







Linux page fault
一、背景
Linux在设计时有一个很重要的特性就是copy-on-write,这个特性就引出page fault,在用户态内存分配时,假如申请了1G内存,此时在没有使用的情况下Linux kernel 并没有提供实际的物理内存,只有当写访问时才会触发异常完成物理内存的分配,这个过程简单来讲就是page fault。通过以下demo能更加详细的认识这个page fault过程,做两个测试demo分别:demo01 memset 填充内存、demo02不填充内存。通过一下这两个demo就说明了这种copy-on-write现象。
//demo02.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ALLOC_SIZE 4096*1024*10
int main(int argc, char **argv)
{
char *buffer = NULL;
buffer = malloc(ALLOC_SIZE);
if (NULL == buffer)
{
printf("alloc buffer faild\n");
return -1;
}
getchar();
free(buffer);
buffer = NULL;
return 0;
}
//gcc demo02.c -o demo02
打开两个窗口一边执行demo02,一边查看系统剩余内存 此时相当于没有填充内存可以认为系统没有给malloc分配40m内存
//程序执行前剩余空间2137M
[jinsheng@localhost Work]$ free -m
total used free shared buff/cache available
Mem: 3713 713 2137 10 862 2751
Swap: 4031 0 4031
//程序执行中系统剩余内存2137M
[jinsheng@localhost Work]$ free -m
total used free shared buff/cache available
Mem: 3713 713 2137 10 862 2751
Swap: 4031 0 4031
//demo01.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ALLOC_SIZE 4096*1024*10
int main(int argc, char **argv)
{
char *buffer = NULL;
buffer = malloc(ALLOC_SIZE);
if (NULL == buffer)
{
printf("alloc buffer faild\n");
return -1;
}
memset(buffer, 0xa, ALLOC_SIZE);
getchar();
free(buffer);
buffer = NULL;
return 0;
}
//程序执行前系统剩余内存2137M
[jinsheng@localhost Work]$ free -m
total used free shared buff/cache available
Mem: 3713 713 2137 10 862 2751
Swap: 4031 0 4031
//程序执行中剩余内存2097M,系统分配出了40M
[jinsheng@localhost Work]$ free -m
total used free shared buff/cache available
Mem: 3713 753 2097 10 862 2711
Swap: 4031 0 4031
//程序退出后系统剩余内存2137M,系统内存恢复。
[jinsheng@localhost Work]$ free -m
total used free shared buff/cache available
Mem: 3713 712 2137 10 862 2751
Swap: 4031 0 4031
通过以上两个demo,单纯的malloc并不使用的情况下系统内存并没有降低,是因为系统并没有给buffer真正的分配内存,只有真正使用内存时系统才会真正分配内存给buffer。page fault原理就是这样只有访问时才能触发异常完成物理内存的分配以及物理内存与虚拟内存映射关系的建立。
二、原理设计
当用户任务通过sys_mmap()或sys_brk()向内核请求内存时,内核不会立即分配内存并将其映射到任务。当内核接收到请求时,它仅在被请求的用户任务的rb树(由vma信息管理的vma信息)的rb树中记录(添加或更改)诸如内存范围和标志之类的信息。然后,当用户任务实际尝试访问页面时会发生错误。故障处理程序处理以下请求:当请求的页面首先请求将内存初始化为0时,它将映射为零页面,或者映射为另一任务正在使用的页面以共享该页面。使用此方法有几个优点:
- 由于用户任务不会在分配后立即使用所有请求的内存,因此只有在访问所需内存时才通过分配物理内存来节省实际内存的使用。匿名映射:与文件无关的用户任务所需的堆和堆栈内存请求;文件映射:用户请求将文件映射到虚拟地址空间(内存映射文件)-mmap内存请求
- 内核可以快速处理用户任务请求的内存。– COW(写时复制)方法.当父任务执行fork或克隆创建子任务时,将复制并使用父任务使用的内存页表,而不是立即为要由子任务使用的内存分配请求分配物理页。这样,快速的任务创建成为可能。
首先关注ARM64架构下时如何触发异常处理机制的,内核异常其实就是中断的一种,所以这个触发过程一定也是在中断向量表当中,相关代码路径如下:arch/arm64/kernel/entry.S
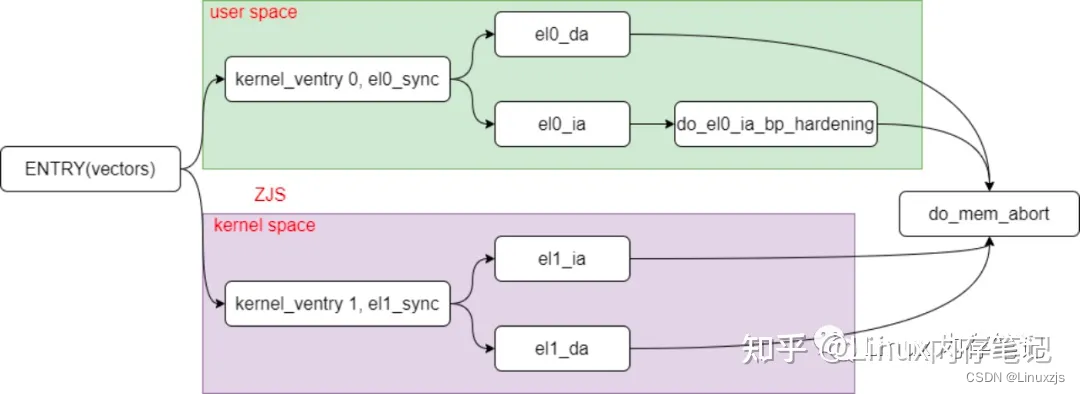
从代码上来就看都最终汇聚到了do_mem_abort函数当中:
asmlinkage void __exception do_mem_abort(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
const struct fault_info *inf = esr_to_fault_info(esr);
struct siginfo info;
if (!inf->fn(addr, esr, regs))
return;
pr_alert("Unhandled fault: %s (0x%08x) at 0x%016lx\n",
inf->name, esr, addr);
mem_abort_decode(esr);
info.si_signo = inf->sig;
info.si_errno = 0;
info.si_code = inf->code;
info.si_addr = (void __user *)addr;
arm64_notify_die("", regs, &info, esr);
}
通过该函数中关键的处理:根据传进来的esr获取fault_info信息,从而去调用函数。struct fault_info用于错误状态下对应的处理方法,而内核中也定义了全局结构fault_info,存放了所有的情况。主要的错误状态和处理函数对应如下:
static const struct fault_info fault_info[] = {
{ do_bad, SIGBUS, 0, "ttbr address size fault" },
{ do_bad, SIGBUS, 0, "level 1 address size fault" },
{ do_bad, SIGBUS, 0, "level 2 address size fault" },
{ do_bad, SIGBUS, 0, "level 3 address size fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 0 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 1 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 2 translation fault" },
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "level 3 translation fault" },
{ do_bad, SIGBUS, 0, "unknown 8" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 access flag fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 access flag fault" },
{ do_bad, SIGBUS, 0, "unknown 12" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 1 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 2 permission fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "level 3 permission fault" },
....
}
从代码中可以看出:承接page fault触发图组成一个完整的网络。
- 0/1/2/3级页表转换异常时调用do_translation_fault最终调用do_page_fault;
- 1/2/3级页表访问异常调用do_page_fault;
- 其他的异常则调用do_bad,

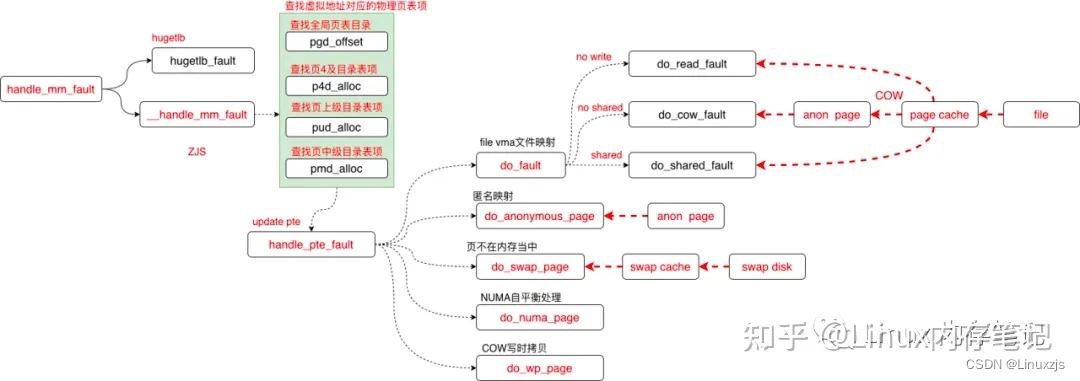
handle_mm_fault 就是page fault的核心逻辑:
static int handle_pte_fault(struct vm_fault *vmf)
{
.....
/*
PTE为空不存在:则vma_is_anonymous判断映射类型
如果使用匿名映射时,将通过调用do_anonymous_page()函数来分配和映射新页 面。此方法称为惰性页面分配
如果使用文件映射时,请调用do_fault()函数从file读取页面
*/
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
/*判断PTE存在但是P present bit 为0,说明了两个问题:
1、page是anon page
2、page 被回收压缩到了swap devices当中,当发生fault时需要将该page从swap device当中读出
*/
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
/*NUMA平衡发生故障,则调用do_numa_page()函数来迁移页面*/
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
/*
向页面发出写请求时,条目值将设置为脏。另外,当对写保护条目(即只读共享页 面)发出写请求时,
将调用do_wp_page()函数将现有共享页面复制到新页面。
当用户向共享内存发出写请求时,现有共享页面将被COW(写时复制)到新页面
*/
if (vmf->flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(vmf);
......
}
......
}
2.1、anon page fault
static int do_anonymous_page(struct vm_fault *vmf)
{
...
/*文件映射标志如果是共享VM_SHARED, 直接return VM_FAULT_SIGB /*
分配PTE,并判断释放分\配成功,如果失败则直接return VM_FAULT_OOM
如果成功则将新分配的PTE加入到PMD当中。
*/
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
....
/* Allocate our own private page. */
/*匿名映射进行分配和准备。如果尚未准备就绪,则会返回虚拟内存不足*/
if (unlikely(anon_vma_prepare(vma)))
goto oom;
/*分配一个新的用户page页面,如果存在高内存,则从高内存分配一页作为__GFP_MOVABLE可移动类型
如果分配page失败则跳转到oom表明此时页面不足*/
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
if (!page)
goto oom;
/*
虚拟页数超过了memcg设置的提交配额,则返回虚拟内存不足错误。它主要用于通过使用内存控制组来控制指定任务的内存使用情况
*/
if (mem_cgroup_try_charge(page, vma->vm_mm, GFP_KERNEL, &memcg, false))
goto oom_free_page;
...
/*递增MM_ANONPAGES计数器*/
inc_mm_counter_fast(vma->vm_mm, MM_ANONPAGES);
/*将page添加到匿名的反向映射当中*/
page_add_new_anon_rmap(page, vma, vmf->address, false);
/*确认已将页面添加到memcg*/
mem_cgroup_commit_charge(page, memcg, false, false);
/*将新页面设置为active,并将其添加到lru缓存中,将其添加到lru_add_pvec。*/
lru_cache_add_active_or_unevictable(page, vma);
setpte:
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);//映射到
/* No need to invalidate - it was non-present before */
update_mmu_cache(vma, vmf->address, vmf->pte);//刷新TLB
....
}
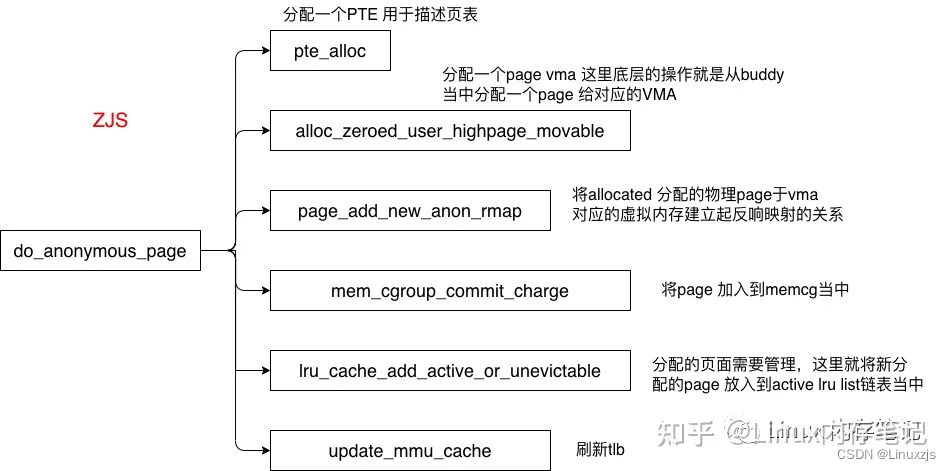
匿名页发生fault 就是底层allocated page 并完成vma与建立映射关系完成内存的实际分配。这个过程当中有一点需要注意:
//alloc_page
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
/*将新页面设置为active,并将其添加到lru缓存中,将其添加到lru_add_pvec。*/
lru_cache_add_active_or_unevictable(page, vma);
page fault 产生一个新的page 但是这个页大多数的情况下是不活跃的大多使用一次就不在访问,按照当前的设计将新分配的page 直接放到active list,将原有的活跃的hot page 从active list挤到inactive list 这个过程就会造成性能的衰退。
https://lkml.kernel.org/lkml/20200318175155.GB154135@cmpxchg.org/
在高版本内核当中结合workingest工作集结将新产生的page直接放到inactive list达到active/inactive list的平衡。

2.2、file page fault
/*文件映射操作
在用作文件映射类型的vma区域中发生故障时,将其视为以下三种类型。
如果没有写许可请求,则读取并映射页面缓存中的页面。如果它不在页面缓存中,它将从文件中读取并再次将其存储在页面缓存中。
只读当请求非共享文件的写入权限时,它将读取该文件,将其存储在页面高速缓存中,然后将其复制到新页面上,并通过授予对该页面的写入权限来映射一个匿名对象。
如果请求只读共享文件的写许可权,请设置写许可权。
*/
static int do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
/*
* The VMA was not fully populated on mmap() or missing VM_DONTEXPAND
*/
/*如果映射的设备或文件系统中不支持vm_ops-> fault hook函数时,就是这种情况。
处理PTE条目的取消映射。
在32位系统上,提供了将pte条目映射到highmem的选项。仅在这种情况下,当不使用pte表时应执行取消映射处理。
在64位系统中,由于pte条目始终使用维护映射状态的普通内存,因此不会执行单独的取消映射。
如果使用了CONFIG_HIGHPTE内核选项,则可以将pte条目分配给highmem并使用。
故障处理如下。
如果尚未准备好pmd条目,则返回VM_FAULT_SIGBUS错误。
如果没有与故障地址相对应的pte条目值,则返回VM_FAULT_SIGBUS,如果有,则返回VM_FAULT_NOPAGE
*/
if (!vma->vm_ops->fault) {
/*
* If we find a migration pmd entry or a none pmd entry, which
* should never happen, return SIGBUS
*/
if (unlikely(!pmd_present(*vmf->pmd)))
ret = VM_FAULT_SIGBUS;
else {
vmf->pte = pte_offset_map_lock(vmf->vma->vm_mm,
vmf->pmd,
vmf->address,
&vmf->ptl);
/*
* Make sure this is not a temporary clearing of pte
* by holding ptl and checking again. A R/M/W update
* of pte involves: take ptl, clearing the pte so that
* we don't have concurrent modification by hardware
* followed by an update.
*/
if (unlikely(pte_none(*vmf->pte)))
ret = VM_FAULT_SIGBUS;
else
ret = VM_FAULT_NOPAGE;
pte_unmap_unlock(vmf->pte, vmf->ptl);
}
} else if (!(vmf->flags & FAULT_FLAG_WRITE))
//没有写请求,则调用do_read_fault()函数以从映射文件中读取页面,造成读文件错误
ret = do_read_fault(vmf);
else if (!(vma->vm_flags & VM_SHARED))
//没有共享方式,则do_cow_fault()函数以复制并写入新页面,相当于写私有文件
ret = do_cow_fault(vmf);
else
//如果是共享文件映射调用do_shared_fault()函数以设置写操作,相当于写共享文件
ret = do_shared_fault(vmf);
/* preallocated pagetable is unused: free it */
if (vmf->prealloc_pte) {
pte_free(vma->vm_mm, vmf->prealloc_pte);
vmf->prealloc_pte = NULL;
}
return ret;
}
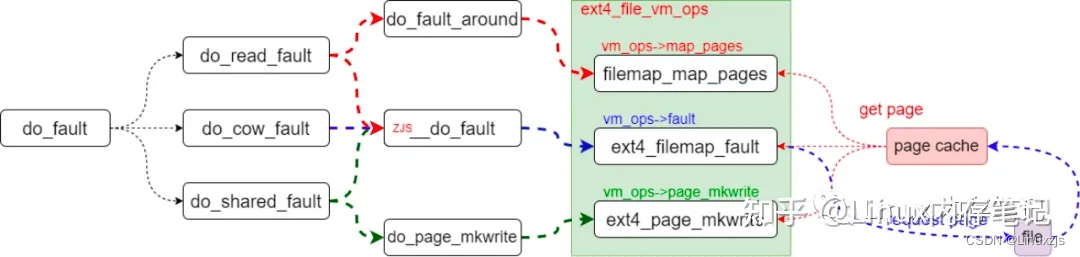
文件操作的page fault 主要就是读取文件的过程,将文件读取到物理page 然后与vma建立映射,这样就完成了文件的page fault 过程,在这个过程当中会产生IO,如果是在低内存场景下这种IO会加剧系统的卡顿,所以针对这种问题一般有几种策略:
-
预读 针对特定场景提起将文件加载内存当中将IO可能带来的影响提前,这样就避免了进入场景过程当中page fault产生IO带来的影响。
-
mlock直接锁文件,mlock本质上是两个作用:
锁内存避免回收,这样文件对应的内存就不可能被回收避免page fault ;
通过__mm_populate预先分配好内存不在page fault;
当然以上只是简单的策略,如果想有更加好的优化策略需要更加深入的分析整个历程找到合适的优化策略。
2.3、swap fault
系统kswapd回收匿名页的过程与回收文件页存在很大不同,文件页的回收分干净文件也与脏文件页回收过程是可以完成数据刷新后直接将page回收到buddy系统当中,但是匿名页的回收就存在很大的不同,系统在回收匿名页时只能通过交换的方式将匿名页当中的数据交换到swap设备当中然后释放内存也就是swap-out,当发生page fault时在讲数据交换到内存当中就是swap-in。

swap是内核当中的一种交换技术通过swap device 可以做内存的扩展,当前常用的swap 设备分为两种:1、swap file 是文件设备系统创建文件然后作为交换设备将匿名页交换到swapfile;2、swap partition磁盘机制。这其中zram设备最具代表性,zram使用系统内存虚拟形成一个虚拟磁盘/dev/zram0,通过将匿名页的交换完成匿名页的回收。通过swap设备能够达到一种扩展系统内存的目的,在手机当中有广泛应用。下图就是国产某厂商手机通过swap设备做的内存扩展。
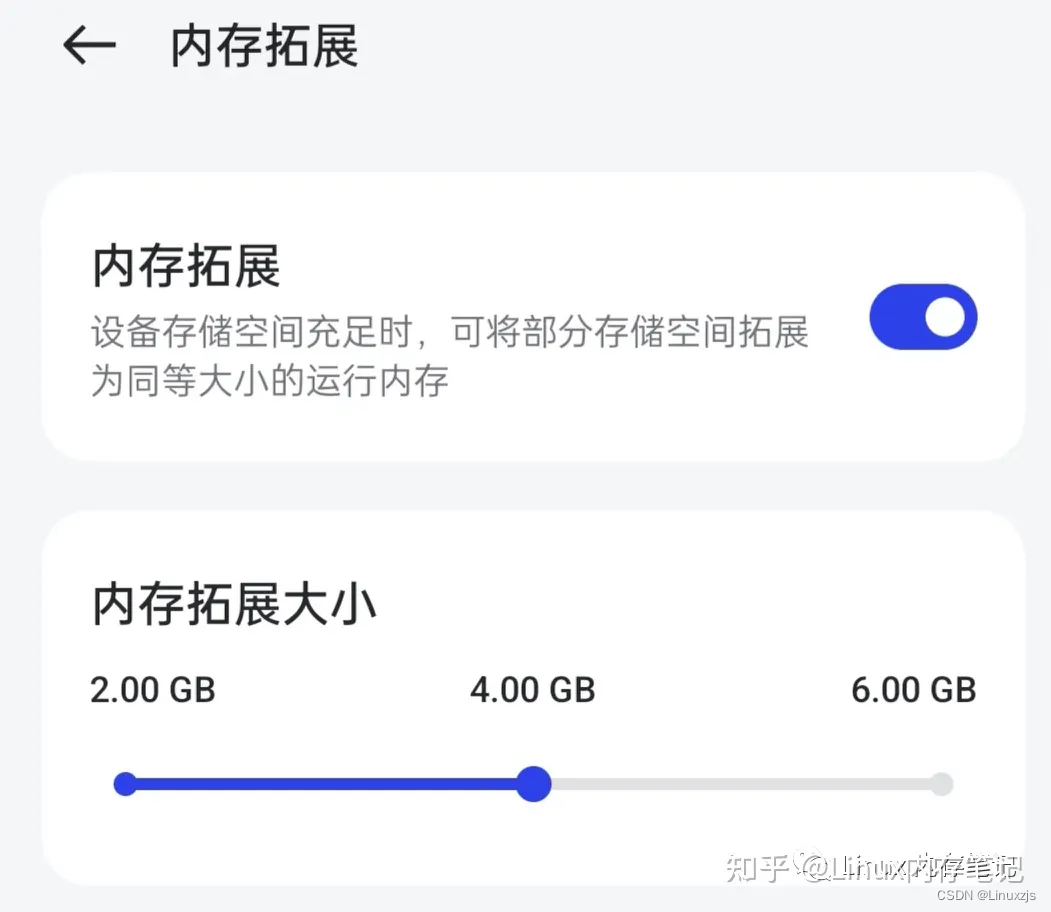
随着磁盘读写速度的增加以及存储介质价格的下降swap技术在服务器行业也得到了一定的应用。
int do_swap_page(struct vm_fault *vmf)
{
......
//预读是否开启
bool vma_readahead = swap_use_vma_readahead();
/*
判断是否开启预读功能,如果开启则预读功能,如果开启读取一个page
*/
if (vma_readahead)
page = swap_readahead_detect(vmf, &swap_ra);
.........
delayacct_set_flag(DELAYACCT_PF_SWAPIN);
/*
判断page是否为空,如果page为NULL,
则执行lookup_wsap_page根据entry条目,
从swap cache中查找可用的page
*/
if (!page)
page = lookup_swap_cache(entry, vma_readahead ? vma : NULL,
vmf->address);
/*
如果查找失败page = NULL,没找到可用的page,
则进入if判断语句当中
*/
if (!page) {
/*判断是否开启预读功能,
如果开启了则使用do_swap_page_readahead,
如果没有开启则swapin_readahead从交换文件读取一定数量的页面,
包括请求的页面
*/
if (vma_readahead)
page = do_swap_page_readahead(entry,
GFP_HIGHUSER_MOVABLE, vmf, &swap_ra);
else
page = swapin_readahead(entry,
GFP_HIGHUSER_MOVABLE, vma, vmf->address);
..........
/*
新的设计已经将page放到inactive list
lru_cache_add_inactive_or_unevictable
*/
lru_cache_add_active_or_unevictable(page, vma);
......
}
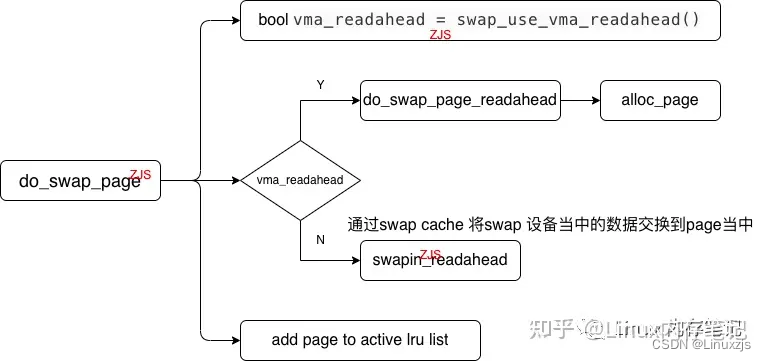
如果swap fault 的对象是zram设备这个过程不会产生IO他的本质上是从内存当中读取数据,但是如果发生swap fault 时对象是swapfile 这个过程就会产生大量的IO这种操作本质上是读文件,会带来性能的损耗,这里挖一个坑后续会详细的给大家分析swap 技术以及可以优化的点。
2.4、do_wp_page
我们在使用fork创建子进程时,常说父进程与子进程公用相同的内存空间,之后真正开始运行进行数据访问时才会创建两份内存数据,这里就发生在这个阶段。在创建子进程之初,父子进程以只读的方式共享父进程的所有数据,当父子进程试图进行写操作时系统就会触发异常,从而完成内存的分配以及数据的复制拷贝。
static int do_wp_page(struct vm_fault *vmf)
__releases(vmf->ptl)
{
struct vm_area_struct *vma = vmf->vma;
/*这是两个过程
1. 根据PTE页表项获取页帧号,unsigned long pfn = pte_pfn(pte);
2. 在根据页帧号获取到页描述符pfn_to_page(pfn)
*/
vmf->page = vm_normal_page(vma, vmf->address, vmf->orig_pte);
/*
vmf->page为false,则说明该page没有建立映射关系,此时、
如果(vma->vm_flags & (VM_WRITE|VM_SHARED)) == (VM_WRITE|VM_SHARED)说明这个page是一个共享的页面,则执行wp_pfn_shared
此时操作的就是一个共享可写页面,不需要复制物理页面,只需要设置页表权限即可
如果(vma->vm_flags & (VM_WRITE|VM_SHARED)) != (VM_WRITE|VM_SHARED)说明该页面是只读页面,这种情况就是当父进程frok一个子进程
此时该设置空间地址为只读页面,只有当发生write写操作时才会发生(COW)写时拷贝,分配一个新的page,并建立映射关系wp_page_copy(vmf);
此时操作的就是一个私有可写页面,此时复制物理页面(分配物理页面)并将虚拟地址与物理地址之间建立映射关系
*/
if ((!vmf->page)&& (vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
return wp_pfn_shared(vmf);
if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
return wp_page_shared(vmf);//共享可写页面,不需要复制物理页面,只需要设置页表权限即可
/*私有可写,复制物理页面,完成虚拟地址与物理地址之间的映射*/
return wp_page_copy(vmf);
}
大体上分为三个分支:wp_pfn_shared、wp_page_shared、wp_page_copy。差别就是根据权限的不同确定是否进行物理也的复制,
三、拓展与关联
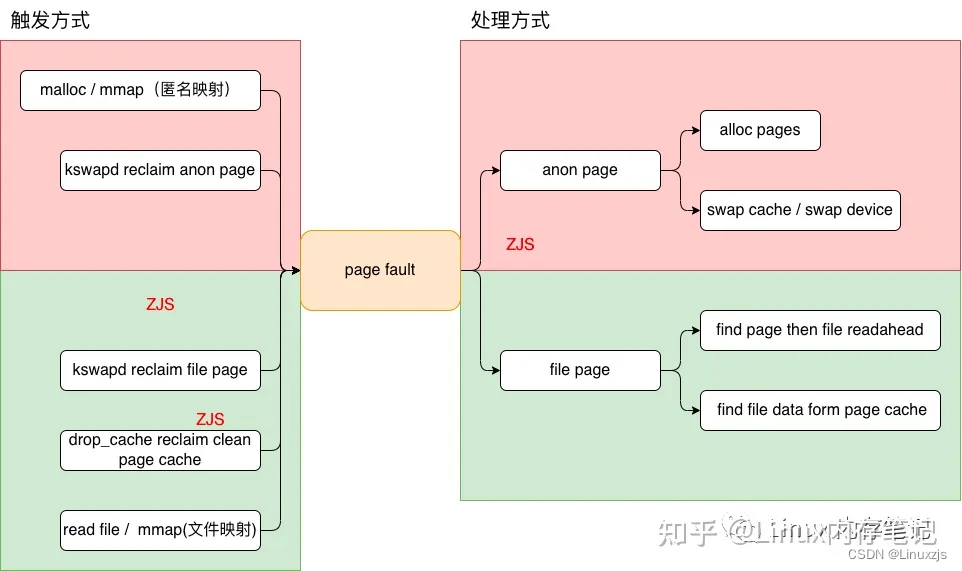
在系统正常运行下一般情况下page fault 并不会有太多问题,但是如果系统处在低内存场景当中page fault 就会带来较多的IO,锁,内存问题,针对不同的问题要根据场景进行针对性的分析找到痛点进行优化解决。
四、问题与优化
关于page fault 引发的性能问题有很多中不同的处理方式有简单取巧的就使用mlock 通过将内存锁到系统当中避免page被回收这样就避免了再次访问导致的page fault然后就可以避免这个过程引入IO,提高特定软件的性能。当然这种方式也是有坏处的就是mlock导致内存被锁无法回收,当系统内存紧张时就其他进程无法获取足够的内存导致需要内存的其他软件运行衰退。话说回来了如果你系统内存很大mlock确实是一种很好的方法。
page fault过程本身存在严重的性能衰退,衰退的主要来源就是mmap_sem/mmap_lock锁,在当前的版本当中当进程访问发生page fault时,mmap_sem/mmap_lock会锁整个发生page fault的进程,但是现实 情况是page fault只发生在特定区域并不是整个进程所对应的vma,再加上page fault 被调用的频率非常高mmap_lock的锁竞争就会造成严重的性能衰退。
针对这个问题Linux社区提出了大小锁的概念也就是per-VMA lock特性,这个特性的引入就是page fault过程当中不在直接mmap_sem/mmap_lock整个进程而是有条件的进行筛选,只锁发生page fault的特定区域,这样的改进在page fault 高频率被调用的情况下对系统性能优化带来的极大的提升,目前已经合入到了6.x版本内核当中,感兴趣的可以去分析per-VMA lock机制对代码及设计原理有更加清晰的认识。per-VMA lock简单演示图
//kernel-5.x page fault
static int __kprobes do_page_fault(unsigned long addr, unsigned int esr,
struct pt_regs *regs)
{
//mmap_lock 锁整个进程的的page fault过程
mmap_read_trylock(mm);
fault = __do_page_fault(mm, addr, mm_flags, vm_flags, regs);
mmap_read_unlock(mm);
}
//kernel-6.x
static int __kprobes do_page_fault(unsigned long far, unsigned long esr,
struct pt_regs *regs)
{
//特定区域不在被mmap_lock控制
vma = lock_vma_under_rcu(mm, addr);
fault = handle_mm_fault(vma, addr, mm_flags | FAULT_FLAG_VMA_LOCK, regs);
//部分区域依然使用原生流程继续使用mmap_lock控制
mmap_read_trylock(mm);
fault = __do_page_fault(mm, addr, mm_flags, vm_flags, regs);
mmap_read_unlock(mm);
}
以上策略极大的解决了因为mmap_lock锁竞争导致的性能衰退,page fault过程性能有了很大的提升。

想要了解更多Linux 内存相关知识敬请关注: Linux 内存笔记公众号,期待与大家的更多交流与学习。
原创文章,转载请注明出处。















 9551
9551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









