









 本文介绍了基于Python和MYSQL的电影市场预测分析系统,涉及技术栈选择、系统功能如登录、后台管理、数据分析等功能的详细设计与实现。还提供了2022-2024年计算机软件毕业设计选题推荐和项目实战资源。
本文介绍了基于Python和MYSQL的电影市场预测分析系统,涉及技术栈选择、系统功能如登录、后台管理、数据分析等功能的详细设计与实现。还提供了2022-2024年计算机软件毕业设计选题推荐和项目实战资源。
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
1 简介
本文主要还是以基于python的电影市场预测分析的设计与实现为主要的考虑内容,我们通过python的技术将目前电影市场上的各种信息进行相关的预测,换句话说我们的数据来源完完全全都是真实的数据。那么在数据库方面还是采用了MYSQL的数据库,这样即节约了成本又能快速上手。

关键词: MYSQL数据库 预测分析 python技术
2 技术栈
环境要求
Python 3.8 (最好用 3.8)
pycharm (社区版,专业版本都可以)
MySql (建议 5.7, 8.0 也可以)
Navicat (不限制版本)
3 系统业务功能划分
根据功能需求的划分首先把要管理员、用户等不同的角色进行划分,商家有商家的权限,用户有用户自己的权限,针对不同的权限而开放相应不同的功能,这一点来说才是非常重要的。在系统的建设期还要把功能等其它问题进行细化,保证每一项目需求都有相关的功能点进行一一对应。当然在系统的执行过程当中会存在输入信息的过程,那么就会存在输入信息的流程图如下:
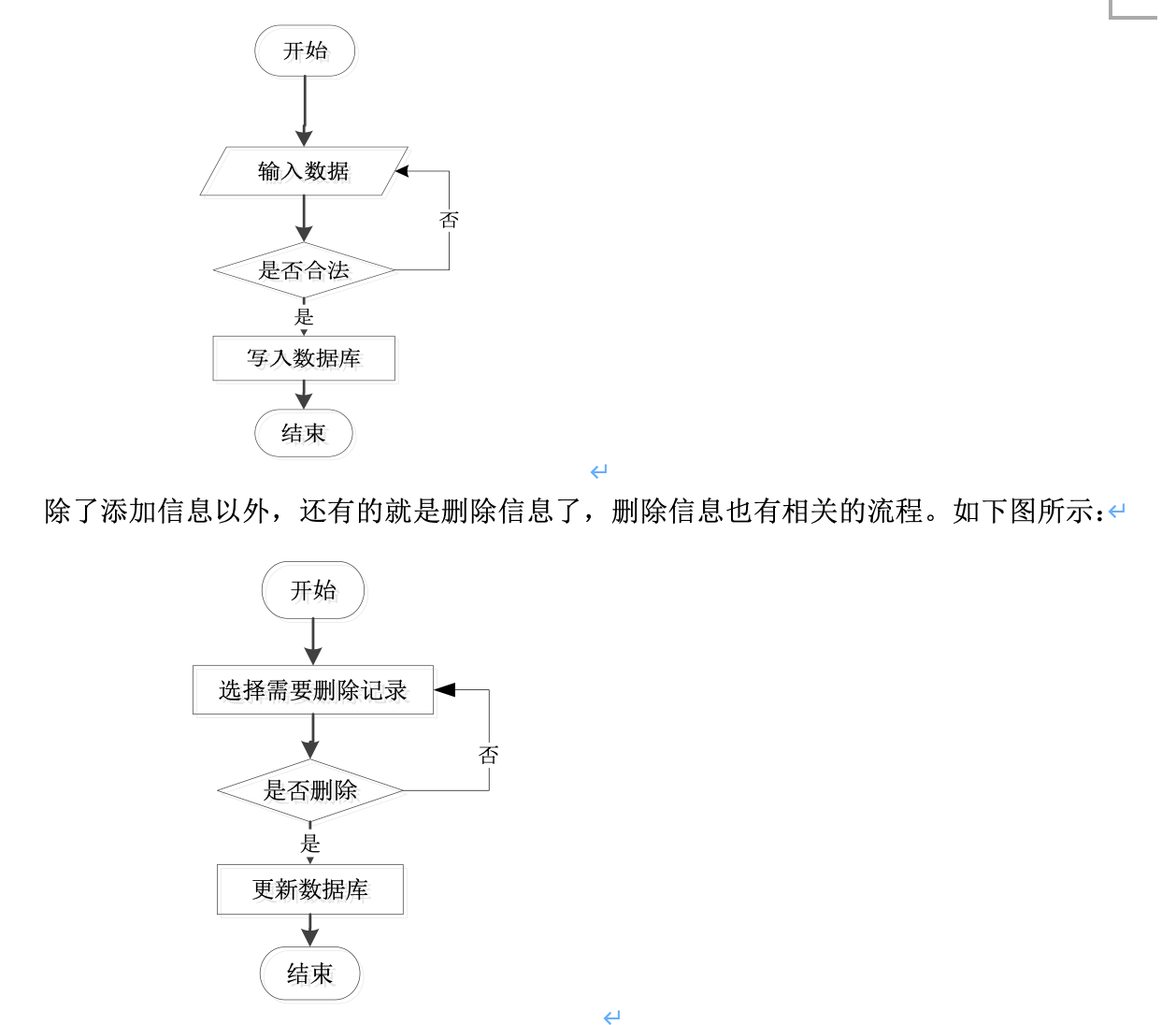
4 系统总体设计
基于python的大数据的电影市场预测分析当中整体的功能模块设计如下:
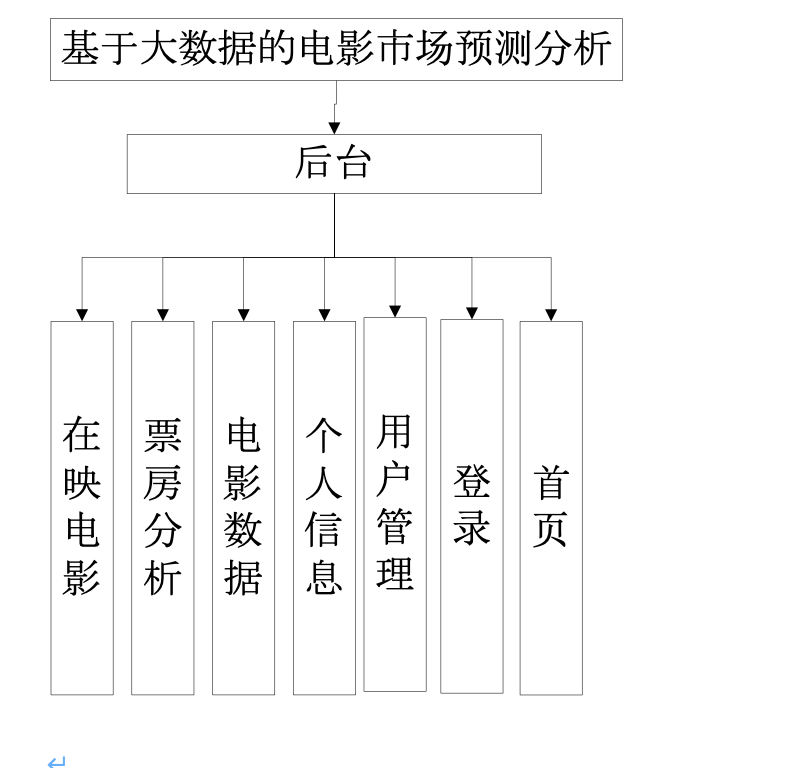
5 系统实现
登录页面
不论是何系统,最重要的功能就是能够进行用户的有效性验证和登录。为了能够提供更好的后台管理功能,在后台管理入口处也进行了相关的管理员登录,通过账号、密码以及不同的管理权限来进行登录,风格上还是按照简洁的风格进行设计调整,这样一来我们就可以和应用相对保持统一。在UI风格上也是从一个应用中分离出来的登录页面。如下所示:

后台首面
管理员在登录之后就会进入到系统的正常页面当中,说实话后台管理页面的风格,每种应用都有自己不同的风格,而大多数的风格也都是按照菜单功能树、操作区域等这种布局进行区分的。在菜单功能树当中有后台管理应用的全部功能,而且这些菜单树的入口也仅仅只是改变右边操作区域的内容,这样一来多个模块可以使用同一个菜单树,既保证了风格统一的美观程度,又能让开发在代码工作量上减少很多。在操作区域还是以上、中、下之样的方式来进行的,每块区域都有它自己的位置功能。如下所示:

在映电影界面
通过在映电影功能,我们可以看到在映电影目前的影片详情以及影片场次和影片人次,以及影片的上座率。通过不同角度的分析,将每个电影的各个层次进行角度分析,也可以说是鼠标属性和指标的一个罗列。同时为了能够区分这些形式,我们把传统的表格形式变成了图表的形式,这样更加清楚。如下所示:

票房分析展示
票房分析也可以说是一个非常重要的功能。在票房分析的过程当中,能把各个层次的数据都整理出来,比如说我们常见的需求票房、泡布施之类,以及不同电影的。票房到底是金额是多少和首日的票房,这些都是从不同的维度进行统计,那么就在于Python技术将这些一一进行分裂。将数据查询之后,进行一个过滤筛选,最终得到我们想要的数据。如下图所示:

个人信息
个人信息来说相对比较简单一些,就是通过一个大的列表形式,把个人的信息一一进行罗列,能够让。用户清楚地将个人信息看出来,这一点也是非常重要的。如下图所示:

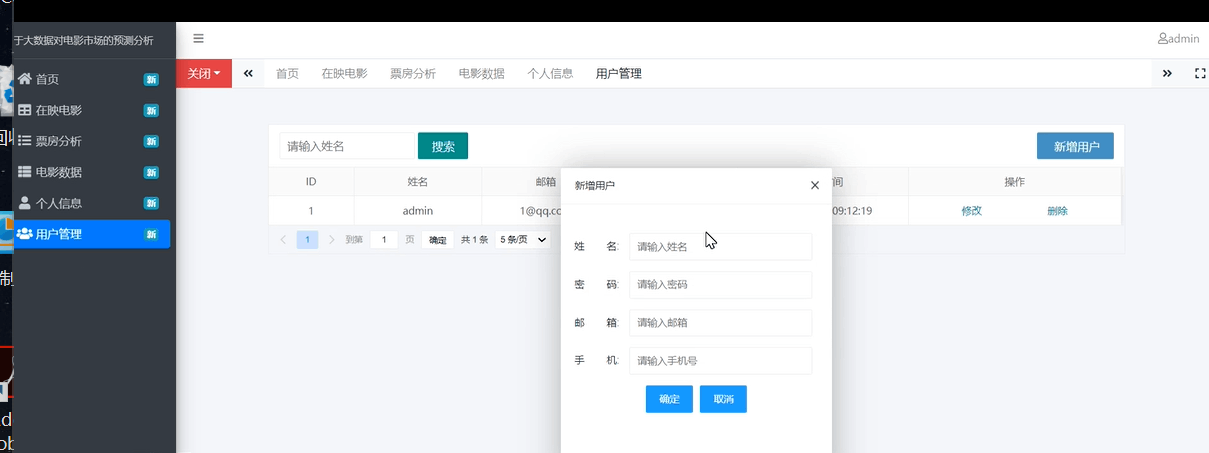
用户管理界面
用户管理就是能够将系统当中所有注册用户进行一个管理,这样的管理方式可以防止用户在丢失密码之后联系管理员可以进行密码的修改。另一方面,可以对整个系统的用户进行一个有效的把控。如下图所示:
参考文献
[1]
李斌,王嘉锐,韦达欣.基于B/S模式的网络资料管理信息管理系统设计[J].电脑知识与技术,2019,
(35): 81,91.
[2] 王玺,辛枫冬.最新企业绩效实务
网络资料管理信息工作者的得力助手[M].中国纺织出版社,2020.
[3] 魏勇编著. Python开发技术.人民邮电出版社, 2019.
[4] 沈应逵,曾凌编著. JAVA WEB数据库系统应用开发与实例.人民邮电出版社,
2020.
[5] 李尊朝,苏军,饶元编著.
Python语言程序设计例题解析与实验指导.中国铁道出版社, 2019.
[6] 梁建全等编著. 精通轻量级Java EE框架整合方案.
北京市:人民邮电出版社, 2008.
[7] 秦京渝编著. 企业级Python开发与架构
专业程序员在实战中的蜕变.电子工业出版社, 2019.
6 推荐阅读
基于 SpringBoot+Vue的电影影城管理系统,附源码,数据库
7 源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
















 80
80











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











