






 本文详细介绍了BPTT算法在RNN中的应用,以及梯度消失问题,包括其原因和影响。通过分析计算梯度的过程,揭示了tanh和sigmoid激活函数导致的梯度消失,并探讨了ReLU如何缓解这一问题。最后,提到了LSTM和GRU作为解决梯度消失的有效方案。
本文详细介绍了BPTT算法在RNN中的应用,以及梯度消失问题,包括其原因和影响。通过分析计算梯度的过程,揭示了tanh和sigmoid激活函数导致的梯度消失,并探讨了ReLU如何缓解这一问题。最后,提到了LSTM和GRU作为解决梯度消失的有效方案。
在本教程的前面部分,我们从头实现了RNN,但没有详细介绍如何通过BPTT算法计算梯度。在本部分中,我们将简要概述BPTT并解释它与传统反向传播的区别。然后我们将尝试理解消失梯度问题,这导致了LSTM和GRU的发展,这两个是目前应用于NLP(和其他领域)最流行的模型。消失梯度问题最初是由Sepp Hochreiter于1991年发现的,最近由于深度架构的应用的增加而受到关注。
要完全理解这一部分,我建议你先熟悉微分链式规则和基本反向传播原理。如果你不熟悉,你可以以增加难度的顺序在这里,这里和这里找到优秀的教程。
BPTT
让我们快速回顾一下RNN的基本方程。注意,现在o变成了 y^ ,这只是为了参考的一些文献保持一致。
我们也定义了损失(或错误)是交叉熵损失:
这里
yt
是时刻t正确的单词(输出),
y^t
是预测值。我们通常把整个序列(一个句子)当作一个训练样本,总的损失就是每个时刻(单词)的损失之和。
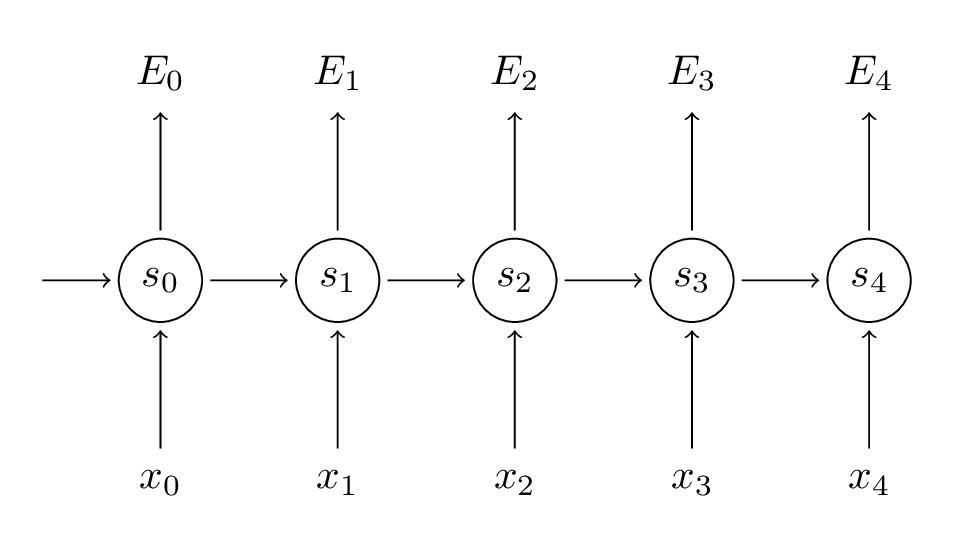
记住,我们的目标是计算参数 U,V和W 的误差梯度,然后使用随机梯度下降学习好的参数。就像把损失值加和一样,我们把一个训练样本每个时刻的梯度也加起来: ∂E∂W=∑t∂Et∂W 。
为了计算这些梯度,我们使用微分链式的规则。这是从错误开始应用反向传播的反向传播算法。对于本文的其余部分,我们将使用 E3 作为例子。
在上式中, m3=Vs3 , and ⊗ 是 两个向量的外积。我想要说明的一点是 ∂E3∂V 只取决于当前时间步长的值 y^3,y3,s3 。如果你有了这些,计算V的梯度就是简单矩阵乘法。
但是计算
∂E3∂W
(and for
U
) 就是另外一回事了。我们在后向传播上那样,定义后向传播的
用代码实现一个原生的BPTT大概像如下这样:
def bptt(self, x, y):
T = len(y)
# Perform forward propagation
o, s = self.forward_propagation(x)
# We accumulate the gradients in these variables
dLdU = np.zeros(self.U.shape)
dLdV = np.zeros(self.V.shape)
dLdW = np.zeros(self.W.shape)
delta_o = o
delta_o[np.arange(len(y)), y] -= 1.
# For each output backwards...
for t in np.arange(T)[::-1]:
dLdV += np.outer(delta_o[t], s[t].T)
# Initial delta calculation: dL/dz
delta_t = self.V.T.dot(delta_o[t]) * (1 - (s[t] ** 2))
# Backpropagation through time (for at most self.bptt_truncate steps)
for bptt_step in np.arange(max(0, t-self.bptt_truncate), t+1)[::-1]:
# print "Backpropagation step t=%d bptt step=%d " % (t, bptt_step)
# Add to gradients at each previous step
dLdW += np.outer(delta_t, s[bptt_step-1])
dLdU[:,x[bptt_step]] += delta_t
# Update delta for next step dL/dz at t-1
delta_t = self.W.T.dot(delta_t) * (1 - s[bptt_step-1] ** 2)
return [dLdU, dLdV, dLdW]从这里你可以看出为什么标准的RNN对于训练长序列(句子),20个单词或更多的句子非常困难了,因为你需要后向传播很多层。在实践中,许多人将反向传播截断到几个步骤。
梯度消失问题
让我们再仔细看一下我们上面计算的梯度:
我们可以把上面的梯度写成:
因为 tanh(或sigmoid )激活函数将所有值映射到-1和1之间的范围内,导数的取值也限制在(0,1](在 sigmoid 的情况下为(0,1/4]):

可以看出 tanh and sigmoid 函数在两头趋于直线,导数趋于0。这种情况下对应的神经元是饱和的, 它们的梯度是0,并且驱使前面层的梯度也朝0发展。因此,有了矩阵中很小的值以及多个矩阵乘法(特别是t-k),梯度值以指数的速度收缩,最终在几个时刻之后完全消失。来自“远处”时刻的梯度贡献值变为零,这些时刻的状态对正在学习的内容没有贡献:最终学习不到远程依赖关系。梯度消失不仅仅发生在RNN的中。它们也发生在非常深的前馈神经网络中。这只是RNN通常非常深(就像我们的例句一样长),使得这个问题更常见。
很容易想象,根据我们的激活函数和网络参数,如果Jacobian矩阵的值很大,梯度将会爆炸而不是消失。这被称为梯度爆炸问题。梯度消失比梯度爆炸更受关注的原因有两方面的。首先,梯度爆炸是显而易见的,梯度将成为NaN(不是一个数字),你的程序会崩溃。其次,通过预定义的阈值(如这篇论文所讨论的那样)中截取梯度,对爆炸梯度来说是非常简单有效的解决方案。梯度消失有更多的问题,因为当它们发生时不是很明显,处理它们的方法也不是很容易想到。
幸运的是,有几种方法可以缓解梯度消失问题。
W
矩阵的适当初始化可以减少梯度消失的影响。也可以通过正则化缓解。更好的解决方案是使用















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









