






英文原文:https://stable-diffusion-art.com/lcm-lora/
LCM-LoRA 可以加速任何 Stable Diffusion 模型。它可以与 Stable Diffusion XL 模型结合使用,只需 4 个步骤即可生成 1024×1024 图像。
在本文中,您将学习/获得:
- LCM LoRA 是什么。
- LCM LoRA 如何工作?
- 在 AUTOMATIC1111 中使用 LCM-LoRA
- 可下载的 ComfyUI LCM-LoRA 工作流程,用于快速生成 SDXL 图像 (txt2img)
- 可下载的 ComfyUI LCM-LoRA 工作流程,用于快速生成视频 (AnimateDiff)

文章目录
什么是LCM-LoRA?
要回答这个问题,我们得从相关的 Consistency Model 一致性模型(CM)说起。 CM 是一类新型扩散模型,经过训练可一步生成图像。它是 Yang Song 等人在一致性模型一文中提出的。
潜在一致性模型 (LCM) 在潜在扩散模型中应用了相同的思想,例如Stable Diffusion,其中图像去噪发生在潜在空间中。
通常,您需要为每个自定义检查点模型训练一个新的LCM,使用起来很不方便。 LCM-LoRA 是使用一致性方法通过稳定扩散基础模型(v1.5 和 SDXL)训练的 LoRA 模型。它可以与任何自定义检查点模型一起使用,将图像生成速度加快到仅需四个步骤。
LCM-LoRA 如何工作?
要了解 LCM-LoRA 的工作原理,您首先需要了解一致性模型以及加速扩散模型的相关工作。
一致性模型
一致性模型是一种经过训练可一步生成 AI 图像的扩散模型。它是用教师模型训练的更高效的学生模型,例如 SDXL 模型。学生模型经过训练可以生成与教师模型相同的图像,但只需一步即可完成。换句话说,一致性模型是教师模型的更快版本。
您还可以直接从头开始训练一致性模型,而不使用教师模型。将来,您可能会看到没有标准对应产品的新 LCM 模型。
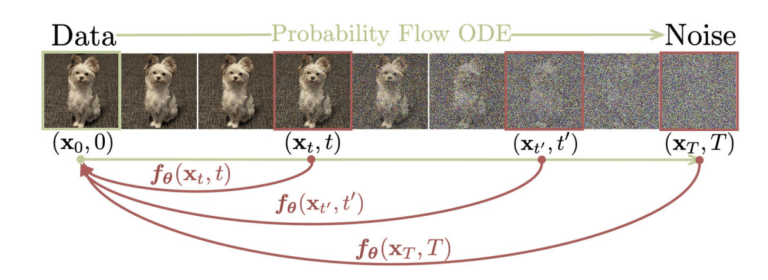
训练一致性模型以在任何给定的采样步骤中一步生成最终图像。 (图来自一致性模型文章。)
一致性模型背后的想法是找到最终人工智能图像与任何去噪步骤之间的映射。例如,如果训练扩散模型以 50 个步骤生成 AI 图像,则一致性模型会将步骤 0、1、2、3… 的中间噪声图像映射到最终步骤 50。
它被称为一致性模型,因为训练利用了映射输出的一致性:它总是在一个步骤中映射到最终图像。换句话说,无论图像的噪声有多大,映射函数的输出总是相同的。
实际上,单步生成的图像质量并不好。所以人们通常会做几个步骤。
一致性模型是一种蒸馏方法:它从现有(教师)模型中提取并重新排列信息,以使其更加高效。
一致性模型比渐进式蒸馏方法更好,渐进式蒸馏方法有望显着加速稳定扩散。他们产生更高质量的图像。
潜在一致性模型(LCM)
潜在一致性模型(LCM)是具有潜在扩散的一致性模型,例如稳定扩散。 Simian Luo 及其同事在《潜在一致性模型:通过少量步数推理合成高分辨率图像》一文中对此进行了研究。原始一致性模型位于像素空间,LCM 位于潜在空间。这是唯一的区别。
LCM-LoRA
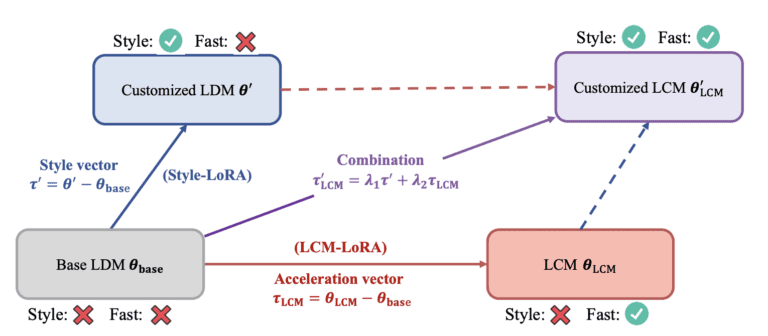
LCM-LoRA 可以加速任何稳定扩散检查点模型。 (图来自 LCM-LoRA 论文。)
现在,我们终于可以介绍LCM-LoRA了!您无需训练检查点模型,而是为 LCM 训练 LoRA。 LoRA 是一个小型模型文件,旨在修改检查点模型。就像一个小补丁。
使用LoRA的好处是:
- 可移植性:LCM-LoRA 可应用于任何稳定扩散检查点模型。用于稳定扩散的 LCM-LoRA v1.5 和 SDXL 型号现已上市。本质上,应用 LoRA 时可以加快模型速度。
- 训练速度更快:LoRA 需要训练的权重更少。因此,训练速度更快、要求更低。
LCM-LoRA的采样方法
LCM 模型经过训练可以进行 1 步推理。换句话说,该模型将尝试一步生成最终的 AI 图像。但质量却没有我们希望的那么好。
LCM的采样方法如下:
- 对潜在空间进行去噪。
- 添加回一些噪音(根据噪音表)
- 重复步骤 1 和 2,直到到达最后一个采样步骤。
LCM-LoRA 下载页面
以下是 LCM-LoRA 权重的 Huggingface 链接。
在 AUTOMATIC1111 中使用 LCM-LoRA
AUTOMATIC1111 尚未正式支持 LCM-LoRA。但您可以以有限的方式使用 LCM-LoRA 加速。
Stable Diffusion v1.5 模型
首先,下载用于 SD 1.5 的 LCM-LoRA 并将其放入 LoRA 文件夹 stable-diffusion-webui > models > Lora。将其重命名为 lcm_lora_sd15.safetensors。
选择 Stable Diffuions v1.5 模型,例如DreamShaper 模型。
在提示词中使用 LoRA 指令:
a very cool car <lora:lcm_lora_sd15:1>
采样器:Euler
您需要使用较低的 CFG 比例:1 – 2
采样步数:4

为了进行比较,下面这些图像没有使用 LCM-LoRA,使用了 4 个步骤。

Stable Diffusion XL
截至 2023 年 11 月 24 日,AUTOMATIC1111 中缺乏对 LCM-LoRA 的原生支持。可以使用上面的方法,但是效果不如v1.5模型。
添加带有 AnimateDiff 扩展的 LCM 采样器
SDXL 模型效果不佳,因为我们应该使用 LCM 采样方法。在添加 LCM 采样器之前,您可以安装 AnimateDiff 扩展。如果您已经拥有,请更新它。它将 LCM 采样器添加到可用采样方法列表中。
下载适用于 SDXL 的 LCM LoRA。将其放入 stable-diffusion-webui > models> Lora 中。将其重命名为 lcm_lora_sdxl.safetensors。
要使用 LCM 采样器生成 SDXL 图像:
- Checkpoint model: sd_xl_base_1.0
- Prompt:
a very cool car <lora:lcm_lora_sdxl:1>
- Sampling method: LCM
- Size: 1024 x 1024
- CFG Scale: 1 to 2
- Sampling steps: 4

ComfyUI LCM-LoRA SDXL 文本到图像工作流程
我们将使用 ComfyUI,一个基于节点的稳定扩散 GUI。如果您还没有使用过 ComfyUI,请参阅它的安装和初学者指南。
查看 Think Diffusion 以获得完全托管的 ComfyUI 在线服务。他们为我们的读者提供 20% 的额外学分。 (如果您注册,还可以支付一小笔佣金来支持该网站)
第 1 步:加载工作流程
下载 ComfyUI 工作流程 JSON 文件,然后将其拖放到 ComfyUI 以加载工作流程。
第 2 步:加载 SDXL 模型
在“加载检查点”节点中,从下拉菜单中选择 SDXL 模型。它可以是 SDXL 基础或任何定制 SDXL 模型。

第 3 步:下载并加载 LoRA
在此处下载适用于 SDXL 型号的 LCM-LoRA。
将文件重命名为 lcm_lora_sdxl.safetensors。将其放入文件夹 ComfyUI > models > loras 中。 (如果您的ComfyUI与A1111共享模型文件,请将其放在A1111的LoRA文件夹中)
刷新 ComfyUI 页面。
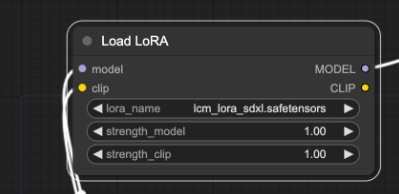
在 Load LoRA 节点中选择LCM-LoRA。
第四步:生成图像
查看提示、反向提示和图像大小。按 Queue Prompt 生成图像。它应该很快就会出现,因为此工作流程仅使用 5 个采样步骤!
评论
您可以对 Stable Diffusion v1.5 自定义模型使用相同的工作流程。您需要使用 v1.5 模型和 v1.5 LCM-LoRA。不要忘记将图像尺寸更改为 768 x 512 像素!
ComfyUI LCM-LoRA animateDiff 提示出行工作流程
哪些 comfyUI 工作流程可以加快速度?当然是拍视频啦!现在就开始吧:由 LCM-LoRA 加速的 ComfyUI AnimateDiff 提示旅行工作流程!
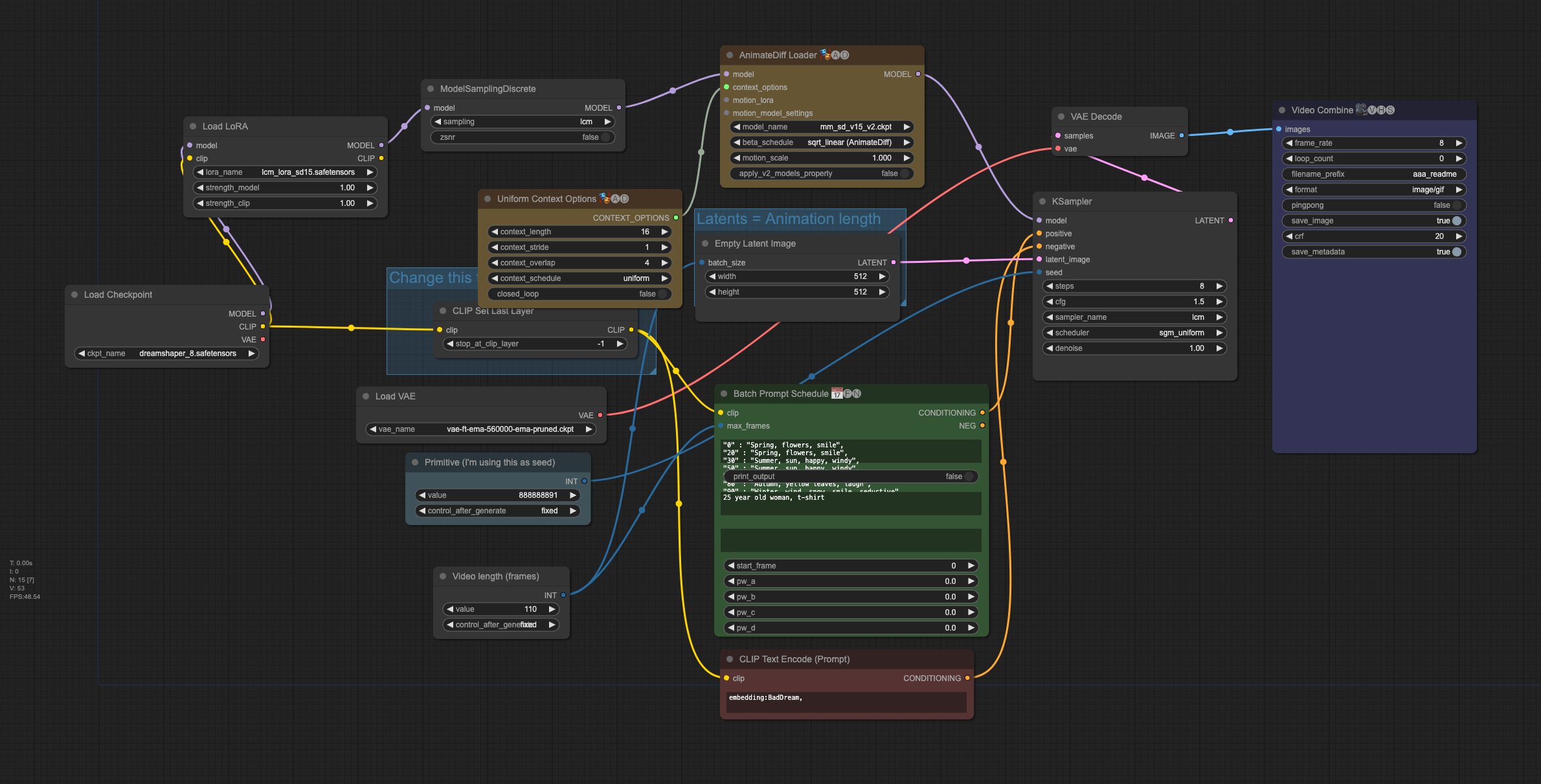
第 1 步:加载工作流程
下载工作流程图像文件。将工作流程图像文件拖放到 ComfyUI 中进行加载。
您可能需要更新 ComfyUI、安装缺少的自定义节点并更新所有自定义节点。
第2步:选择检查点模型
下载检查点模型 DreamShaper 8。将 safetensors 文件放入文件夹ComfyUI > models > checkpoints.
刷新浏览器选项卡。
找到节点“Load Checkpoint”。点击 ckpt_name 下拉菜单并选择 dreamshaper_8 模型。
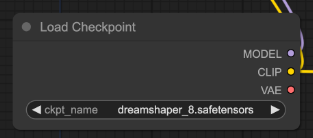
第 3 步:选择 VAE
下载 ema-560000 VAE。将文件放入文件夹 ComfyUI > models > vae 中。
刷新浏览器页面。
在“Load VAE”节点中,选择您刚刚下载的文件。
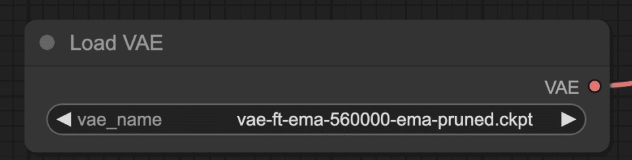
步骤 4:选择 LCM-LoRA
下载 SD v1.5 LCM-LoRA。将其重命名为 lcm_lora_sd15.safetensors。
将其放在 ComfyUI > models > loras 中。
刷新 ComfyUI。
在 Load LoRA 节点中选择 lcm_lora_sd15.safetensors。
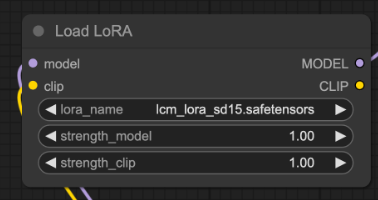
第5步:选择AnimateDiff运动模块
下载 AnimateDiff v1.5 v2 运动模型。将其放入文件夹 ComfyUI > custom_nodes > ComfyUI-AnimateDiff-Evolved > models。
刷新浏览器页面。
在 AnimateDiff Loader 节点中,在 model_name 下拉菜单中选择 mm_sd_v15_v2.ckpt。
第 6 步:下载负嵌入
此工作流程在否定提示中使用 BadDream 否定嵌入。它是为 Dream Shaper 模型训练的负嵌入。
下载 BadDream 嵌入。将文件放入 ComfyUI > 模型 > 嵌入中。
第7步:生成视频
点击“Queue Prompt”开始生成视频。
进度条将出现在 KSampler 节点上。完成后,您将看到视频出现在“Video Combine”节点中。
这是你应该得到的:
















 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}