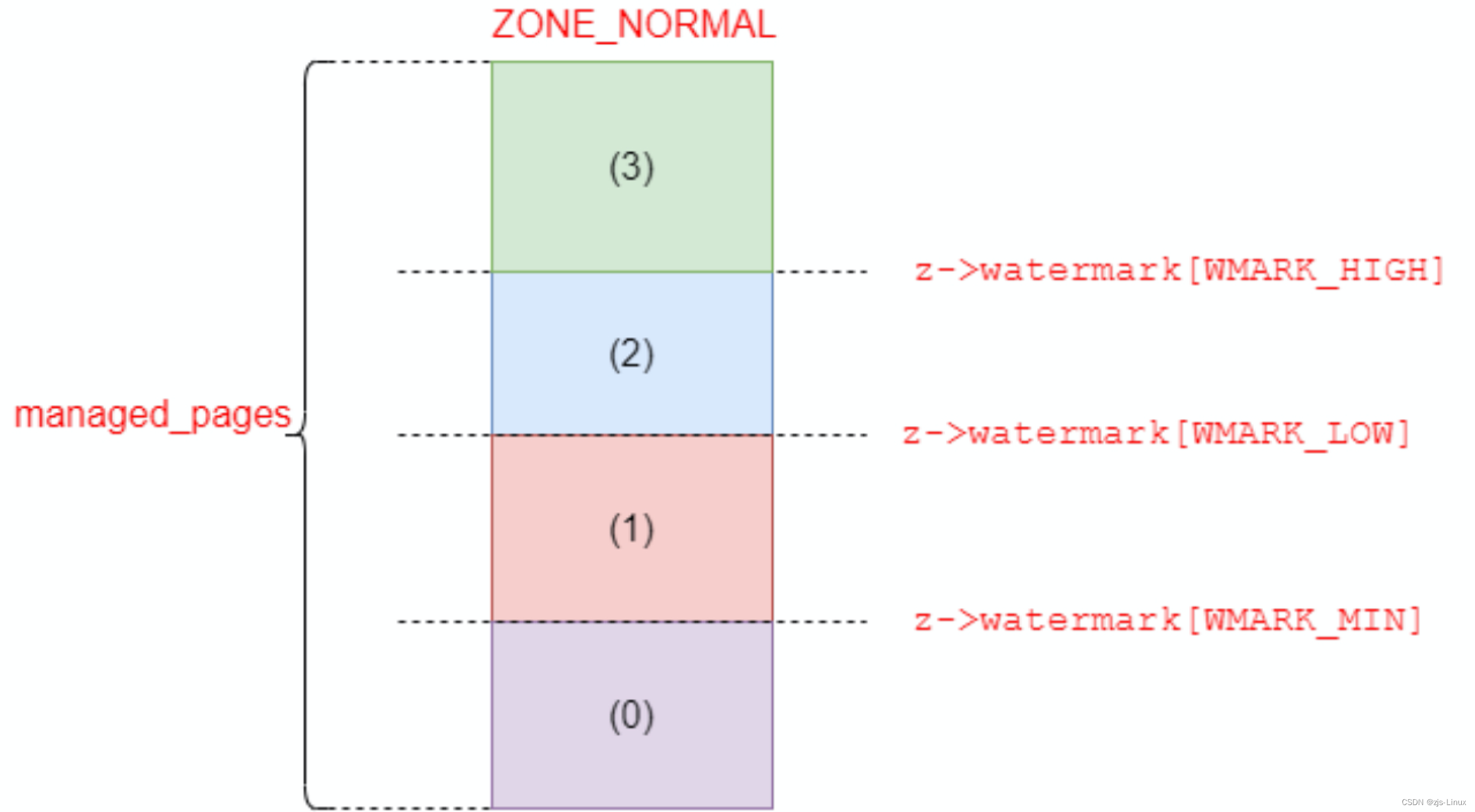
0对应water min区域;0+1对应water low区域;0+1+2对应是water high区域;0+1+2+3就是这个ZONE_NORMAL当中被buddy system管理的所有的pages也就是managed_pages。
2.1、watermark min low high
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
/*
* nr_free_buffer_pages() counts the number of pages which are beyond the high
* watermark within ZONE_DMA and ZONE_NORMAL. 也就是区域3当中内存的累加值
* 通过该参数计算出lowmem_kbytes, 进而计算出new_min_free_kbytes
* 最终计算出min_free_kbytes
*/
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
if (new_min_free_kbytes > user_min_free_kbytes) {
min_free_kbytes = new_min_free_kbytes;
...
}
...
/* 计算watermark min, low, high */
setup_per_zone_wmarks();
...
return 0;
}
static void __setup_per_zone_wmarks(void)
{
/* 通过/proc/sys/vm/min_free_kbytes 计算出page_min */
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
/* 获取Node 0当中ZONE_DMA, ZONE_NORMAL区域buddy当中管理的物理page数
* lowmem_pages = zone[DMA].managed_pages + zone[NORMAL].managed_pages */
for_each_zone(zone) {
if (!is_highmem(zone))
lowmem_pages += zone_managed_pages(zone);
}
for_each_zone(zone) {
u64 tmp;
spin_lock_irqsave(&zone->lock, flags);
/* DMA min计算:
* DMA tmp = min_free_kbytes*zone[DMA].managed_pages/4
* DMA tmp = tmp/(zone[DMA].managed_pages + zone[NORMAL].managed_pages)
*
* min_free_kbytes*zone[DMA].managed_pages
* DMA tmp = -----------------------------------------------------------
* (zone[DMA].managed_pages + zone[NORMAL].managed_pages)*4
*/
tmp = (u64)pages_min * zone_managed_pages(zone);
do_div(tmp, lowmem_pages);
if (is_highmem(zone)) {
...
} else {
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
zone->_watermark[WMARK_MIN] = tmp;
}
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
/*
* ~ # cat /proc/sys/vm/watermark_scale_factor
* 10
* 体现出了min,low,high这三者之间的关联了,通过这部分代码就计算出每个zone的三个水位值,
* tmp = tmp/4;
* tmp zone->managed_pages*watermark_scale_factor
* Max(-----------------, -----------------------------------------------------)取最大值
* 4 10000
*/
tmp = max_t(u64, tmp >> 2,
mult_frac(zone_managed_pages(zone),
watermark_scale_factor, 10000));
/*
* 如果tmp >> 2大于mult_frac(zone->managed_pages,watermark_scale_factor, 10000)就会得出如下结论:
* zone->watermark[WMARK_MIN] = zone->watermark[WMARK_MIN]
* zone->watermark[WMARK_LOW] = zone->watermark[WMARK_MIN] + zone->watermark[WMARK_MIN]/4
* zone->watermark[WMARK_HIGH] = zone->watermark[WMARK_MIN] + zone->watermark[WMARK_MIN]/2
* 这样这三个参数之间就存在了一定的比例:min:low:high = 1:1.25:1.5。
* 但是存在一个问题就是:这三个参数之间的差值太小,如果页面回收效果不好就会其启动直接内存回收模式(Direct-reclaim)
* 这样就会对系统造成较大的系统负载,所以使用max_t选择最大的值这样就可以加大min,low,high之间的差值,这样就减小了
* 直接内存内存的可能性,提高系统系能
*/
zone->watermark_boost = 0;
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
spin_unlock_irqrestore(&zone->lock, flags);
}
/* update totalreserve_pages */
calculate_totalreserve_pages();
}
演示如下:
~ # cat /proc/zoneinfo | grep -E "Node|min|low|high|managed"
Node 0, zone DMA
min 1555
low 2318
high 3081
managed 763429
Node 0, zone Normal
min 492
low 733
high 974
managed 241968
~ # cat /proc/sys/vm/min_free_kbytes
8192
~ # cat /proc/sys/vm/watermark_scale_factor
10
以ZONE_DMA区域为例:通过演示明确min, low, high三者之间的数量关系,该值会影响zone的watermark low和watermark high,而这两个值分别影响kswapd唤醒和睡眠。watermark_scale_factor默认值是10,最大值1000(5.4还是当前值,在kernel 5.15中是3000),根据代码计算可知[10,1000]表示low与min之间差值和high与low之间差值是总内存的[0.1%,10%]之间。
763429*10
mult_frac(zone_managed_pages(zone), watermark_scale_factor, 10000)) = ------------------- = 763
10000
763429*8192
zone_dma min = ------------------------------- = 1555
(763429 + 241968)*4
zone_dma low:
zone_dma min 1555
tmp = ------------------- = ------------ = 389
4 4
low = zone_dma min + 763 = 2318
zone_dma high: = zone_dma min + 763*2 = 3081
watermark_scale_factor 调节kswapd回收力度,可以增加kswapd的回收力度降低direct reclaim的发生频率降低内存回收的延迟
git show 795ae7a0de6b834a0cc202aa55c190ef81496665

2.2、watermark_boost
git show 1c30844d2dfe272d58c8fc000960b835d13aa2ac

#define pageblock_order (MAX_ORDER-1) //MAX_ORDER = 11
#define pageblock_nr_pages (1UL << pageblock_order)
/*
~ # cat /proc/sys/vm/watermark_boost_factor
15000
*/
static inline bool boost_watermark(struct zone *zone)
{
unsigned long max_boost;
...
/*
zone->_watermark[WMARK_HIGH]*watermark_boost_factor
max_boost = ----------------------------------------------------------
10000
以ZONE_DMA为例:max_boost= 3081*15000/10000 = 4622
*/
max_boost = mult_frac(zone->_watermark[WMARK_HIGH],
watermark_boost_factor, 10000);
...
/*
* pageblock_nr_pages = 1024
* max(1024, 4622) = 4622
*/
max_boost = max(pageblock_nr_pages, max_boost);
/* 取最小值作为watermark_boost */
zone->watermark_boost = min(zone->watermark_boost + pageblock_nr_pages,
max_boost);
return true;
}

可以看到当boosted enable后,wakeup_kcompactd进行内存碎片整理,一定程度上会缓解系统内存碎片化问题。
2.3、watermark application
zone的watermark判断主要依靠3个函数zone_watermark_ok、zone_watermark_ok_fast、zone_watermark_ok_safe;3个函数的调用关系如下所示
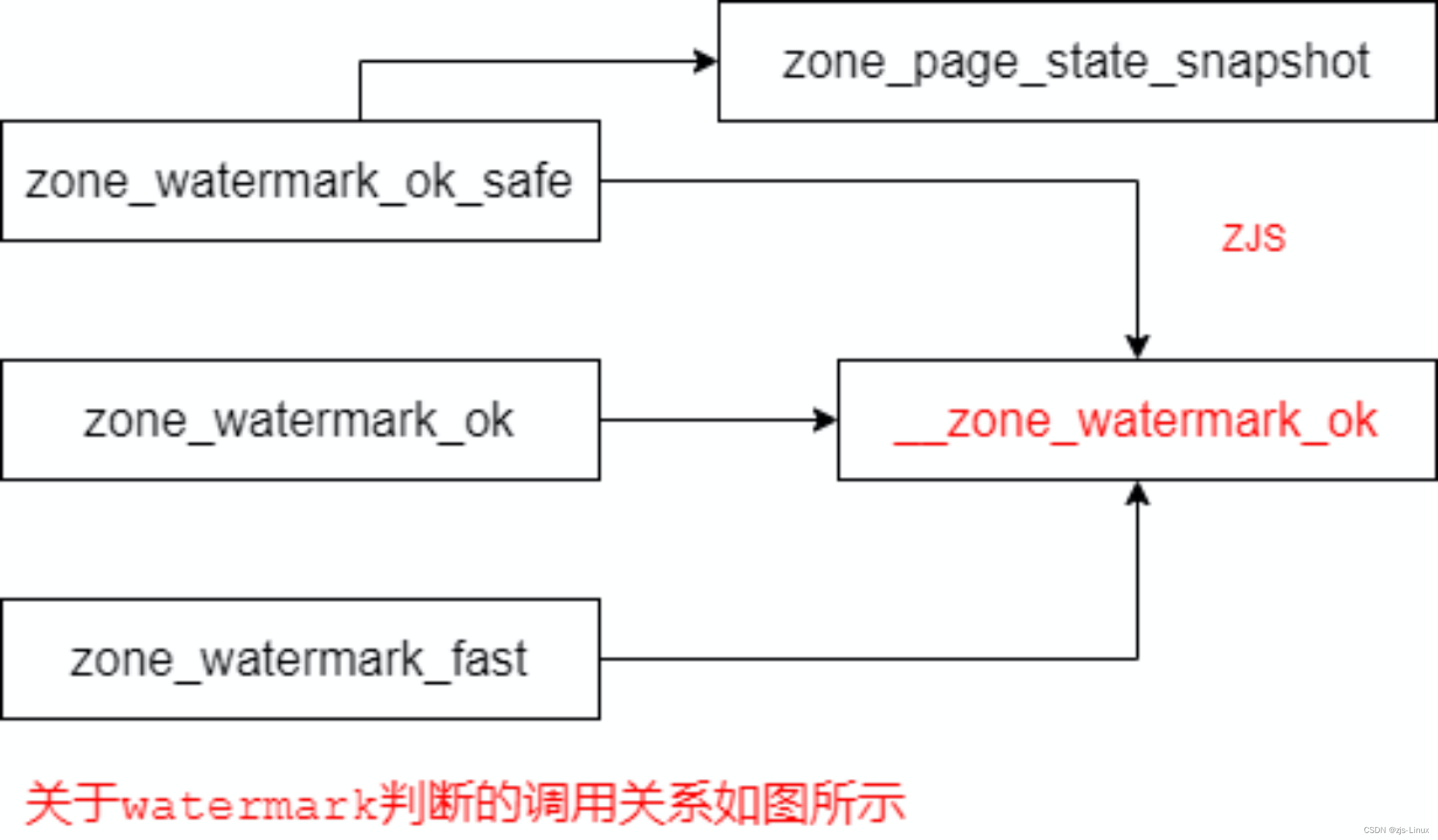
__zone_watermark_ok
**函数的核心就是判断出当前zone区域watermark与zone free_pages空闲内存的关系,如果free_pages充足时watermark_ok = true **
if (free_pages <= min + z->lowmem_reserve[highest_zoneidx])
return false;
源码详解
static inline long __zone_watermark_unusable_free(struct zone *z,
unsigned int order, unsigned int alloc_flags)
{
/* alloc_harder内存申请是否更加激进(Atomic high-priority高优先级), 通过alloc_flags与(ALLOC_HARDER|ALLOC_OOM)
* alloc_harder = true: 则allocated可以申请nr_reserved_highatomic内存
* alloc_harder = false: 则allocated不能申请nr_reserved_highatomic部分内存 */
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
/* 针对zone当中的每个order不可使用内存大小就是(2^order)-1个空间
* 以order = 2为例:2^order = 4所以在这个order阶当中不能释放3个page
*/
long unusable_free = (1 << order) - 1;
/*
* If the caller does not have rights to ALLOC_HARDER then subtract
* the high-atomic reserves. This will over-estimate the size of the
* atomic reserve but it avoids a search.
*/
/* alloc_harder = false则nr_reserved_highatomic被视作不可使用空间
* 与order不可申请部分内存累加 */
if (likely(!alloc_harder))
unusable_free += z->nr_reserved_highatomic;
#ifdef CONFIG_CMA
/* If allocation can't use CMA areas don't use free CMA pages */
/* 如果allocated无法申请cma区域内存,则通过alloc_flags与ALLOC_CMA
* 如果不能申请则将CMA FREE统计在不可能使用的区域当中 */
if (!(alloc_flags & ALLOC_CMA))
unusable_free += zone_page_state(z, NR_FREE_CMA_PAGES);
#endif
return unusable_free;
}
/*
* Return true if free base pages are above 'mark'. For high-order checks it
* will return true of the order-0 watermark is reached and there is at least
* one free page of a suitable size. Checking now avoids taking the zone lock
* to check in the allocation paths if no pages are free.
*/
/* free_pages = zone_page_state(z, NR_FREE_PAGES) */
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int highest_zoneidx, unsigned int alloc_flags,
long free_pages)
{
/* mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK]
* 所以这里min可能是high、low、min中的任何一个 */
long min = mark;
int o;
/* 通过alloc_flags与(ALLOC_HARDER|ALLOC_OOM)判断alloc_harder内存申请是否更加激进 */
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
/* free_pages may go negative - that's OK */
/* 空闲内存pages数减去不能使用的内存数,剩余的空间就是allocated实际可以申请的内存数 */
free_pages -= __zone_watermark_unusable_free(z, order, alloc_flags);
/*
* __GFP_HIGH indicates that the caller is high-priority and that granting
* the request is necessary before the system can make forward progress.
* For example, creating an IO context to clean pages.
* alloc_flages & ALLOC_HIGH = TRUE内存申请高优先级(意味着本次需要申请更多内存),将min水位减半拉低min水位;
* 降低min水位就能申请到更多的内存,free_pages - new_min(min/2)的空间就会被拉开这样allocated的申请区间就会增大。
* | |
|-------|-------> free_pages
| | |
| | |
| | |
| | |
|-------|-------> min
| | |
| | |
| | |
| | |
|-------|-------> min/2 ALLOC_HIGH
| |
| |
| |
|_______|
* 如果allocated没有高优先级(需要的申请内存相对较少), 无需腾出更多的空间供申请需要。
*/
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
if (unlikely(alloc_harder)) {
/*
* OOM victims can try even harder than normal ALLOC_HARDER
* users on the grounds that it's definitely going to be in
* the exit path shortly and free memory. Any allocation it
* makes during the free path will be small and short-lived.
*/
/* https://lore.kernel.org/all/20170810075019.28998-2-mhocko@kernel.org/T/#u
* 如果alloc_harder = true 高优先级内存申请(需要更多内存空间),将持续拉低min水位;
* alloc_flags & ALLOC_OOM = TRUR:此时内存申请优先级更高可以申请更多区域内存,
* 需要将min水位拉到原来的min - min/2 = 0.5min 进一步增大free_pages - min的操作空间
* alloc_flags & ALLOC_OOM = FALSE: 此时内存申请没有更高优先级,
* 将min水位拉低到原来的min/4, 此时当前min = (1 - 0.25) = 0.75min
* OOM victims can try even harder than normal ALLOC_HARDER (ALLOC_HARDER > ALLOC_HARDER)
* | |
|-------|-------> free_pages
| | |
| | |
| | |
| | |
|-------|-------> min
| | |
| | |
| | |
| | |
|-------|-------> new_min(min/2) ALLOC_HIGH
|-------|-------> new_min/4 ALLOC_HARDER
|-------|-------> new_min/2 ALLOC_OOM
| |
|_______|
*/
if (alloc_flags & ALLOC_OOM)
min -= min / 2;
else
min -= min / 4;
}
/*
* Check watermarks for an order-0 allocation request. If these
* are not met, then a high-order request also cannot go ahead
* even if a suitable page happened to be free.
*/
/* 想要理解这里的设计需要明确free_pages、min + z->lowmem_reserve[highest_zoneidx]这两者的含义,这点非常重要。
* min + z->lowmem_reserve[highest_zoneidx]是zone区域当中所需要的最小的内存阈值空间。
* 如果free_pages空闲内存大于最小的的阈值,则说明zone区域此时可用内存是充足的,所以此时状态为true
* 如果free_pages空闲内存小于等于最小阈值,则说明zone区域此时可用内存是不足的,素以此时状态为false
* 这里需要强调的的是当前zone的lowmem_reserve是低一级zone提供给当前zone的
* 比如ZONE_NORMAL的lowmem_reserve是ZONE_DMA提供的*/
if (free_pages <= min + z->lowmem_reserve[highest_zoneidx])
return false;
/* If this is an order-0 request then the watermark is fine */
/* 如果order = 0则说明用户申请的page都是单页,结合free page可用内存大于min加reserve预留内存只和
* 这样的背景下用户allocated申请的内存完全足够使用的,zone区域此时状态是良好的(fine) 所以直接return true */
if (!order)
return true;
/* For a high-order request, check at least one suitable page is free */
/* 水位已经确认PASS此时free page > (min + lowmem_reserve),下一步就需要针对用户申请的需求针对order
* 逐个扫描确认是否有足够的内存可供分配使用; 如果order可用内存足够则直接return true意味着watermark_ok = true */
for (o = order; o < MAX_ORDER; o++) {
struct free_area *area = &z->free_area[o];
int mt;
if (!area->nr_free)
continue;
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!free_area_empty(area, mt))
return true;
}
#ifdef CONFIG_CMA
if ((alloc_flags & ALLOC_CMA) &&
!free_area_empty(area, MIGRATE_CMA)) {
return true;
}
#endif
if (alloc_harder && !free_area_empty(area, MIGRATE_HIGHATOMIC))
return true;
}
//当前zone的free_area[]中无法找到可以满足当前order分配的内存块watermark_ok = false说明此时系统状态不好。
return false;
}
zone_watermark_fast
//tig show 48ee5f3696f6
static inline bool zone_watermark_fast(struct zone *z, unsigned int order,
unsigned long mark, int highest_zoneidx,
unsigned int alloc_flags, gfp_t gfp_mask)
{
long free_pages;
/* zone区域剩余可用内存 */
free_pages = zone_page_state(z, NR_FREE_PAGES);
/*
* Fast check for order-0 only. If this fails then the reserves
* need to be calculated.
*/
/* 当order = 0时这里就体现出了该函数的命名fast,
* usable_free = free_pages当前zone区域空闲可用内存
* 统计出order = 0前提下的unusable不可使用的内存空间,free_page = free_pages - unusable_free就是实际可用的空闲内存 */
if (!order) {
long usable_free;
long reserved;
usable_free = free_pages;
reserved = __zone_watermark_unusable_free(z, 0, alloc_flags);
/* reserved may over estimate high-atomic reserves. */
//tig show 9282012fc0aa248b77a69f5eb802b67c5a16bb13
usable_free -= min(usable_free, reserved);
/*
* mark + z->lowmem_reserve[highest_zoneidx]与__zone_watermark_ok
* 当中的min + z->lowmem_reserve[highest_zoneidx]是一样的, 代表zone区域当前zone->watermark
* 对应的所需要的最小的内存阈值空间。
* 当zone区域free_pages > zone区域当前zone->watermark对应的所需要的最小的内存阈值空间时,
* 代表此时zone区域当前zone->watermark当中order = 0的内存是充足的所以直接return true
* 不再通过__zone_watermark_ok检查1 ~ (max_order - 1)的阶,这样就极大的提高了内存状态的判断效率
* 所以就将函数命名为zone_watermark_fast
*/
if (usable_free > mark + z->lowmem_reserve[highest_zoneidx])
return true;
}
/* 检查zone区域当中order 1 ~ (max_order-1)空间确认系统内存状况是否ok,如果watermark_ok则return true否则false */
if (__zone_watermark_ok(z, order, mark, highest_zoneidx, alloc_flags,
free_pages))
return true;
...
}
zone_watermark_fast机制的引入提升了order = 0 对应page的申请效率,这就是函数描述的fast的体现

zone_watermark_ok_safe
在理解该函数时需要明确zone_page_state_snapshot的意图时什么,理解该函数的作用有利于推动我们理解zone_watermark_ok_safe
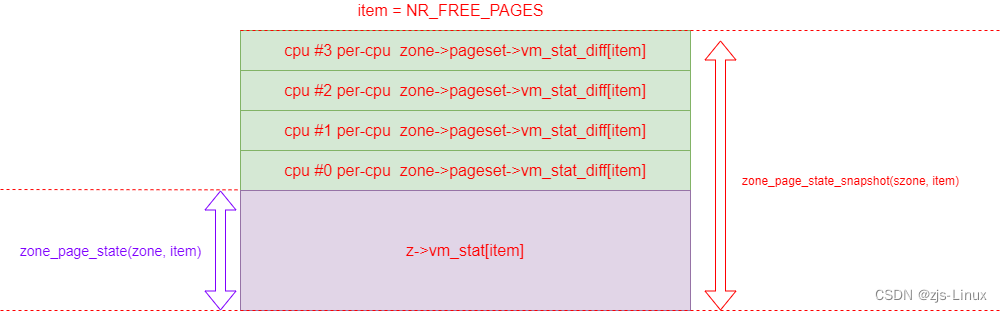
zone_page_state_snapshot
//tig show aa45484031ddee09b06350ab8528bfe5b2c76d1c
static inline unsigned long zone_page_state_snapshot(struct zone *zone,
enum zone_stat_item item)
{
long x = atomic_long_read(&zone->vm_stat[item]);
#ifdef CONFIG_SMP
int cpu;
for_each_online_cpu(cpu)
x += per_cpu_ptr(zone->pageset, cpu)->vm_stat_diff[item];
if (x < 0)
x = 0;
#endif
return x;
}
static inline unsigned long zone_page_state(struct zone *zone,
enum zone_stat_item item)
{
long x = atomic_long_read(&zone->vm_stat[item]);
#ifdef CONFIG_SMP
if (x < 0)
x = 0;
#endif
return x;
}
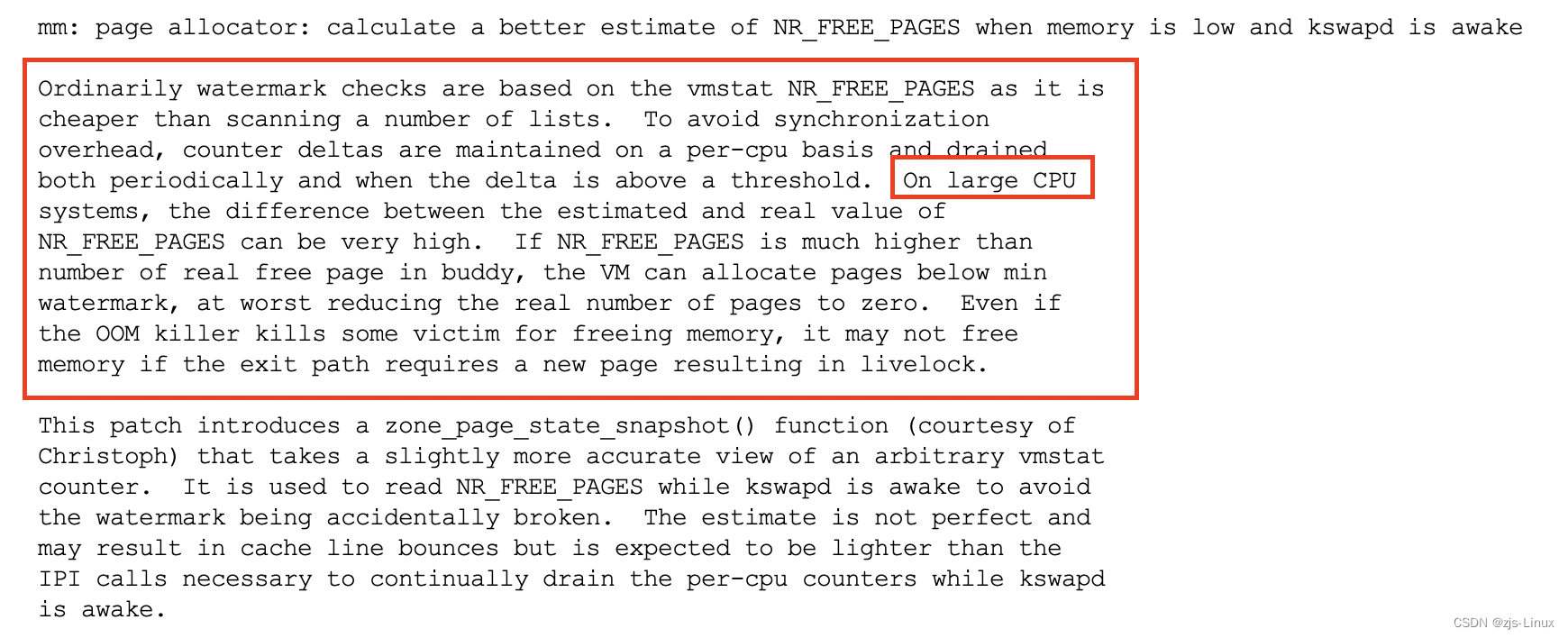
在大量cpu集群当中(服务器行业)通过NR_FREE_PAGES获取到的free_pages与系统实际的free_pages差异是巨大的(CPU数量越大 free_pages差异就会越大)。On large CPU systems, the difference between the estimated and real value of NR_FREE_PAGES can be very high;通过zone_page_state_snapshot函数获取的free_pages更加精确
理解了zone_page_state_snapshot,此时就引出另外问题percpu_drift_mark是什么?什么作用?
percpu_drift_mark
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
/*
* Refresh the thresholds for each zone.
*/
void refresh_zone_stat_thresholds(void)
{
...
for_each_populated_zone(zone) {
struct pglist_data *pgdat = zone->zone_pgdat;
unsigned long max_drift, tolerate_drift;
...
/* 根据zone normal区域计算出zone_normal 内存threshold阈值 */
threshold = calculate_normal_threshold(zone);
...
/*
* Only set percpu_drift_mark if there is a danger that
* NR_FREE_PAGES reports the low watermark is ok when in fact
* the min watermark could be breached by an allocation
*/
/* zone区域low - min水位的差值作为阈值本质是触发reclaim的操作空间
* kswapd的回收与low,min水位存在强相关,后续将详细介绍kswapd wake up与watermark_low之间的关系 */
tolerate_drift = low_wmark_pages(zone) - min_wmark_pages(zone);
/* 从这个设计当中可以明确cpu越多max_drift越大,
* 当系统当中所有cpu的的阈值累计大于low - min的差值时,percpu的缓存将不能被忽略此时必须对percpu_drift_mark进行更新
* 常规情况下zone->percpu_drift_mark = max_drift
* 原因是zone->percpu_drift_mark的设定发生在系统启动的早期此时high watermark = 0 */
max_drift = num_online_cpus() * threshold;
if (max_drift > tolerate_drift)
zone->percpu_drift_mark = high_wmark_pages(zone) +
max_drift;
}
}
内核在内存管理中,读取空闲页面与watermark值进行比较,在内存相对充足时系统状态是相对安全,此时对于系统free_pages的统计可以忽略percpu缓存(或者是percpu缓存很小低于界限时可以被忽略); 但是当系统内存不再安全(或者是percpu缓存积累到已经超过界限时无法被忽略)就需要更加准确的free_pages,如果要读取更加精确的free_pages空闲页面值,就必须同时读取vm_stat、pageset进行计算获取更加准确的free_pages。如果每次都读取的话会降低效率,因此设定了percpu_drift_mark值,只有在低于这个值的时候,才触发更精确的计算来保持性能, 这个参数在refresh_zone_stat_thresholds。
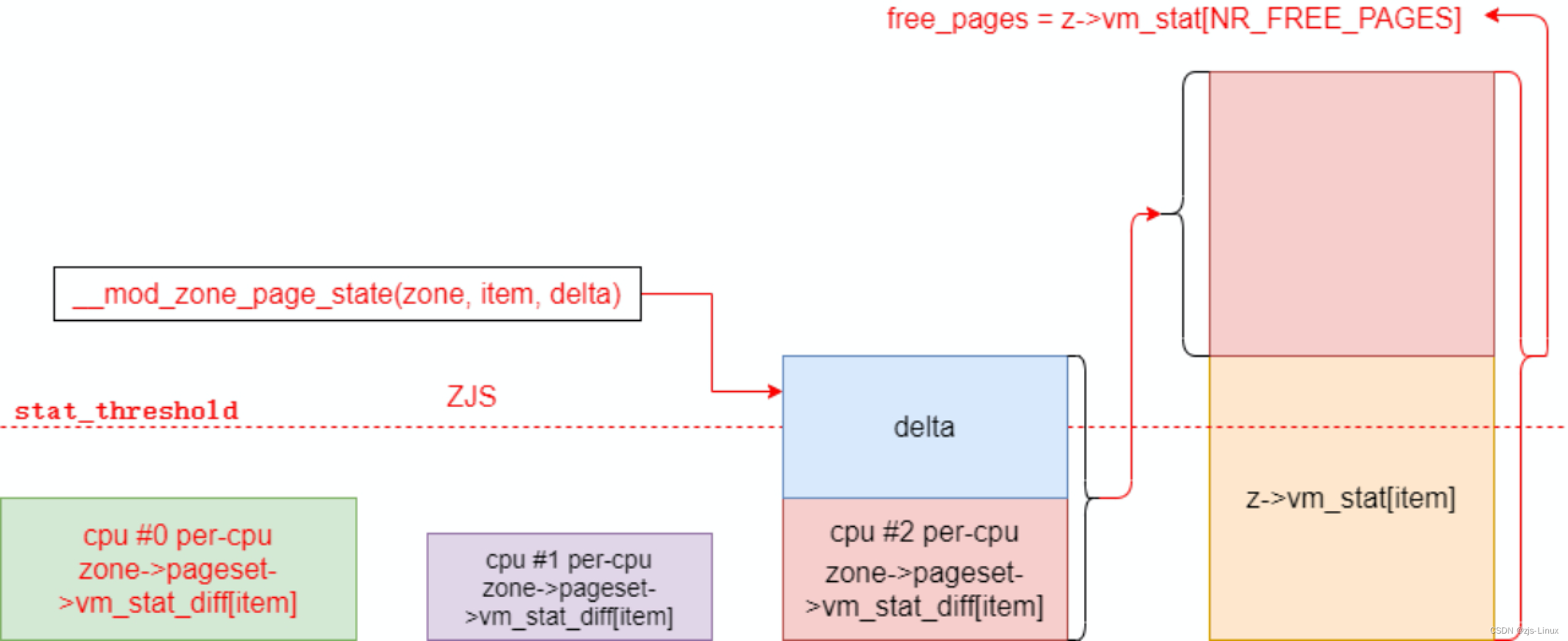
*__percpu pageset计数器更新逻辑如下,如果超过stat_threshold,则移至vm_stat[]的过程
void __mod_zone_page_state(struct zone *zone, enum zone_stat_item item,
long delta)
{
struct per_cpu_pageset __percpu *pcp = zone->pageset;
s8 __percpu *p = pcp->vm_stat_diff + item;
long x;
long t;
x = delta + __this_cpu_read(*p);
t = __this_cpu_read(pcp->stat_threshold);
/* 当delta + pcp pageset->vm_stat_diff > pcp->stat_threshold将
* delta + pcp pageset->vm_stat_diff + vm_stat如下图显示的
*/
if (unlikely(abs(x) > t)) {
zone_page_state_add(x, zone, item);
x = 0;
}
__this_cpu_write(*p, x);
}
static inline void zone_page_state_add(long x, struct zone *zone,
enum zone_stat_item item)
{
atomic_long_add(x, &zone->vm_stat[item]);
atomic_long_add(x, &vm_zone_stat[item]);
}
/*
* tig show aa45484
* tig show 88f5acf88ae6a9778f6d25d0d5d7ec2d57764a97
*/
bool zone_watermark_ok_safe(struct zone *z, unsigned int order,
unsigned long mark, int highest_zoneidx)
{
/* 获取zone区域的空闲内存 */
long free_pages = zone_page_state(z, NR_FREE_PAGES);
/* 两个条件:1、percpu_drift_mark存在; 2、free_pages低于percpu_drift_mark阈值;当
* 满足这两这条件时对free_pages进行更新。
* 当free_pages < percpu_drift_mark时说明此时zone区域的空闲内存是不足的
* 此时就需要将累加上percpu的空闲内存数量,获取更加准确的系统可用空闲内存数量 */
if (z->percpu_drift_mark && free_pages < z->percpu_drift_mark)
free_pages = zone_page_state_snapshot(z, NR_FREE_PAGES);
/* __zone_watermark_ok函数当中alloc_flags = 0;针对这个设计我们进行详细的分析
* 当alloc_flags = 0时,unusable_free变大
* unusable_free = ((1 << order) - 1) + z->nr_reserved_highatomic + zone_page_state(z, NR_FREE_CMA_PAGES)
* free_pages -= unusable_free此时free_pages减小且min水位不变(没有min/2、min/4的这种操作)
* 这种情节下free_pages空闲内存必定是较小的。
* | |
|-------|-------> free_pages
| | |
| | |
|-------|-------> min
| |
| |
| |
| |
| |
| |
|_______|
* free_pages与min(high, low, min)的区间时很小,这种情况下__zone_watermark_ok大概率时return false
* if (free_pages <= min + z->lowmem_reserve[highest_zoneidx])
* return false;
* 到此复盘这个过程:如果free_pages不统计percpu, 这样极大概率是无法准确描述当前系统内存状态的。
*/
return __zone_watermark_ok(z, order, mark, highest_zoneidx, 0,free_pages);
zone_watermark_ok_safe主要应用在内存回收流程当中,所以准确的free_page空闲内存统是必要的,patch的commit信息如下:

三、性能思考
系统运行过程当中free_pages可用内存状态是不断在变化的,在alloc_pages进行内存申请时可能会出现内存不足的情况,当系统内存不足时就需要进行内存回收,系统就会根据watermark的不同进行不同的回收动作以满足内存申请需要。
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
struct page *page;
/* set alloc_flage ALLOC_WMARK_LOW 也就是WMARK_LOW */
unsigned int alloc_flags = ALLOC_WMARK_LOW;
...
/* First allocation attempt */
/* get_page_from_freelist快速申请路径,当内存不足时从pagecache当中快速回收内存供给alloc_pages接口。
* alloc_flags = ALLOC_WMARK_LOW 所以这里mark = WMARK_LOW 检查的水位就是LOW水位。
* mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
* if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
}
* 当通过快速路径在无法申请到内存时就需要从slowpath当中申请内存,这里需要强调:是从watermark_low水位之上申请失败。
* slowpath: kswapd, direct reclaim、kcompactd存在较大的延迟
* */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
...
/* 通过慢速路径获取足够的内存
* slowpath实现过程当中gfp_to_alloc_flags(gfp_mask);
* set ALLOC_WMARK_MIN这样就设置了不同的水位对应的不同操作。*/
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
....
return page;
}
/* 到此说明从watermark_low水位之上申请失败,此时free_pages低于watermark_low水位之下 */
static inline struct page *__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
...
/*
* The fast path uses conservative alloc_flags to succeed only until
* kswapd needs to be woken up, and to avoid the cost of setting up
* alloc_flags precisely. So we do that now.
*/
//unsigned int alloc_flags = ALLOC_WMARK_MIN | ALLOC_CPUSET;
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/* 在free_pages低于low水位状态下wakeup_kswapd线程进行异步内存回收 */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
...
/* 与从开始的从快速路径内存申请不同,这里检查的水位变成了WMARK_MIN
* if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
}
* 此时如果内存申请失败也就意味着free_pages空闲内存低于watermark_min水位,从watermark_min水位之上无法申请到可用内存
* 此时系统内存可用内存处于极低的系统状态。
*/
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
...
/* Try direct reclaim and then allocating */
/* 此时free_pages已经低于watermark_min数位,为例保证系统的运行此时进行direct reclaim内存回收 */
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
...
got_pg:
return page;
}
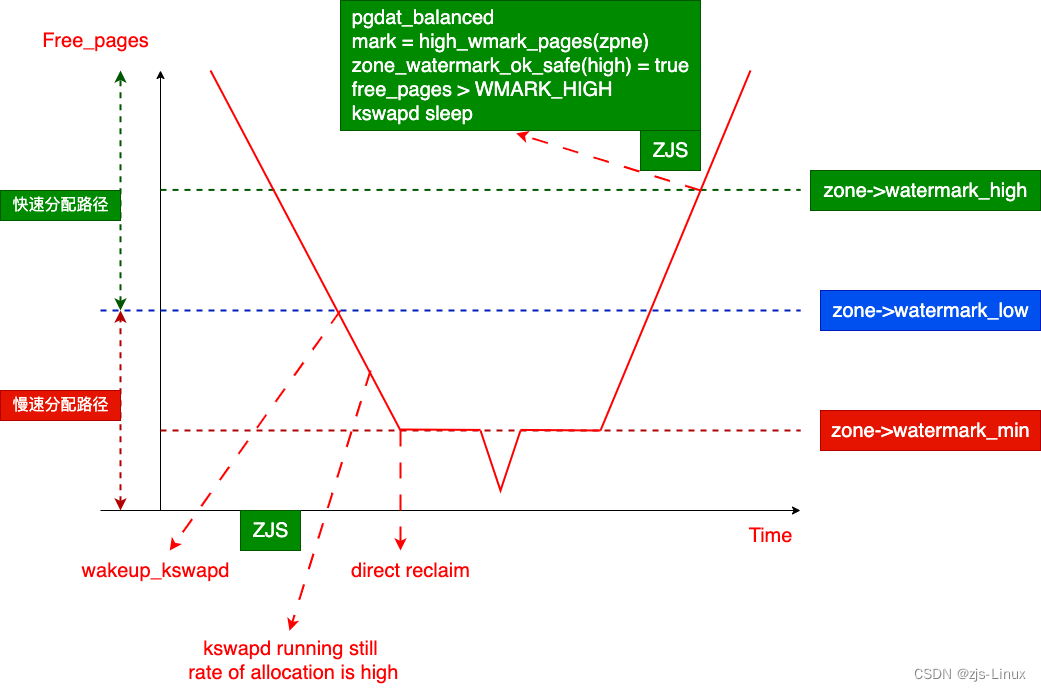
当系统低内存场景时有人会考虑拉升min水位这是不可取的,拉升min水位看似能够更快的进行direct reclaim但是这样会带来极大的延迟,同时又因为min,low,high这三者之间的差异很小导致kswapd无法发挥异步回收的作用很容易进入sleep状态可以通过适当通过调整watermark_scale_factor将min,low,high之间的差距增大这样更有利于kswapd发挥更大的作用提高系统性能。















 3231
3231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









