







 本文深入讲解深度信念网络(DBN)的结构与训练流程,包括基于限制玻尔兹曼机(RBM)的预训练及反向传播(BP)网络的微调阶段。探讨了能量函数在无监督学习中的作用,以及如何通过Gibbs采样等方法进行模型训练。
本文深入讲解深度信念网络(DBN)的结构与训练流程,包括基于限制玻尔兹曼机(RBM)的预训练及反向传播(BP)网络的微调阶段。探讨了能量函数在无监督学习中的作用,以及如何通过Gibbs采样等方法进行模型训练。
深度信念网络结构,经典结构,直接上图:
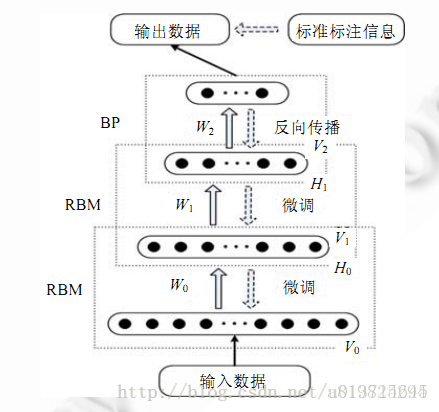
DBN由多个RBM堆叠而成,训练过程由预训练和微调构成
深度信念网络训练步骤:
(1)预训练:分别单独无监督的训练每一层RBM网络,确保特征向量映射到不同特征空间,都尽可能的保留特征信息;它通过一个非监督贪婪逐层方法预训练获得权重(即不要类标,不断拟合输入,依次逐层)。在这个过程中,数据输入到可见层,生成一个向量V,在通过权值w传给隐藏层,得到h,由于隐藏层之间是无连接的,所以可以并行得到隐藏层所有节点值。通过隐层激活单元和可视层输入之间的相关性差别(通过能量函数来度量网络的稳定性,优化函数是根据求能量函数球指数后,归一化,然后最大似然得到)就作为权值更新的主要依据。具体公式?
从单层的RBM训练说起,可见层是用来接受输入信号,隐藏层用来提取特征,RBM是通过无监督学习自动找到研究问题的最佳特征。

什么是能量函数呢?我觉得网上这段解释的比较好,我就直接copy了
这里说一下 RBM 的能量模型,这里关系到 RBM 的理解 能量模型是个什么样的东西呢?直观上的理解就是,把一个表面粗糙又不太圆的小球, 放到一个表面也比较粗糙的碗里,就随便往里面一扔,看看小球停在碗的哪个地方。一般来 说停在碗底的可能性比较大,停在靠近碗底的其他地方也可能,甚至运气好还会停在碗口附 近(这个碗是比较浅的一个碗);能量模型把小球停在哪个地方定义为一种状态,每种状态都对应着一个能量E,这个能量由能量函数来定义,小球处在某种状态的概率(如停在碗底的概率跟停在碗口的概率当然不一样)可以通过这种状态下小球具有的能量来定义(换个说 法,如小球停在了碗口附近,这是一种状态,这个状态对应着一个能量E ,而发生“小球停 在碗口附近”这种状态的概率 p ,可以用E 来表示,表示成p=f(E),其中 f 是能量函数, 其实还有一个简单的理解,球在碗底的能量一般小于在碗边缘的,比如重力势能这,显然碗 底的状态稳定些,并且概率大些。 也就是说,RBM采用能量模型来表示系统稳态的一种测度。这里可以注意到 RBM 是一种随机网络,描述一个随机网络,主要有以下 2 点 :
1. 概率分布函数。各个节点的取值状态是概率的、随机的,这里用了 3 种概率分布来描述 整个 RBM 网络,有联合概率密度,条件概率密度和边缘概率密度。
2. 能量函数。随机神经网络的基础是统计力学,差不多思想是热力学来的,能量函数是描 述整个系统状态的一种测度。系统越有序或者概率分布越集中(比如小球在碗底的情况), 系统的能量越小,反之,系统越无序并且概率分布发散(比如平均分布) ,则系统的能量 越大,能量函数的最小值,对应着整个系统最稳定的状态。 这里跟之前提到的最大熵模型思路是一样的。
RBM 能量模型的作用是什么呢?为什么要弄清楚能量模型的作用呢? 第一、 RBM 网络是一种无监督学习的方法,无监督学习的目的自然就是最大限度的拟 合输入数据和输出数据。 第二、 对于一组输入数据来说,如果不知道它的分布,那是非常难对这个数据进行学 习的。例如:如果我们实现写出了高斯函数,就可以写出似然函数,那么就可 以进行求解,就知道大致的参数,所以实现如果不知道分布是非常痛苦的一件 事情,但是,没关系啊,统计力学的一项研究成果表明,任何概率分布都可以 转变成基于能量的模型,即使这个概率分布是未知的,我们仍然可以将这个分布改写成能量函数。 第三、 能量函数能够为无监督学习方法提供 2 个特殊的东西 a)目标函数。 b)目标解, 换句话说,使用能量模型使得学习一个数据的变得容易可行了。 能否把最优解的求解嵌入能量模型中至关重要,决定着我们具体问题求解的好坏。能量模型要捕获变量之间的相关性,变量之间的相关程度决定了能量的高低。把变量的相关关系用图表示 出来,并引入概率测度方式就构成了概率图(为什么是概率图?前面一句说了, RBM 是一个图,以概率为测度,所以是概率图)模型的能量模型。总而言之,一句话,通过定义求解网络的能量函数,我们可以得到输入样本的分布,这样我们就相当于有了目标函数,就可以训练了。(copy自参考资料(1))
具体怎么进行更新呢?首先我们有个能量函数,就是前面的那个形式,通过能量函数,我们可以得到系统随机变量的概率分布:
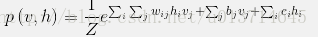
这个概率分布,实际上就是我们的目标函数,他是一个包含,可见层向量v,隐藏层向量h,还有可见层与隐藏层权值w,偏置的函数。也可以认为是对能量函数求指数e,然后归一化后的结果。样本的一个状态对应着一个能量,相应的概率分布就对应着能量的概率分布。然后对这个函数求它的对数似然。
具体的训练过程如下:

PS:Gibbs采样:Gibss采用是需要知道样本中一个属性在其它所有属性下的条件概率,然后利用这个条件概率来分布产生各个属性的样本值:

Gibbs采样的目的是生成一个样本。(感觉还有好多没搞懂,姑且知道到它是干嘛的吧)
(2)微调:在 DBN 的最后一层设置 BP 网络,接收 RBM 的输出特征向量作为它的输入特征向量,有监督地训练实体关系分类器.而且每一层 RBM 网络只能确保自身层内的 权值对该层特征向量映射达到最优,并不是对整个 DBN 的特征向量映射达到最优,所以反向传播网络还将错误信息自顶向下传播至每一层 RBM,微调整个 DBN 网络.RBM 网络训练模型的过程可以看作对一个深层 BP 网络权值参数的初始化,使DBN 克服了 BP 网络因随机初始化权值参数而容易陷入局部最优和训练时间长的缺点.
BP神经网络可以看我的另一篇博客。
参考网址:
(1)http://blog.csdn.net/app_12062011/article/details/54313082
(2)http://blog.csdn.net/losteng/article/details/51001247
(3)http://m.blog.csdn.net/NIeson2012/article/details/52184189
(4)http://blog.csdn.net/Rainbow0210/article/details/53010694?locationNum=1&fps=1
(5)http://blog.csdn.net/yywan1314520/article/details/51013410
(6)http://blog.csdn.net/zb1165048017/article/details/51778694

















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









