






英文原文:https://www.datacamp.com/tutorial/fine-tuning-gpt-3-using-the-open-ai-api-and-python
通过微调释放 GPT-3 的全部潜力。 了解如何使用 OpenAI API 和 Python 来针对您的特定用例改进此高级神经网络模型。
内容:
- 哪些GPT模型可以微调?
- 微调 GPT 的良好用例有哪些?
- 微调 GPT-3 的逐步实现
- 结论
GPT-3,第三代生成式预训练Transformer。 是OpenAI创建的前沿神经网络深度学习模型。 通过使用大量互联网数据,GPT-3 可以用最少的输入生成多样化且强大的机器生成文本。 GPT-3 具有广泛的应用范围,不仅限于文本摘要、翻译、聊天机器人开发和内容生成。
尽管具有稳健性,但 GPT-3 的性能可以通过针对特定用例进行微调来进一步提高。
但是微调是什么意思呢?
这是在自定义用例数据集上训练预训练 GPT-3 的过程。 这使得模型能够更好地适应特定用例或领域的细微差别,从而获得更准确的结果。
成功执行微调的先决条件是(1)对 Python 编程有基本了解,(2)熟悉机器学习和自然语言处理。
我们的机器学习分类:简介文章可帮助您了解机器学习中的分类,了解它是什么、它如何使用以及分类算法的一些示例。
我们将使用OpenAI提供的openai Python包,以便更方便地使用他们的API并访问GPT-3的功能。
本文将介绍使用 Python 对用户自己的数据进行 GPT-3 模型的微调过程,涵盖从获取 API 凭证到准备数据、训练模型和验证模型的所有步骤。
哪些GPT模型可以微调?
可以微调的GPT模型包括Ada、Babbage、Curie和Davinci。 这些模型属于 GPT-3 系列。 另外,值得注意的是,微调目前不适用于较新的 GPT-3.5-turbo 型号或其他 GPT-4。
请阅读我们的 GPT-3 初学者指南,了解有关该模型的更多信息。
微调 GPT 的良好用例有哪些?
分类和条件生成是可以从 GPT-3 等语言模型的微调中受益的两类问题。 让我们简要探讨一下每一项。
Classification(分类)
对于分类问题,提示中的每个输入都被分配给预定义的类别之一,部分情况如下所示:
- 确保真实陈述:如果公司想要验证其网站上的广告是否提及了正确的产品和公司,可以对分类器进行微调以过滤掉不正确的广告,确保模型不会捏造事实。
- 情感分析:这涉及根据情感对文本进行分类,例如积极、消极或中立。
- 电子邮件分类分类:要将传入电子邮件分类到许多预定义类别之一,可以将这些类别转换为数字,这适用于最多 500 个类别。
Conditional generation(条件生成)
此类问题涉及根据给定输入生成内容。 应用程序包括释义、摘要、实体提取、产品描述编写、虚拟助手(聊天机器人)等。 示例包括:
- 根据维基百科文章创建引人入胜的广告。 在此生成用例中,请确保提供的样本是高质量的,因为微调模型将尝试模仿示例的风格(和错误)。
- 实体提取。 该任务类似于语言转换问题。 通过按字母顺序或按照原始文本中出现的顺序对提取的实体进行排序来提高性能。
- 客户支持聊天机器人。 聊天机器人通常包括有关对话的相关上下文(订单详细信息)、迄今为止的对话摘要以及最新消息。
- 基于技术特性的产品描述。 将输入数据转换为自然语言,以在此上下文中实现卓越的性能。
微调 GPT-3 的逐步实现
Dataset(数据集)
在此用例中,我们将针对问答场景微调 GPT-3 模型,其中包含结构化问答模式,旨在帮助模型理解模型需要执行的任务。 在整个训练和测试数据中,每对问题和答案都保持一致的格式。
问答数据集中的实例具有以下格式:
{
"prompt": "my prompt ->",
"completion": "the answer of the prompt. \n"
}
- “提示”是模型读取和处理的输入文本。 主要分隔符是箭头符号 (->),用于将提示与预期响应区分开来。
- “完成”是对提示的预期响应。 反斜杠“\n”符号用作停止序列来指示答案的结束。
了解数据集格式后,我们可以生成训练数据集和验证数据集,如下所示。 这些提示和补全是使用 ChatGPT 生成的。
我们的 ChatGPT 数据科学备忘单为用户提供了 60 多个数据科学任务提示。
training_data = [
{
"prompt": "What is the capital of France?->",
"completion": """ The capital of France is Paris.\n"""
},
{
"prompt": "What is the primary function of the heart?->",
"completion": """ The primary function of the heart is to pump blood throughout the body.\n"""
},
{
"prompt": "What is photosynthesis?->",
"completion": """ Photosynthesis is the process by which green plants and some other organisms convert sunlight into chemical energy stored in the form of glucose.\n"""
},
{
"prompt": "Who wrote the play 'Romeo and Juliet'?->",
"completion": """ William Shakespeare wrote the play 'Romeo and Juliet'.\n"""
},
{
"prompt": "Which element has the atomic number 1?->",
"completion": """ Hydrogen has the atomic number 1.\n"""
},
{
"prompt": "What is the largest planet in our solar system?->",
"completion": """ Jupiter is the largest planet in our solar system.\n"""
},
{
"prompt": "What is the freezing point of water in Celsius?->",
"completion": """ The freezing point of water in Celsius is 0 degrees.\n"""
},
{
"prompt": "What is the square root of 144?->",
"completion": """ The square root of 144 is 12.\n"""
},
{
"prompt": "Who is the author of 'To Kill a Mockingbird'?->",
"completion": """ The author of 'To Kill a Mockingbird' is Harper Lee.\n"""
},
{
"prompt": "What is the smallest unit of life?->",
"completion": """ The smallest unit of life is the cell.\n"""
}
]
validation_data = [
{
"prompt": "Which gas do plants use for photosynthesis?->",
"completion": """ Plants use carbon dioxide for photosynthesis.\n"""
},
{
"prompt": "What are the three primary colors of light?->",
"completion": """ The three primary colors of light are red, green, and blue.\n"""
},
{
"prompt": "Who discovered penicillin?->",
"completion": """ Sir Alexander Fleming discovered penicillin.\n"""
},
{
"prompt": "What is the chemical formula for water?->",
"completion": """ The chemical formula for water is H2O.\n"""
},
{
"prompt": "What is the largest country by land area?->",
"completion": """ Russia is the largest country by land area.\n"""
},
{
"prompt": "What is the speed of light in a vacuum?->",
"completion": """ The speed of light in a vacuum is approximately 299,792 kilometers per second.\n"""
},
{
"prompt": "What is the currency of Japan?->",
"completion": """ The currency of Japan is the Japanese Yen.\n"""
},
{
"prompt": "What is the smallest bone in the human body?->",
"completion": """ The stapes, located in the middle ear, is the smallest bone in the human body.\n"""
}
]
设置
在深入实施过程之前,我们需要准备工作环境,安装必要的库,特别是OpenAI Python库,如下所示:
pip install openai
现在我们可以导入库了。
import openai
准备数据集
如上所示,处理列表格式对于小型数据集可能很方便。 但是,以 JSONL(JSON Lines)格式保存数据有几个好处。 好处包括可扩展性、互操作性、简单性以及与 OpenAI API 的兼容性,后者在创建微调作业时需要 JSONL 格式的数据。
以下代码利用辅助函数prepare_data以JSONL格式创建训练和验证数据:
import json
training_file_name = "training_data.jsonl"
validation_file_name = "validation_data.jsonl"
def prepare_data(dictionary_data, final_file_name):
with open(final_file_name, 'w') as outfile:
for entry in dictionary_data:
json.dump(entry, outfile)
outfile.write('\n')
prepare_data(training_data, "training_data.jsonl")
prepare_data(validation_data, "validation_data.jsonl")
在笔记本中,可以使用以下针对训练和验证数据的语句来完成数据集的准备。
!openai tools fine_tunes.prepare_data -f "training_data.jsonl"
!openai tools fine_tunes.prepare_data -f "validation_data.jsonl"
最后,我们将两个数据集上传到OpenAI开发者账户,如下:
training_file_id = upload_data_to_OpenAI(training_file_name)
validation_file_id = upload_data_to_OpenAI(validation_file_name)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")
成功执行前面的代码会在训练和验证数据的唯一标识符下方显示。

在这个级别上,我们拥有进行微调的所有信息。
创建微调作业
这个微调过程的灵感来自于在 Microsoft Azure 上执行微调的 openai-cookbook。
为了执行微调,我们将使用以下两个步骤:(1)定义超参数,(2)触发微调。
我们将使用训练和验证数据集对 davinci 模型进行微调,并使用批量大小 3 和学习率乘数 0.3 运行 15 个时期。
create_args = {
"training_file": training_file_id,
"validation_file": validation_file_id,
"model": "davinci",
"n_epochs": 15,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
response = openai.FineTune.create(**create_args)
job_id = response["id"]
status = response["status"]
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")
上面的代码生成 jobID (ft-CfuVdcqEYfPcbLPbbnVnd2kh)、训练响应和训练状态(pending)的以下信息。

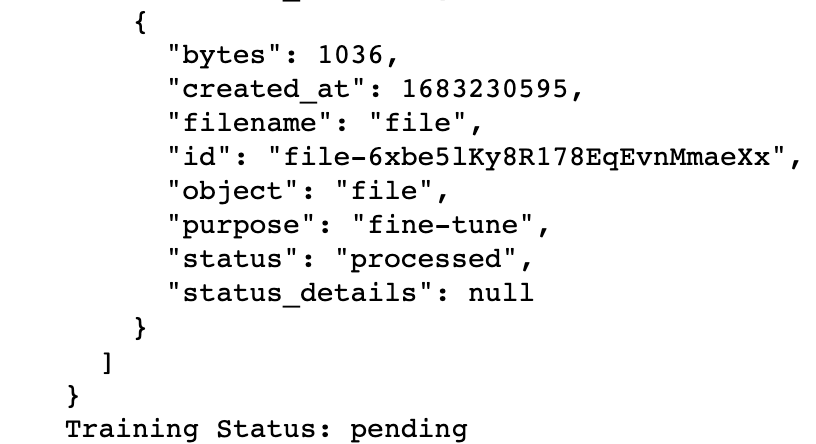
此待定状态不提供任何相关信息。 但是,我们可以通过运行以下代码来更深入地了解训练过程:
import signal
import datetime
def signal_handler(sig, frame):
status = openai.FineTune.retrieve(job_id).status
print(f"Stream interrupted. Job is still {status}.")
return
print(f'Streaming events for the fine-tuning job: {job_id}')
signal.signal(signal.SIGINT, signal_handler)
events = openai.FineTune.stream_events(job_id)
try:
for event in events:
print(f'{datetime.datetime.fromtimestamp(event["created_at"])} {event["message"]}')
except Exception:
print("Stream interrupted (client disconnected).")
下面生成了所有的训练次数,以及微调的状态,微调已成功。
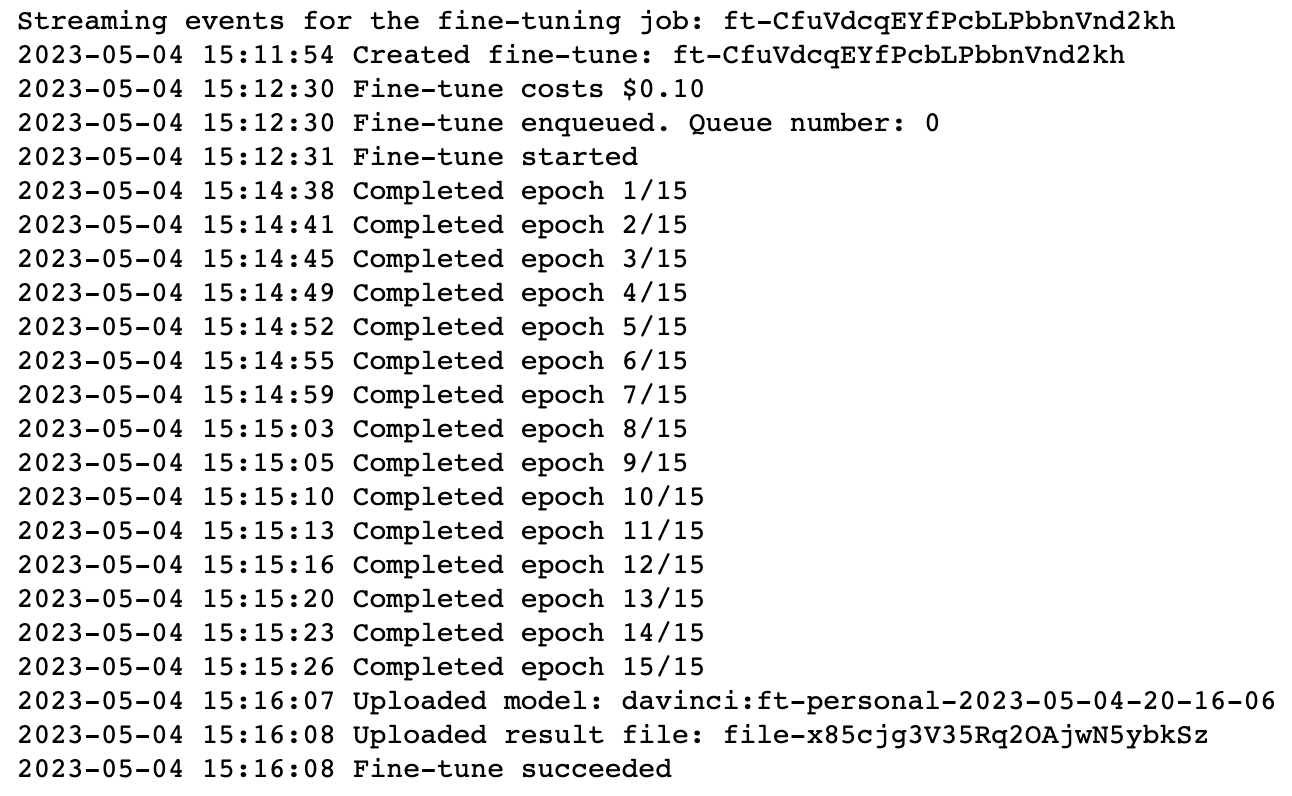
检查微调任务状态
让我们验证我们的操作是否成功,此外,我们可以使用列表操作来检查所有微调操作。
import time
status = openai.FineTune.retrieve(id=job_id)["status"]
if status not in ["succeeded", "failed"]:
print(f'Job not in terminal status: {status}. Waiting.')
while status not in ["succeeded", "failed"]:
time.sleep(2)
status = openai.FineTune.retrieve(id=job_id)["status"]
print(f'Status: {status}')
else:
print(f'Finetune job {job_id} finished with status: {status}')
print('Checking other finetune jobs in the subscription.')
result = openai.FineTune.list()
print(f'Found {len(result.data)} finetune jobs.')
执行结果如下:
Null
总共有 27 个 Finetune 作业。
模型验证
最后,可以从“fine_tuned_model”属性中检索微调模型。 以下打印语句显示最终模式的名称为:curie:ft-personal-2023-05-04-15-54-08
# Retrieve the finetuned model
fine_tuned_model = result.fine_tuned_model
print(fine_tuned_model)
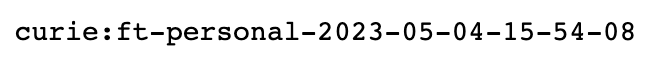
有了这个模型,我们可以通过提供提示、模型名称并使用 openai.Completion.create() 函数创建查询来运行查询来验证其结果。 从答案字典中检索结果如下:
new_prompt = "Which part is the smallest bone in the entire human body?"
answer = openai.Completion.create(
model=fine_tuned_model,
prompt=new_prompt
)
print(answer['choices'][0]['text'])
new_prompt = """ Which type of gas is utilized by plants during the process of photosynthesis?"""
answer = openai.Completion.create(
model=fine_tuned_model,
prompt=new_prompt
)
print(answer['choices'][0]['text'])
尽管提示的写法与验证数据集中的不完全相同,但模型仍然设法将它们映射到正确的答案。 对先前请求的答复如下所示。

通过很少的训练样本,我们成功地建立了一个不错的微调模型。 更大的训练规模可以获得更好的结果。
结论
在本文中,我们探索了 GPT-3 的潜力,并讨论了微调模型以提高其针对特定用例的性能的过程。 我们概述了成功微调 GPT-3 的先决条件,包括对 Python 编程的基本了解以及对机器学习和自然语言处理的熟悉。
此外,我们还引入了 openai Python 包,用于简化通过 OpenAI 的 API 访问 GPT-3 功能的过程。 本文涵盖了使用 Python 和自定义数据集微调 GPT-3 模型所涉及的所有步骤,从获取 API 凭证到准备数据、训练模型和验证模型。
通过强调微调的好处并提供流程的全面指南,本文旨在帮助数据科学家、开发人员和其他利益相关者获得必要的工具和知识,以创建适合其具体情况的更准确、更高效的 GPT-3 模型 需要和要求。
我们有一篇文章介绍了什么是 GPT-4 以及它为何重要? 还有transformer使用简介和hugging face教程。 请务必阅读它们,以将您的知识提升到一个新的水平。















 2690
2690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









