







k近邻算法是机器学习中最简单的一种算法,简单粗暴,给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,把这K个实例中出现最多的类作为输入实例的类。对于初学者可能会好奇,这个近邻是什么意思?例如调查一群人的信息,会对研究目标调查多个特征,记录人的头发长度、身高、年龄、体重、肤色,性别,对这些特征采用数值进行刻画。假设现在我们需要通过头发长度、身高、年龄、体重和肤色这些数据来判断一个人的性别,我们会计算这个人的数据与其他(她)人的数据的差值,对差值取绝对值求和,找出差别最小的k个人,而把这k个人中性别多数作为这个人的性别判断结果。
k近邻算法
输入:训练数据集
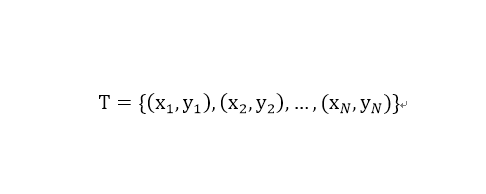
其中,xi属于特征向量,yi为实例的类别,i=1,2,...,N
输出:实例x所属的类y
(1)根据给定的距离度量,在训练集T中找出与x最近的k个点,涵盖这个k个点的x的领域记做Nk(x).
(2)根据分类决策规则决定x的类别y,通常采用多数表决策略:
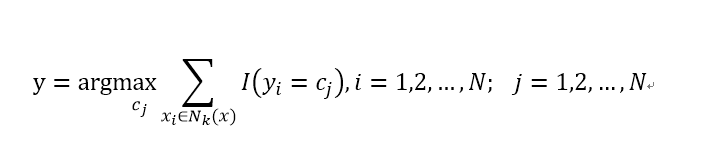
上式中I为指示函数,当yi=cj是I为1,否则为零。
从上面的算法可以看出,K近邻算法并不像其它的机器学习算法那样通过训练数据得到一个模型,通过这个学习到的模型来对数据进行预测。而是需要对每个预测数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5973
5973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









