







1.算法引入
先举一个简单的例子来介绍一下决策树到底是个什么东西。(参考:)
一个母亲要给女儿介绍对象,所以有了如下的对话:
女儿:多大年纪了?
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的判断过程就是一个决策树,她根据自己设置的一些标准(属性)来对男方做是或者否的判断,可以大致用以下图来表示:
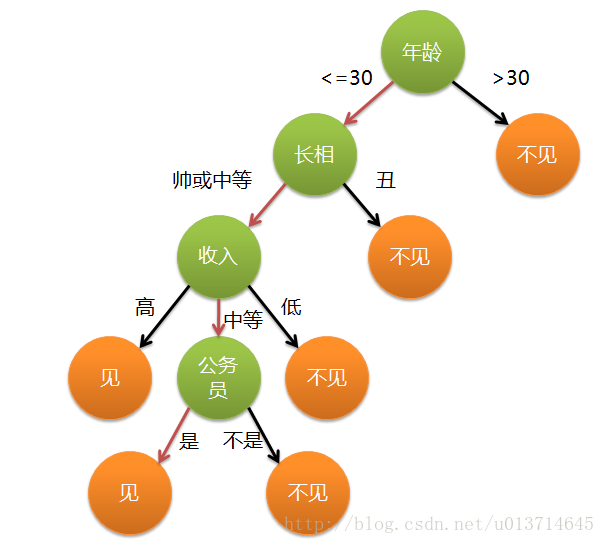
实际上,决策树的原理就是:根据样本的属性,生成一系列的规则,来对样本进行判断。每一个根节点就是属性分裂点,每一个叶子节点就是判别结果。决策树既可以处理离散变量,也可以处理连续变量。
2.决策树的学习过程
一颗决策树的生成过程主要分为以下三步:
(1)特征选择:特征选择是指从众多的特征中选择一个特征作为当前分裂的节点的分裂标准。如何选择分裂的标准,这是决策树的核心部分,也是众多决策树算法的不同点,后面会详细叙述。
(2)决策树生成:根据选择的特征评估标准,从上至下递归的生成子节点,直到数据集不能再分裂为止,整个过程就是一个递归。
(3)树剪枝:通过缩小树结构规模,缓解过拟合,有预剪枝和后剪枝两种。
3.几种不同的决策树算法
(1)ID3:以信息增益度量为属性选择,选择分裂后信息增益最大的属性进行分裂( 从信息论知识中我们知道,期望信息越小,信息增益越大,从而纯度越高)
注:期望信息越小,就是了解或者发生这件事情的所需要的信息越少,是不是意味着这件事情更容易发生,也就是分类越准确。
设D为用来分裂的属性,D的熵(entropy)为:
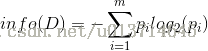
Pi:表示i类在整个训练集中的概率(可以认为是频率,也是i类的占比)。该式表示,我们要判断一个样本属于i类,所需要的平均信息量。
按照D属性分裂后的熵:
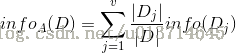
j:第j类,结果求和
|Dj/D|:属性的记录占总样本的比例
信息增益是二者的差值,前者减去后者,保证信息增益为正数:
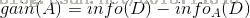
ID3每次分裂时,计算每个属性的增益,然后按照最大增益的属性分裂。举一个比较经典的例子:
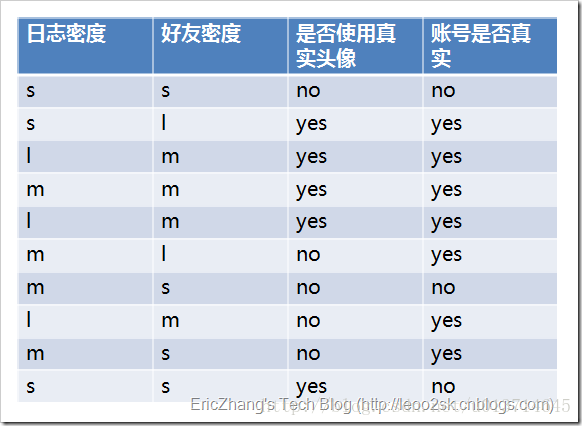
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
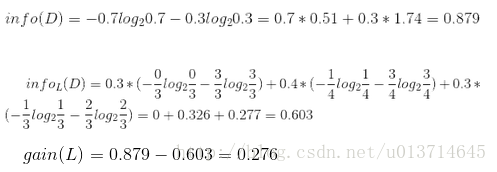
因此日志密度的信息增益是0.276。用同样方法得到H和F的信息增益分别为0.033和0.553。因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
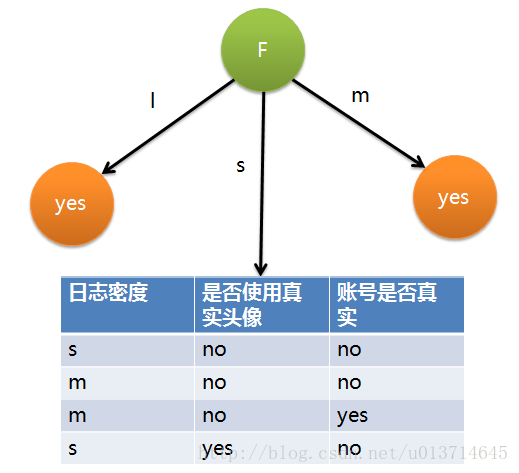
后面节点的分裂过程一样
缺点:
ID3存在一个问题,偏向多值属性。也就是说,若某个属性所取的不同值越多,那么越有可能拿它来做分裂属性。例如,如果存在唯一标识,ID3会选择它作为分裂属性,这样的分裂是没有意义的。什么意思呢?假如我想知道一群人中的收入的高低,给出的属性有每个人的名字,平时消费的高低等,ID3会根据名字进行分裂,这样的出来的结果能判断一个人的收入高低么?这样分裂的目标就不是我们所需要的了。
(2)C4.5算法
C4.5是ID3的改进算法(具体为啥叫这名,好像是说C4和C5都被用了,然后就叫了这个,但为啥不叫C6,这我也不知道)。它使用信息增益率来选择属性,克服了ID3偏向多值属性的缺点,公式:

C4.5既可以处理离散值又可以处理连续值,离散值和ID3一样。
在C4.5中,对连续属性的处理如下:
1、对特征的取值进行升序排序
2、两个特征取值之间的中点作为可能的分裂点,将数据集分成两部分,计算每个可能的分裂点的信息增益(InforGain)。优化算法就是只计算分类属性发生改变的那些特征取值。
3、选择修正后信息增益(InforGain)最大的分裂点作为该特征的最佳分裂点
4、计算最佳分裂点的信息增益率(Gain Ratio)作为特征的Gain Ratio。注意,此处需对最佳分裂点的信息增益进行修正:减去log2(N-1)/|D|(N是连续特征的取值个数,D是训练数据数目,此修正的原因在于:当离散属性和连续属性并存时,C4.5算法倾向于选择连续特征做最佳树分裂点)
(3)CART
CART算法的全称是Classification And Regression Tree,采用的是Gini指数(选Gini指数最小的特征s)作为分裂标准,同时它也是包含后剪枝操作。ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支较大,规模较大。为了简化决策树的规模,提高生成决策树的效率,就出现了根据GINI系数来选择测试属性的决策树算法CART
4.树剪枝
决策树很容易造成过拟合,有时会过分拟合数据中的噪声和孤立点,减缓过拟合的方法一般使用树剪枝,分为预剪枝和后剪枝。
预剪枝:根据一些原则及早的停止树增长,如树的深度,节点中样本数,不纯指标下降的最大深度等,核心问题是如何事先指定树的最大深度。
后剪枝:通过在完全生长的树上减去分支,删除节点。方法有很多种,如:代价复杂性剪枝,最小误差剪枝等(实际上就是剪枝-检验-和剪枝前对比-是否剪枝)
5.几点补充说明
(1)如果属性用完了咋办?即所有属性用完了,但有的子集还是不纯集,即集合内的元素不属于同一类别。
一般对这些子集进行多数表决,用该子集中的最多的类别作为节点类别。















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









