







1、从贝叶斯到朴素贝叶斯
贝叶斯公式如下:

通过先验概率求后验概率
P(A)被称为先验概率,是已经给出的或者通过现有数据统计可以求出的,对A出现概率的一个大胆估计。P(B|A)/P(B)可以理解为一个实验,即满足某种现实状况,是对这个贝叶斯估计的一个修正因子。P(A|B)被称为后验概率,即满足某种事实条件的概率。
对应到机器学习中,B即为特征X,A为需要判断的目标类别Y,将其展开就是如下公式:
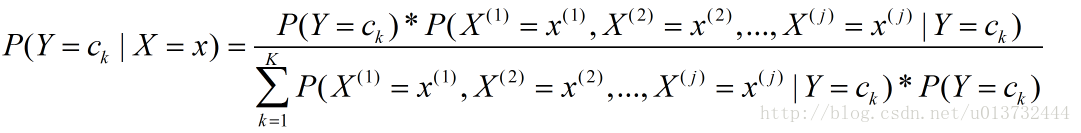
右侧的第一项先验概率


因为现实生活中的数据,无法保证特征之间是完成独立的,因此,朴素贝叶斯会丢失部分信息,即特征间的相关性,朴素贝叶斯是一个低方差的模型。对于高维数据,因为条件独立假设会丢失大量信息,导致准确率欠缺,因此朴素贝叶斯不适合应用于高维数据集。但在小量数据集上,朴素贝叶斯通常表现出的性能不错。
朴素贝叶斯算法通过求在给定特征条件下分类的后验概率最大的类作为预测的结果,如下所示:

又因为分母位置对于所有的y取值相同,所以为了方便运算,可以省略简化如下。

在实际应用中,乘法的运算比较消耗计算资源,同时小数连乘,容易发生下溢出,一般会采取取负对数:

在训练数据时保存先验概率和条件概率的负对数,在预测时通过求累加和求解,这样计算速度更快。
2、模型 的训练
通过上述的模型可以看出,模型的训练需要求出两类概率,一类为分类的先验概率,一类为特征的条件概率。
先验概率的通过极大似然估计求得,如下:

条件概率的公式如下:

这种方法存在一个问题,因为数据集只是一个样本,所以无法保证每一个特征的每一个取值都会出现,这时就会出现概率为0的情况,影响后验概率的计算。为了解决这个问题,采用贝叶斯估计,即给每一个特征的每一个取值出现次数预设一个比较小的数,避免概率为0。公式如下所示:

当λ=1,这时称为拉普拉斯光滑,也可以对先验概率进行同样的处理。
3、代码实现:
朴素贝叶斯类:DiscreteBayes.py
#_*_encoding:utf-8_*_
import numpy as np
class NaiveBayes():
#初始化 平滑系数、特征取值
def __init__(self,lap=1,features=None):
self.features=features
self.lap=lap
def fit(self,x,y):
self.x=x
self.y=y
self.calculate_priori_probability() #计算先验概率
datasets={}
for one_sample,c in zip(x,y): #对数据集按照类别进行划分
if c not in datasets.keys():
datasets[c]=[]
datasets[c].append(one_sample)
columns,rows=x.shape
if self.features==None: #如果没有给出特征取值,则统计特征的取值
self.features={}
for row in np.arange(rows):
self.features[row]=set(x[:,row])
for c,sub_samples in datasets.items(): #计算每个类别下的各维特征不同取值的似然概率
self.parameters[c]['likelihood']=self.calculate_likelihood(sub_samples)
def calculate_priori_probability(self):
self.parameters={}
length=len(self.y)
for c in self.y: #统计每一类的频数
if c not in self.parameters.keys():
self.parameters[c]={}
self.parameters[c]['priori']=self.parameters[c].get('priori',0)+1
for k,v in self.parameters.items(): #将频数转换为频率
v['priori']=np.log(v['priori']/length)
def calculate_likelihood(self,sub):
columns,rows=np.shape(sub)
parameter_likelihood={}
for row in np.arange(rows):
parameter_likelihood[row]={}
for feat_value in np.array(sub)[:,row]:
parameter_likelihood[row][feat_value]=parameter_likelihood[row].get(feat_value,0)+1
for feat_value in self.features[row]:
parameter_likelihood[row][feat_value]= \
np.log(parameter_likelihood[row].get(feat_value,self.lap)/(columns+self.lap*len(self.features[row])))
return parameter_likelihood
def classify(self,sample):
max_posteriors=-np.inf
result=None
for c,parameters in self.parameters.items():
posterior=parameters['priori']
for row,feat_value in enumerate(sample):
posterior+=parameters['likelihood'][row][feat_value]
if max_posteriors<posterior:
max_posteriors=posterior
result=c
return result
def predict(self,x):
y_pred=[]
for one_sample in x:
y_pred.append(self.classify(one_sample))
return y_pred
def accuracy(self,x,y):
y_pred=self.predict(x)
return np.sum(y==y_pred)/len(y)测试类文件:Test.py
from DiscreteBayes import NaiveBayes
import numpy as np
def loadDataSet(fileName):
file = open(fileName)
trainX = []
trainY = []
for line in file.readlines():
currLine = line.strip().split('\t')
feats = []
for feat in currLine[:-1]:
feats.append(feat)
trainX.append(feats)
trainY.append(currLine[-1])
return trainX, trainY
def img2vector(filename):
returnVect = np.zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
def loadDigits(dirName):
from os import listdir
hwLabels = []
trainingFileList = listdir(dirName)
m = len(trainingFileList)
trainingMat = np.zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumber = int(fileStr.split('_')[0])
hwLabels.append(classNumber)
trainingMat[i, :] = img2vector("%s/%s" % (dirName, fileNameStr))
return trainingMat, hwLabels
if __name__=='__main__':
trainX, trainY = loadDigits('trainingDigits')
testX, testY = loadDigits('testDigits')
x,y=np.array(trainX),np.array(trainY)
x_test,y_test=np.array(testX),np.array(testY)
features={}
for row in np.arange(np.shape(x)[0]):
features[row]=[0.0,1.0]
bayes=NaiveBayes(features=features)
bayes.fit(x,y)
print("朴素贝叶斯模型参数:{}".format(bayes.parameters))
print("朴素贝叶斯各维特征的取值:{}".format(bayes.features))
print("测试集合数据的准确率:",bayes.accuracy(x_test,y_test))
还不错,准确率为:0.933403805497
测试数据集的下载链接为:http://download.csdn.net/detail/u013732444/9830443
4、总结
朴素贝叶斯算法原理简单,计算速度也快,在小规模数据集上表现效果很好,适合多分类问题。缺点:要求标称型数据,需要对数据进行预处理。














 294
294











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









