







想要了解更多Linux 内存相关知识敬请关注:Linux内存笔记公众号,期待与大家的更多交流与学习。原创文章,转载请注明出处。
一、背景
Linux read/mmap 时将文件从磁盘读区到内存当中,read读取文件操作必然会带来IO如果能直接从内存当中读取文件这样就能有效的解决IO及延迟问题。page cache的诞生就是解决这个问题,文件读取后将文件对应的物理page 添加到redix tree当中管理后续在做同样的读取操作时就直接从page cache当中直接读取文件。这个机制本质上来讲与硬件架构的cache原理上是想通的,理解cache机制有助于理解page cache。free -m可以看到cache 这个数据就是page cache。
# free -m
total used free shared buff/cache available
Mem: 3379 95 3240 0 43 3264
Swap: 0 0 0
二、原理&预读
系统启动后读取文件常规的操作基本分为两种:read/write、mmap;基本的框架就是如下为了分析方便我们就从基本的page cache, 结构体,read两个点切入到文件加载了解page cache管理,page cache预读。从下图可以看到cache联通了物理内存与文件系统,所以cache的读取会直接影响系统文件加载性能。
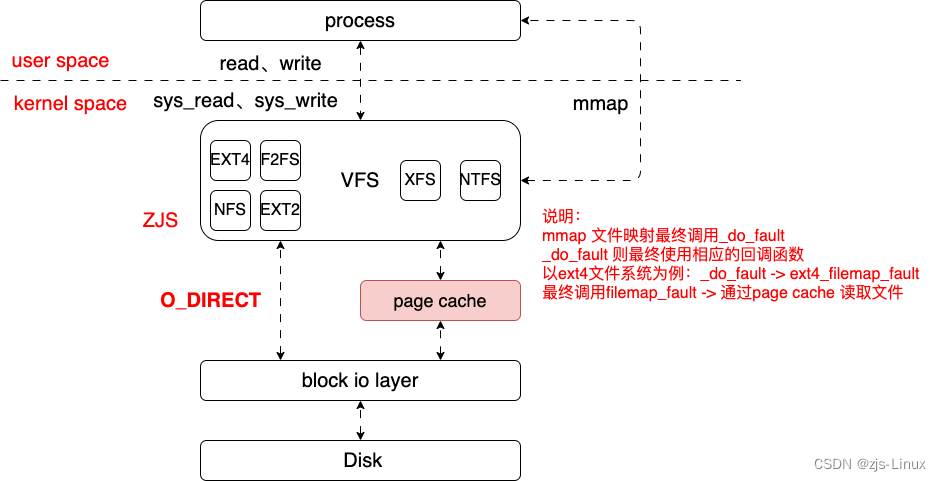
Struct 结构体
进程与文件的关联,当文件open打开时该文件就作为task_struct进程的一部分,所以在task_struct 当中必然有file结构体;
struct task_struct {
...
/* Filesystem information: */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
...
}
fs指针指向结构体fs_struct,该结构体描述文件相关的信息;files指针指向files_struct,该结构体描述已经打开文件的相关信息;
struct fs_struct {
...
int in_exec;
struct path root, pwd;
} __randomize_layout;
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
} __randomize_layout;
root: 代表文件所属的根目录cd /; pwd: 代表当前目录pwd; struct dentry:结构体当中包含众多文件信息,文件名,访问属性等信息。
struct files_struct {
...
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
struct file {
...
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
...
struct file_ra_state f_ra;
...
}
files_struct结构体主体是file结构体,file结构体当中有以上关键结构体path代表文件名,访问属性等;file_operation结构体当中是文件操作的相关回调函数,在我们开发文件设备驱动时这个结构体是必须被使用的。file_ra_state主要是用于描述文件预读操作。
/*
* Track a single file's readahead state
*/
struct file_ra_state {
pgoff_t start; /* where readahead started */
unsigned int size; /* # of readahead pages */
unsigned int async_size; /* do asynchronous readahead when
there are only # of pages ahead */
unsigned int ra_pages; /* Maximum readahead window */
unsigned int mmap_miss; /* Cache miss stat for mmap accesses */
loff_t prev_pos; /* Cache last read() position */
}
struct file结构体的核心inode文件索引节点(元数据),众多的inode组成inode table通过inode找到文件的源数据,我们这里核心介绍page cache文件系统相关的内容不做过多探讨。下图是相关数据对应的结构体关联关系:
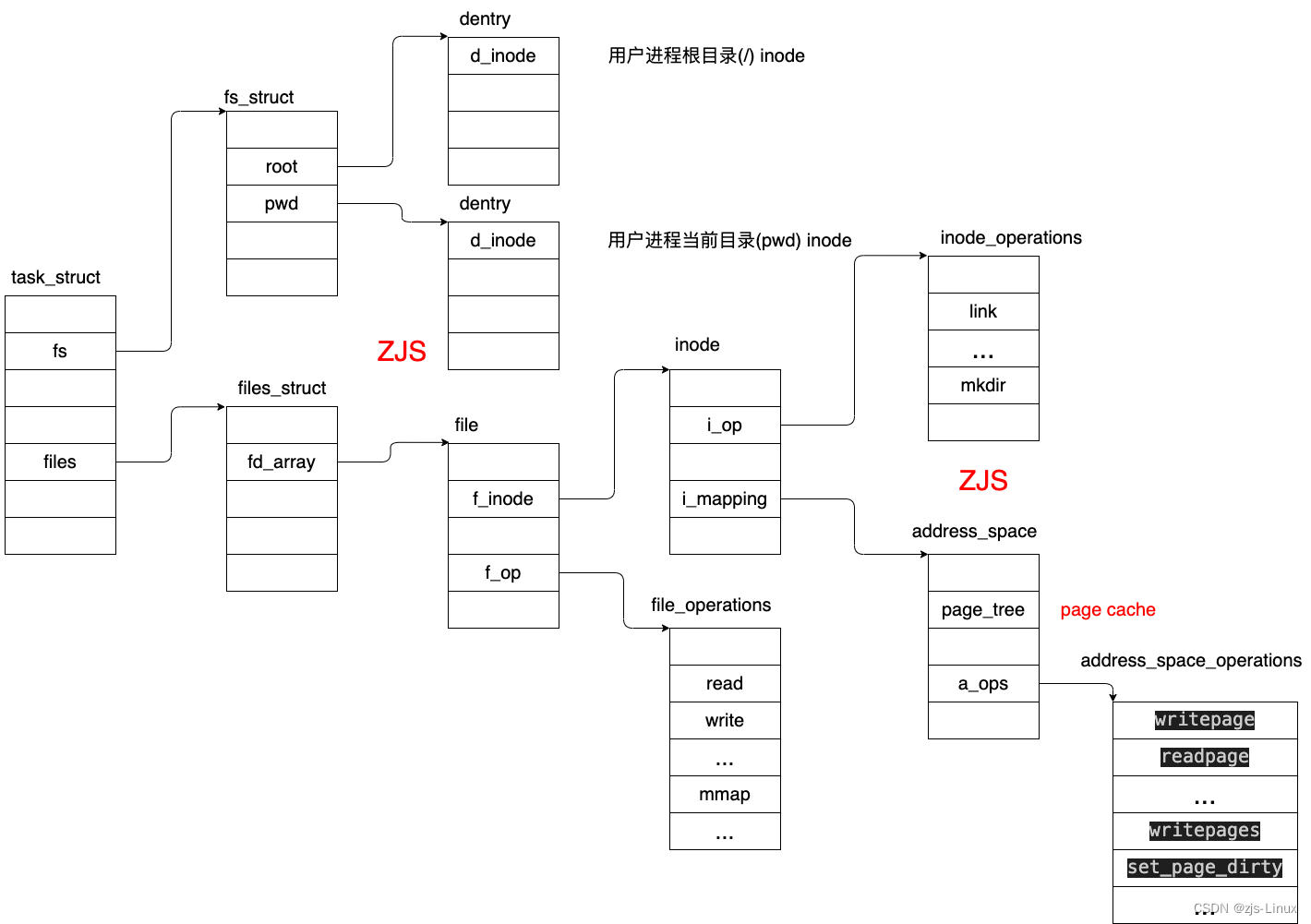
Linux page cache的管理就集中在struct inode -> struct address_space结构体当中,从此处作为切入点对page cache进行详细的分析。
Read
系统读写操作是用户层调用API read, write;在系统调用当中read操作对应的就是如下系统调用:
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
read
|-> vfs_read -> __vfs_read
|-> new_sync_read(file, buf, count, pos);
|-> call_read_iter
|-> ext4_file_read_iter //接口取决文件系统
|-> generic_file_read_iter
ssize_t generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
...
//IOCB_DIRECT 直接读取,不经过page cache/buffer 直接从磁盘当中读取文件
if (iocb->ki_flags & IOCB_DIRECT) {
...
//ext4_direct_IO
retval = mapping->a_ops->direct_IO(iocb, iter);
...
}
//read file from page cache, 本次分析重点在非direct io模式所以这里直接分析generic_file_buffered_read源码
retval = generic_file_buffered_read(iocb, iter, retval);
...
}
关键源码分析:
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
...
/* *ppos本次读取的起始地址,通过地址计算出文件页对应page的索引index */
index = *ppos >> PAGE_SHIFT;
/* readahead预读文件页page的索引index */
prev_index = ra->prev_pos >> PAGE_SHIFT;
/* readahead预读文件页的页内便宜(以4k为例不足时通过页内偏移读取剩余文件) */
prev_offset = ra->prev_pos & (PAGE_SIZE-1);
/* 本次要读取的文件结束地址的文件页page索引,iter->count是本次读取的文件字节数 */
last_index = (*ppos + iter->count + PAGE_SIZE-1) >> PAGE_SHIFT;
/* 页内偏移 */
offset = *ppos & ~PAGE_MASK;
/* 循环读取[index ~ last_index]对应的page进行文件的读取,总体概括一下就是先从page
* cache 当中查找文件如果没有找到则触发同步预读,如果顺利从page cache中找到文件则开启异步预读
* 最终将文件拷贝到user space共用户程序访问 */
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
unsigned long nr, ret;
cond_resched();
find_page:
if (fatal_signal_pending(current)) {
error = -EINTR;
goto out;
}
/* 根据page对应的index查找该page是否在page cache当中,
* 如果找到说明该文件对应的page已经被读取到的page cache当中
* 如果index对应的page没有在page cache当中找到就说明该文件对应的文件页并不在系统当中,需要从磁盘中读取 */
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
/* 如果是随机读FMODE_RANDOM模式则无法开启预读模式
* 如果无特殊设计这里就开始进行同步预读操作,并将读取后的page 加入到page cache当中进行管理
* 需要提到的是同步读取就是直接从磁盘当中进行文件读取 */
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
/* 经过同步预读,在page cache中大概率能找到index的page,如果还是找不到
* 就说明此在读取时并没有申请到page 这种情况就是系统内存不足才导致的预读失败 */
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
/* 文件预读时ondemand_readahead 设置了page SetPageReadahead
* 当判断到这个page被设置了readahead标志说明此时预读的文件页即将用完(还没用完)
* 此时就需要开启新一轮的预读,这种预读紧迫性不强所以可以通过异步预读的方式完成文件的异步预读 */
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
/* 从page cache中成功获取page后,判断是否为PG_update状态,按照设计当page完成读取后会设置PG_update
* 如果没有设置PG_update标志则说明该page状态并没有完成更新,该page可能还在使用当中
* 需要等待page状态完成更新 */
if (!PageUptodate(page)) {
if (iocb->ki_flags & IOCB_NOWAIT) {
put_page(page);
goto would_block;
}
/*
* See comment in do_read_cache_page on why
* wait_on_page_locked is used to avoid unnecessarily
* serialisations and why it's safe.
*/
/* 判断该page是否已经被加锁,如果没有锁则直接return 0说明该page没有被其他进程锁住,下一步继续判断该page
* 是否完成读取更新,如果page也完成更新设置PG_update则直接goto page_ok
* 如果page已经被锁,则需要等待该page的锁的释放(Wait for a page to be unlocked) 此时线程D状态
* 等待page解锁后重新检查page状态是否更新*/
error = wait_on_page_locked_killable(page);
if (unlikely(error))
goto readpage_error;
if (PageUptodate(page))
goto page_ok;
...
}//if (!PageUptodate(page))
page_ok:
/*
* i_size must be checked after we know the page is Uptodate.
*
* Checking i_size after the check allows us to calculate
* the correct value for "nr", which means the zero-filled
* part of the page is not copied back to userspace (unless
* another truncate extends the file - this is desired though).
*/
/* 通过文件的inode索引节点获取该文件大小,并将文件大小转换为index
* 如果index > end_index说明文件读取完毕直接goto out */
isize = i_size_read(inode);
end_index = (isize - 1) >> PAGE_SHIFT;
if (unlikely(!isize || index > end_index)) {
put_page(page);
goto out;
}
/* nr is the maximum number of bytes to copy from this page */
/* nr = 4K , 如果index = end_index则说明文件读取已经到了最后一个文件索引
* 通过isize获取到文件的offset偏移(文件自身offset),如果此时nr小于等于本次读取输入的offset
* 则说明文件读取完成,直接goto out完成读取并更新数据 */
nr = PAGE_SIZE;
if (index == end_index) {
nr = ((isize - 1) & ~PAGE_MASK) + 1;
if (nr <= offset) {
put_page(page);
goto out;
}
}
nr = nr - offset;
/* If users can be writing to this page using arbitrary
* virtual addresses, take care about potential aliasing
* before reading the page on the kernel side.
*/
if (mapping_writably_mapped(mapping))
flush_dcache_page(page);
/*
* When a sequential read accesses a page several times,
* only mark it as accessed the first time.
*/
if (prev_index != index || offset != prev_offset)
mark_page_accessed(page);
prev_index = index;
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
/* 将文件拷贝到user space,同时更新iter相关参数 */
ret = copy_page_to_iter(page, offset, nr, iter);
//文件读取页内偏移更新
offset += ret;
//更新index指向下一个page
index += offset >> PAGE_SHIFT;
//offset重新归零
offset &= ~PAGE_MASK;
prev_offset = offset;
put_page(page);
written += ret;
if (!iov_iter_count(iter))
goto out;
if (ret < nr) {
error = -EFAULT;
goto out;
}
continue;
...
readpage:
/*
* A previous I/O error may have been due to temporary
* failures, eg. multipath errors.
* PG_error will be set again if readpage fails.
*/
ClearPageError(page);
/* Start the actual read. The read will unlock the page. */
/* 正常情况下为文件读取都是通过预读机制完成的,但是如果预读过程异常那么该page可能就是无效内容
* 此时就必须采用这种方式重新读该文件页,这种读取操作效率是相对较低的 */
error = mapping->a_ops->readpage(filp, page);
}//for循环
would_block:
error = -EAGAIN;
out:
//prev_index保存最新一次读取的文件页page的索引,prev_offset保存最新一次读取的文件页里的偏移
ra->prev_pos = prev_index;
ra->prev_pos <<= PAGE_SHIFT;
ra->prev_pos |= prev_offset;
//文件指针偏移更新
*ppos = ((loff_t)index << PAGE_SHIFT) + offset;
file_accessed(filp);
return written ? written : error;
}
Readahead
预读分为同步预读、异步预读这两种预读方式针对的场景不同采取不同的预读策略,预读的核心设计就是ondemand_readahead
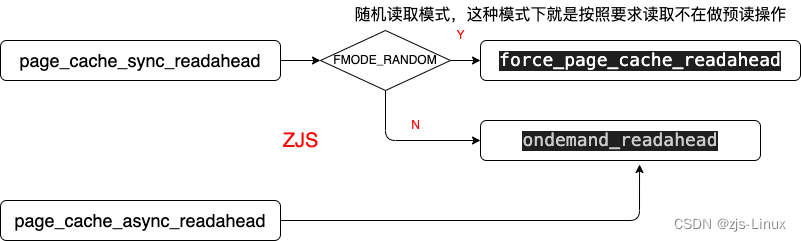
分析预读源码前先详细介绍一下预读结构体:
/*
* Track a single file's readahead state
*/
/*
|<----- async_size ---------|
|------------------- size -------------------->|
|==================#===========================|
^start ^page marked with PG_readahead
*/
struct file_ra_state {
/* 从start开始进行预读 */
pgoff_t start; /* where readahead started */
/* 预读page的个数,预读操作是有预读窗口大小的,如果内存充足则读取size个page 放入到预读窗口当中 */
unsigned int size; /* # of readahead pages */
/* 预读窗口中还剩async_size个page时启动异步预读, PageReadahead此时就会发挥作用 */
unsigned int async_size; /* do asynchronous readahead when
there are only # of pages ahead */
/* 预读最大窗口,也就是说此时一次性只能预读ra_pages个文件页
* 默认等于struct backing_dev_info->ra_pages, 可通过fadvise64_64调整。
* 如果read需要读的page数量小于ra_pages,最多读取ra_pages个页面。
* 如果read需要读的page数量大于ra_pages,最多读取min { read的page数量,存储器件单次io最大page数量 }个页面。*/
unsigned int ra_pages; /* Maximum readahead window */
unsigned int mmap_miss; /* Cache miss stat for mmap accesses */
/* 最后一次的预读位置,为后续偏移保存数据 */
loff_t prev_pos; /* Cache last read() position */
}
关键源码分析:
/* hit_readahead_marker = true/flase决定此次预读是同步预读或异步预读 */
static unsigned long ondemand_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
bool hit_readahead_marker, pgoff_t offset,
unsigned long req_size)
{
struct backing_dev_info *bdi = inode_to_bdi(mapping->host);
/* 获取最大预读窗口 */
unsigned long max_pages = ra->ra_pages;
unsigned long add_pages;
pgoff_t prev_offset;
/*
* If the request exceeds the readahead window, allow the read to
* be up to the optimal hardware IO size
*/
/* 如果读取req_size大于输入的预读最大窗口且器件运行的最大IO个数大于输入的最大预读窗口则变更max_pages
* 取req_size, bdi->io_pages中相对最小的预读数据作为预读的最大窗口
*/
if (req_size > max_pages && bdi->io_pages > max_pages)
max_pages = min(req_size, bdi->io_pages);
/*
* start of file
*/
if (!offset)
goto initial_readahead;
/*
* It's the expected callback offset, assume sequential access.
* Ramp up sizes, and push forward the readahead window.
*/
/* 预读结构体结构如下,该判断分支存在两种可能:
|<----- async_size ---------|
|------------------- size -------------------->|
|==================#===========================|
^start ^page marked with PG_readahead
第一、 offset == (ra->start + ra->size - ra->async_size)
演示图如下: 假设ra->start = 0, ra->size = 16, ra->async_size = 3
|——|——|——|——|——|——|——|——|——|——|——|——|——|——|——|——|
| |
start offset mark PG_readahead
则offset = ra->size - ra->async_size = 13, 说明此时offset在预读窗口范围内
所以可以明确的是预读的page已经被使用且预读的窗口即将被使用完毕, ra->size - ra->async_size
剩余的预读文件为下一次read做准备,offset偏移的page被setPageReadahead标志,当下一轮read读取文件时检测
到page状态为PageReadahead时开启异步预读。
第二、offset == (ra->start + ra->size)
演示图如下:假设ra->start = 0, ra->size = 8,
|——|——|——|——|——|——|——|——|...|——|——|——|——|——|——|——|——|
| | | |
start size now start size
则offset = ra->start + ra->size说明上一次预读窗口当中的数据已经被全部用完,offset就是下一次预读的
首个page与第一种可能一样offset对应的page被设置为mark PG_readahead, 当开启下一轮read读取时检测到
下一轮预读窗口的第一个page是PageReadahead时就会开启新一轮异步预读为read做准备。
*/
if ((offset == (ra->start + ra->size - ra->async_size) ||
offset == (ra->start + ra->size))) {
/*
* start + size作为下一次预读的start起始地址
* get_next_ra_size
* 如果ra->size < max_pages/16则更新ra->size = ra->size*4
* 如果ra->size >= max_pages/16则更新ra->size = ra->size*2
* 虽然ra->size预读窗口被扩大但是预读窗口最大不能超过max_pages
* Normally async_size will be equal to size, for maximum pipelining.
*/
ra->start += ra->size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
/*
* Hit a marked page without valid readahead state.
* E.g. interleaved reads.
* Query the pagecache for async_size, which normally equals to
* readahead size. Ramp it up and use it as the new readahead size.
*/
/* 当hit_readahead_marker = true则本次为异步预读, 尝试从page cache当中查找,
* 找到第一个没有在page cache中的页作为预读的起始地址进行后续的预读, start就是offset + max_pages,
* 如果发现index对应的page全部都在page cache就更加高效
* 如果是顺序读如果在没有读到的情况下page不可能在page cache当中,所以这样就一种可能就是interleaved reads 多线程并行读取
* 对于某些线程来说读取的文件部分可能已经被其他进程读取到page cache当中此时只需要从page cache当中查找就可以不用在做顺序
* 也存在另外一种可能就是通过预读已经将page读取到page cache当中所以下一次只需要从page cache中查找即可,直到确认某个
* page不在page cache当中再去开启预读这样就更加高效。
* */
if (hit_readahead_marker) {
pgoff_t start;
rcu_read_lock();
start = page_cache_next_hole(mapping, offset + 1, max_pages);
rcu_read_unlock();
if (!start || start - offset > max_pages)
return 0;
/* 以没有在page cache中的page对应的index索引作为预读的start起始地址
* start - offset就是本次预读窗口的大小(从page cache hole中查找到的page个数也是预读size的一部分)
* start - offset + req_size是需要预读的窗口大小
* get_next_ra_size
* 如果ra->size < max_pages/16则更新ra->size = ra->size*4
* 如果ra->size >= max_pages/16则更新ra->size = ra->size*2
* 虽然ra->size预读窗口被扩大但是预读窗口最大不能超过max_pages
* Normally async_size will be equal to size, for maximum pipelining.
*/
ra->start = start;
ra->size = start - offset; /* old async_size */
ra->size += req_size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
/*
* oversize read
*/
if (req_size > max_pages)
goto initial_readahead;
/*
* sequential cache miss
* trivial case: (offset - prev_offset) == 1
* unaligned reads: (offset - prev_offset) == 0
*/
prev_offset = (unsigned long long)ra->prev_pos >> PAGE_SHIFT;
if (offset - prev_offset <= 1UL)
goto initial_readahead;
/*
* Query the page cache and look for the traces(cached history pages)
* that a sequential stream would leave behind.
*/
if (try_context_readahead(mapping, ra, offset, req_size, max_pages))
goto readit;
/*
* standalone, small random read
* Read as is, and do not pollute the readahead state.
*/
return __do_page_cache_readahead(mapping, filp, offset, req_size, 0);
initial_readahead:
/* 第一次预读
* 如果预读窗口大于需要读取的page数则ra->async_size = ra->size - req_size
* 此时ra->size - ra->async_size 对应的page会被标记PG_readahead
* 如果预读窗口小于需要读取的page数则ra->async_size = ra->size 这种情况就是下一轮预读的page
* 会被标记PG_readahead */
ra->start = offset;
ra->size = get_init_ra_size(req_size, max_pages);
ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;
readit:
/*
* Will this read hit the readahead marker made by itself?
* If so, trigger the readahead marker hit now, and merge
* the resulted next readahead window into the current one.
* Take care of maximum IO pages as above.
*/
/* 预读窗口加上可获取的最大预读窗口如果还在最大预读窗口范围内
* 更新async_size将这个数据拉大,同样size += add_pages将预读窗口拉大
* |<------ async_size -----------|
* |----------- size ------------>|
* |==============================|
* ^start(offset)
*
* 演变成如下示意图:将整个预读窗口拉大,能预读更多文件 实际上add_pages >= size
* |<-----------async_pages---------->|
* |---------------------------size + add_pages----------------------|
* |=================================================================|
* ^start(offset)
* 从代码上分析可以看到这个设计是针对异步预读设计的也就是hit_readahead_marker = true
* 当第一个page也就是offset就被检查出PageReadahead进入异步预读,说明此时系统当中已经
* 没有预留预读文件可供读取使用,此时在offset, ra->start没有变化的情况下将预读空间扩大
* add_pages。相当于将两次预读拼接到了一起,这样的操作使得预读更加高效(If so, trigger the readahead marker hit now,
* and merge the resulted next readahead window into the current one)。
* 如果ra->size + add_pages >= max_pages 则add_pages = max_pages,async_pages = max_pages/2
*/
if (offset == ra->start && ra->size == ra->async_size) {
/* add_pages获取不超过max_page最大预读窗口 */
add_pages = get_next_ra_size(ra, max_pages);
if (ra->size + add_pages <= max_pages) {
ra->async_size = add_pages;
ra->size += add_pages;
} else {
ra->size = max_pages;
ra->async_size = max_pages >> 1;
}
}
/* 实际调用__do_page_cache_readahead(mapping, filp, ra->start, ra->size, ra->async_size) */
return ra_submit(ra, mapping, filp);
}
int __do_page_cache_readahead(struct address_space *mapping, struct file *filp,
pgoff_t offset, unsigned long nr_to_read,
unsigned long lookahead_size)
{
struct inode *inode = mapping->host;
struct page *page;
unsigned long end_index; /* The last page we want to read */
LIST_HEAD(page_pool);
int page_idx;
int ret = 0;
/* 通过文件inode索引节点获取文件大小 */
loff_t isize = i_size_read(inode);
gfp_t gfp_mask = readahead_gfp_mask(mapping);
if (isize == 0)
goto out;
/* 文件大小转换为page数,转化为page的index索引 */
end_index = ((isize - 1) >> PAGE_SHIFT);
/*
* Preallocate as many pages as we will need.
*/
/* 通过偏移循环的从page cache中获取index对应的page,如果在page cache当中
* 无法获取page则直接allocated pages并将申请到的page加入到page_pool内存池当中 */
for (page_idx = 0; page_idx < nr_to_read; page_idx++) {
/* offset + page_idx就是当前文件对应的index */
pgoff_t page_offset = offset + page_idx;
/* 如果page_offset > end_index说明文件读取完毕直接break即可 */
if (page_offset > end_index)
break;
rcu_read_lock();
page = radix_tree_lookup(&mapping->page_tree, page_offset);
rcu_read_unlock();
if (page && !radix_tree_exceptional_entry(page))
continue;
page = __page_cache_alloc(gfp_mask);
if (!page)
break;
/* 从buddy当中申请的新的page,将当前page_offset赋值给当前page->index保证文件的延续 */
page->index = page_offset;
list_add(&page->lru, &page_pool);
/* lookahead_size是ra->async_size, nr_to_read即ra->size
* page_idx = ra->size - ra->async_size
* |<----- async_size ---------|
* |------------------- size -------------------->|
* |==================#===========================|
* ^start ^page_idx marked with PG_readahead
* 此时page_idx对应的page被标志PG_readahead也就是SetPageReadahead(page)
* 当read过程检查到page被设置PG_readahead则开启预读。一定程度上我们可以说page预读真正的
* 数值是ra->async_page。
*/
if (page_idx == nr_to_read - lookahead_size)
SetPageReadahead(page);
ret++;
}
/*
* Now start the IO. We ignore I/O errors - if the page is not
* uptodate then the caller will launch readpage again, and
* will then handle the error.
*/
/* mapping->a_ops->readpage函数的回调函数依赖文件系统格式比如ext4则实际运行ext4_readpage
* 将文件读取到page_pool内存链表当中 */
if (ret)
read_pages(mapping, filp, &page_pool, ret, gfp_mask);
BUG_ON(!list_empty(&page_pool));
out:
return ret;
}
三、 Readahead原理演示
设置前提:以page 4K为单位, max_pages = 64最大预读page数64,且读取过程为顺序读,演示将给我们揭示一个重要的信息:ra->async_size就是每次预读的实际预读大小
第一次读取:
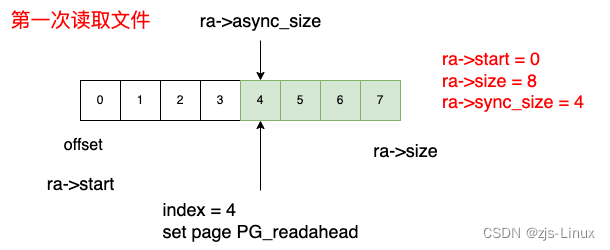
第一次读取16KB文件也就是4个page, 因为是第一次读取文件所以page cache当中没有该文件对应的page,所以开启同步预读;这种情况下ra->start = 0, ra->size = 8(小于Max_pages), ra->async_size = 4,可以知道offset = ra->start + ra->size - ra->async_size = 4此时整个ra->size整个预读窗口的8个page全部被读取到page cache当中,同时前4个page是被真正读取使用的,index = 4对应的page 被SetPageReadahead(page) 。此时我们页可以说本次读取预读了4个page(也就是async_size大小)
第二次读取:
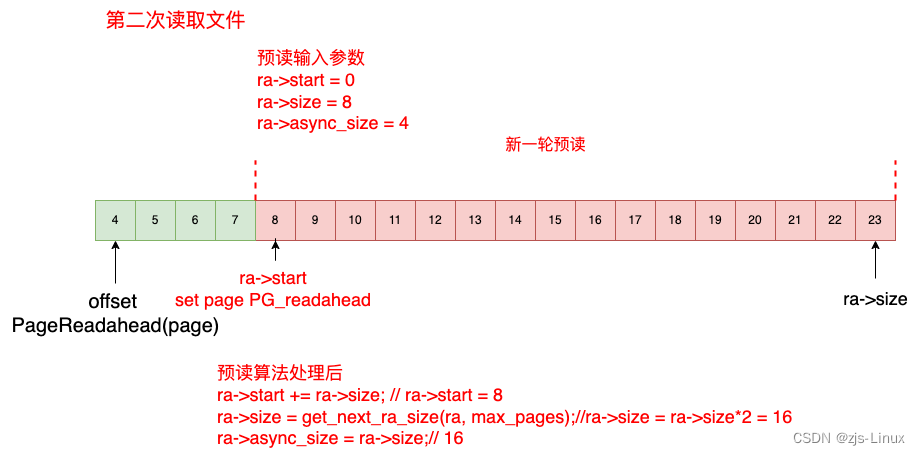
第二次读取16KB文件,接上次预读可以知道index = 4对应的page 被设置了PG_readahead标志,这种情况下开启异步预读offset = 4, ra->start + ra->size - ra->async_size = 0 + 8 - 4; 该条件下更新预读信息。开始预读,第二次预读offset = 4 首先从page cache当中读取index 4 ~ index 7, 从index 8 开始新一轮的预读并更新预读起始地址及预读窗口大小。
第三次读取:
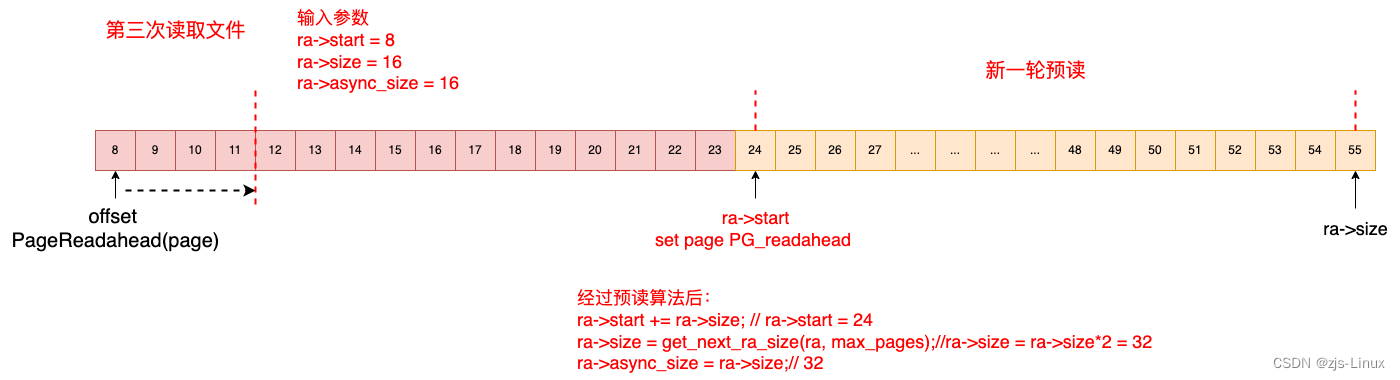
第三次读取16KB文件,接上次预读可以知道offset = 8,读取文件对应的page是index 8 ~ index 11。因为index = 8 page 被设置PG_readahead标志需要开启新一轮预读,此时根据预读算法此次需要预读32个page,同时将index = 24 page set PG_readahead
第四 ~ 六 次读取:
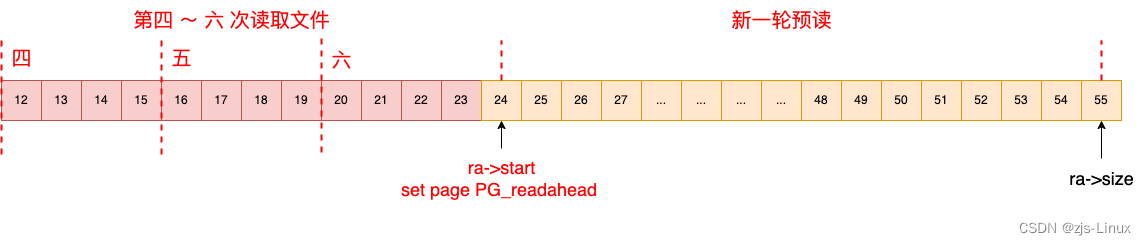
第四次读取16KB文件,接上次预读可以知道offset = 12,读取文件对应的page是index 12 ~ index 15, 因为预读需要的page已经被夹在到page cache当中,所以本次读取直接从page cache当中读取即可,本次不需要触发预读。同样的处理第五次,第六次读取都是直接从page cache当中直接读取,大大提高的文件读取效率。
第七次读取:
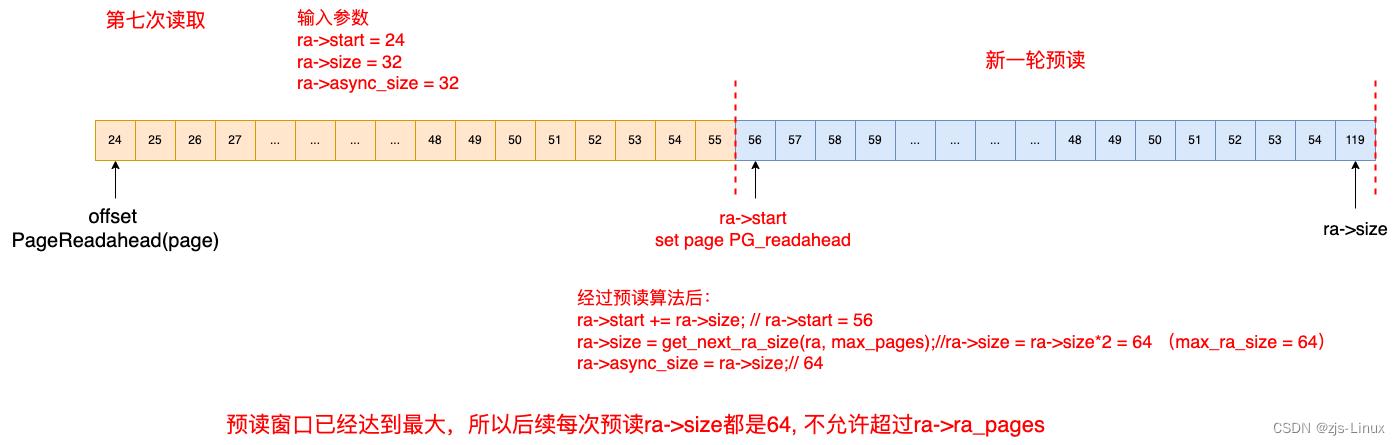
第七次读取16KB文件,接上次预读可以知道offset = 24,读取文件对应的page是index 24 ~ index 27。因为index = 24 page 被设置PG_readahead标志需要开启新一轮预读,此时根据预读算法此次需要预读64个page,同时将index = 56 page set PG_readahead。特别注意的是本次预读的预读窗口已经达到最大的64,所以后续无论什么场景情况下最大的预读窗口都是64。
四、参考
https://www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
https://lwn.net/Articles/254856/
https://brendangregg.com/blog/2014-12-31/linux-page-cache-hit-ratio.html















 5398
5398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









