









1. Thread
1.1 创建线程的方法
// 1. 任务和线程
Runnable r = new Runnable(){
@Override
public void run() {
// ...
}
};
Thread thread = new Thread(r);
// 2. 任务和线程统一
Thread thread = new Thread(() -> {
// ...
}, "t1");
// 3. 返回值
FutureTask<Integer> futureTask = new FutureTask<>(() -> 100); // FutureTask需要一个Callable接口
Thread thread = new Thread(futureTask);
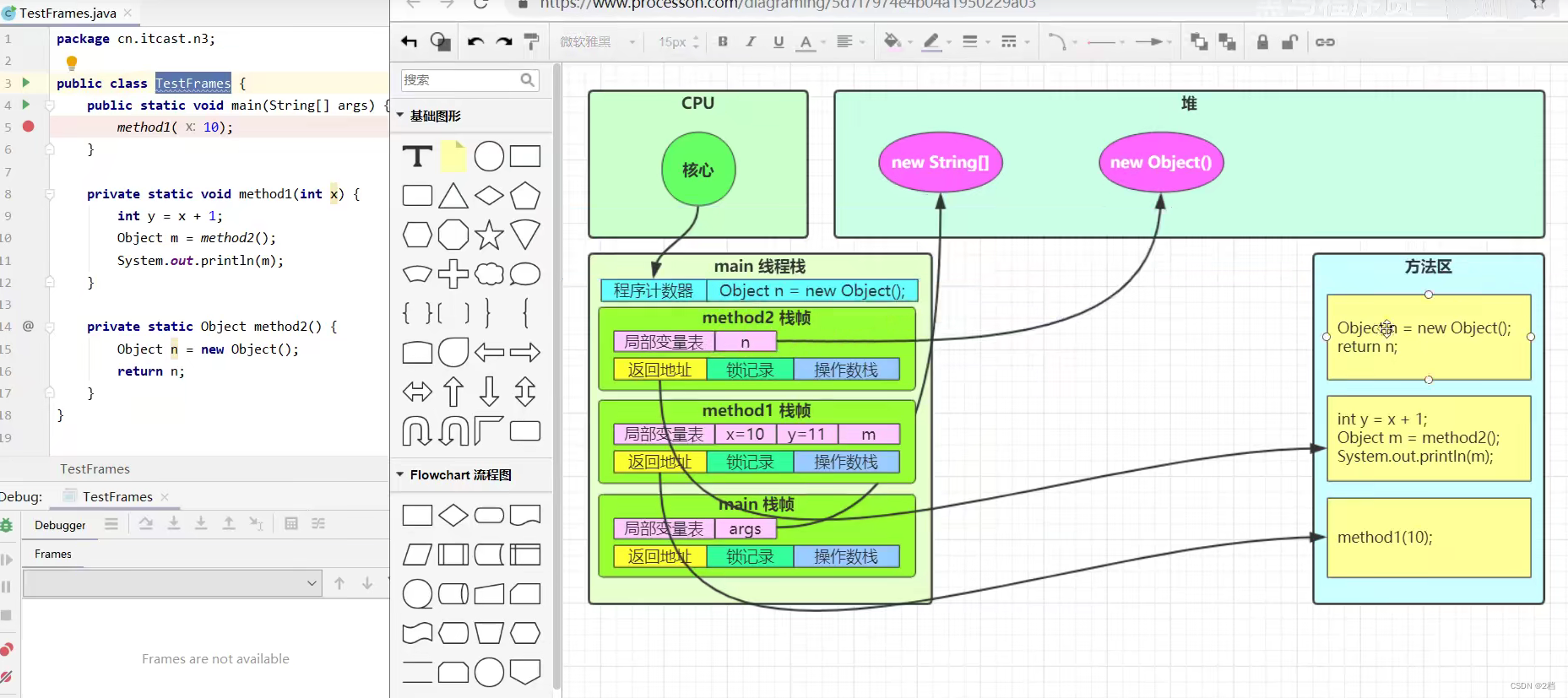
1.2 线程运行原理
虚拟机中将运行时数据区分为五个部分,其中虚拟机栈是线程独享的,每当一个线程被创建以后,虚拟机就会为线程分配栈内存
-
每个栈由多个栈帧组成,对应每次方法调用占用的内存
-
每个线程只有一个活动栈帧,对应当前正在执行的方法
1.3 常用方法
1.3.1 sleep与yield(让出时间片)
sleep (使线程阻塞)
-
调用 sleep 会让当前线程从 Running 进入 Timed Waiting 状态(阻塞),可通过state()方法查看
-
其它线程可以使用 interrupt 方法打断正在睡眠的线程,这时 sleep 方法会抛出 InterruptedException
-
睡眠结束后的线程未必会立刻得到执行
-
建议用 TimeUnit 的 sleep 代替 Thread 的 sleep 来获得更好的可读性
yield (让出当前线程)
-
调用 yield 会让当前线程从 Running 进入 Runnable 就绪状态(仍然有可能被执行),然后调度执行其它线程
-
具体的实现依赖于操作系统的任务调度器
1.3.2 join
用于等待某个线程结束。哪个线程内调用join()方法,就等待哪个线程结束,然后再去执行其他线程。 如在主线程中调用ti.join(),则是主线程等待t1线程结束,join 采用同步。
Thread t1 = new Thread(); //等待 t1 线程执行结束 t1.join(); // 最多等待 1000ms,如果 1000ms 内线程执行完毕,则会直接执行下面的语句,不会等够 1000ms t1.join(1000);
1.3.3 interrupt
interrupt 打断线程有两种情况,如下:
-
如果一个线程在在运行中被打断,打断标记会被置为 true ,但是并不会影响线程运行状态。
-
如果是打断因sleep、wait、join方法而被阻塞的线程,会将打断标记置为 false,并且会抛出InterruptedException。
isInterrupted() 与 interrupted() 比较,如下: 首先,isInterrupted 是实例方法,interrupted 是静态方法,它们的用处都是查看当前打断的状态,但是 isInterrupted 方法查看线程的时候,不会将打断标记清空,也就是置为 false,interrupted 查看线程打断状态后,会将打断标志置为 false,也就是清空打断标记,简单来说,interrupt() 方法类似于 setter 设置中断值,isInterrupted() 类似于 getter 获取中断值,interrupted() 类似于 getter + setter 先获取中断值,然后清除标志。 用代码测试如下:
/**
* 测试 isInterrupted 与 interrupted
*/
@Slf4j(topic = "c.Code_14_Test")
public class Code_14_Test {
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
log.info("park");
LockSupport.park();
log.info("unpark");
// log.info("打断标记为:{}", Thread.currentThread().isInterrupted());
log.info("打断标记为:{}", Thread.interrupted());
// 使用 Thread.currentThread().isInterrupted() 查看打断标记为 true, LockSupport.park() 失效
/**
* 执行结果:
* 11:54:17 [t1] c.Code_14_Test - park
* 11:54:18 [t1] c.Code_14_Test - unpark
* 11:54:18 [t1] c.Code_14_Test - 打断标记为:true
* 11:54:18 [t1] c.Code_14_Test - unpark
*/
// 使用 Thread.interrupted() 查看打断标记为 true, 然后清空打断标记为 false, LockSupport.park() 不失效
/**
* 执行结果:
* 11:58:12 [t1] c.Code_14_Test - park
* 11:58:13 [t1] c.Code_14_Test - unpark
* 11:58:13 [t1] c.Code_14_Test - 打断标记为:true
*/
LockSupport.park();
log.info("unpark");
}, "t1");
t1.start();
Thread.sleep(1000); // 主线程休眠 1 秒
t1.interrupt();
}
}
两阶段终止
考虑在一个线程T1中如何优雅地终止另一个线程T2?这里的优雅指的是给T2一个料理后事的机会(如释放锁)。
/**
* 使用 interrupt 进行两阶段终止模式
*/
@Slf4j(topic = "c.Code_13_Test")
public class Code_13_Test {
public static void main(String[] args) throws InterruptedException {
TwoParseTermination twoParseTermination = new TwoParseTermination();
twoParseTermination.start();
Thread.sleep(3500);
twoParseTermination.stop();
}
}
@Slf4j(topic = "c.TwoParseTermination")
class TwoParseTermination {
private Thread monitor;
// 启动线程
public void start() {
monitor = new Thread(() -> {
while (true) {
Thread thread = Thread.currentThread();
if(thread.isInterrupted()) { // 调用 isInterrupted 不会清除标记
log.info("料理后事 ...");
break;
} else {
try {
Thread.sleep(1000);
log.info("执行监控的功能 ...");
} catch (InterruptedException e) {
log.info("设置打断标记 ...");
thread.interrupt();
e.printStackTrace();
}
}
}
}, "monitor");
monitor.start();
}
// 终止线程
public void stop() {
monitor.interrupt();
}
}
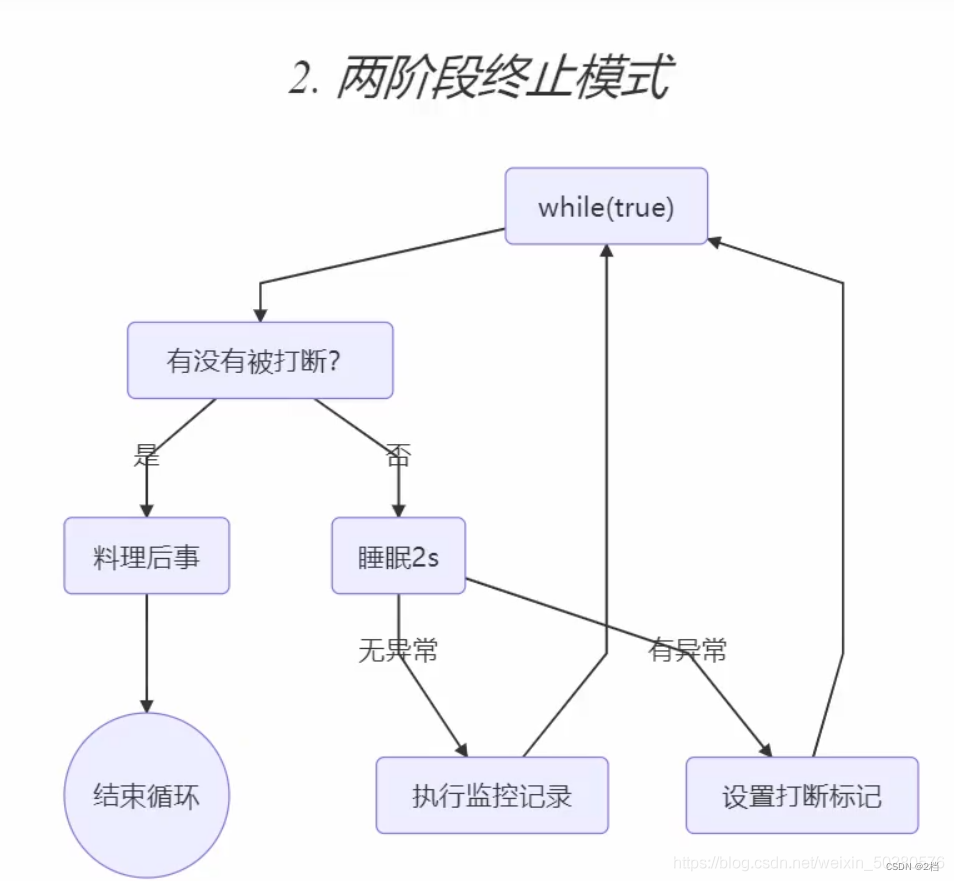
park和interrupt
线程park时被interrupt,会将线程唤醒,但是唤醒后线程无法再次park,因为此时打断标记已经变为true,如果想再次park线程,需要手动调用线程的interrupted方法(该方法返回线程当前打断并将打断状态重置为false),如此方能再次park。
1.2.4 守护线程
默认情况下,java进程需要等待所有的线程结束后才会停止,但是有一种特殊的线程,叫做守护线程,在其他线程全部结束的时候即使守护线程还未结束代码未执行完java进程也会停止。普通线程t1可以调用 t1.setDeamon(true); 方法变成守护线程。
注意:垃圾回收器线程就是一种守护线程 Tomcat 中的 Acceptor 和 Poller 线程都是守护线程,所以 Tomcat 接收到 shutdown 命令后,不会等 待它们处理完当前请求。
线程池默认线程工厂创建的线程为非守护线程(用户线程)
1.4 线程状态
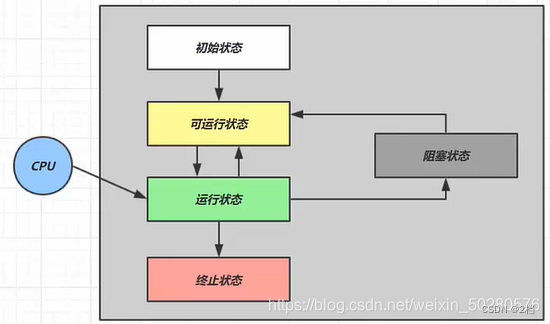
1.4.1 五种状态
从操作系统层划分,线程有 5 种状态
-
初始状态,仅仅是在语言层面上创建了线程对象,即Thead thread = new Thead();,还未与操作系统线程关联
-
可运行状态,也称就绪状态,指该线程已经被创建,与操作系统相关联,等待cpu给它分配时间片就可运行
-
运行状态,指线程获取了CPU时间片,正在运行 当CPU时间片用完,线程会转换至【可运行状态】,等待 CPU再次分配时间片,会导致我们前面讲到的上下文切换
-
阻塞状态
-
如果调用了阻塞API,如BIO读写文件,那么线程实际上不会用到CPU,不会分配CPU时间片,会导致上下文切换,进入【阻塞状态】
-
等待BIO操作完毕,会由操作系统唤醒阻塞的线程,转换至【可运行状态】
-
与【可运行状态】的区别是,只要操作系统一直不唤醒线程,调度器就一直不会考虑调度它们,CPU就一直不会分配时间片
-
-
终止状态,表示线程已经执行完毕,生命周期已经结束,不会再转换为其它状态
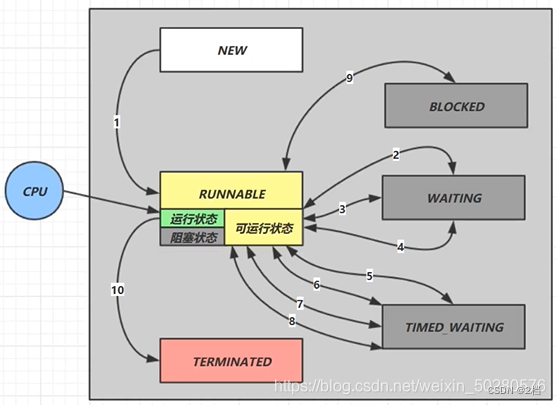
1.4.2 线程六种状态
这是从 Java API 层面来描述的,我们主要研究的就是这种
-
NEW 跟五种状态里的初始状态是一个意思
-
RUNNABLE 是当调用了 start() 方法之后的状态,注意,Java API 层面的 RUNNABLE 状态涵盖了操作系统层面的【可运行状态】、【运行状态】和【io阻塞状态】(由于 BIO 导致的线程阻塞,在 Java 里无法区分,仍然认为是可运行)
-
BLOCKED , WAITING , TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分。
六种状态代码演示如下:
/**
* 演示 java 线程的 6 种状态(NEW, RUNNABLE, TERMINATED, BLOCKED, WAITING, TIMED_WAITING)
*/
@Slf4j(topic = "c.Code_15_Test")
public class Code_15_Test {
public static void main(String[] args) {
// NEW,只创建不运行
Thread t1 = new Thread(() -> {
log.info("NEW 状态");
}, "t1");
// RUNNABLE,死循环执行
Thread t2 = new Thread(() -> {
while (true) {
}
}, "t2");
t2.start();
// TERMINATED,执行完毕
Thread t3 = new Thread(() -> {
log.info("running");
}, "t3");
t3.start();
// TIMED_WAITING,限时等待
Thread t4 = new Thread(() -> {
synchronized (Code_15_Test.class) {
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t4");
t4.start();
// WAITING,无限等待
Thread t5 = new Thread(() -> {
try {
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t5");
t5.start();
// BLOCKED,阻塞
Thread t6 = new Thread(() -> {
synchronized (Code_15_Test.class) {
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t6");
t6.start();
// 主线程休眠 1 秒, 目的是为了等待 t3 线程执行完
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("t1 线程状态: {}", t1.getState());
log.info("t2 线程状态: {}", t2.getState());
log.info("t3 线程状态: {}", t3.getState());
log.info("t4 线程状态: {}", t4.getState());
log.info("t5 线程状态: {}", t5.getState());
log.info("t6 线程状态: {}", t6.getState());
}
}
2. 共享模型之管程(monitor)
2.1 线程共享带来的问题
线程出现问题的根本原因是因为线程上下文切换,导致线程里的指令没有执行完就切换执行其它线程了。
2.1.1 临界区
-
一个程序运行多个线程本身是没有问题的
-
问题出在多个线程访问共享资源
-
多个线程读共享资源其实也没有问题
-
在多个线程对共享资源读写操作时发生指令交错,就会出现问题
-
-
一段代码块内如果存在对共享资源的多线程读写操作,称这段代码块为临界区
2.1.2 竞态条件
多个线程在临界区内执行,由于代码的执行序列不同而导致结果无法预测,称之为发生了竞态条件
2.2 解决并发的方法
为了避免临界区中的竞态条件发生,由多种手段可以达到。
-
阻塞式解决方案:synchronized ,Lock
-
非阻塞式解决方案:原子变量
2.2.1 synchronized
采用互斥的方式让同一时刻至多只有一个线程持有对象锁,其他线程如果想获取这个锁就会阻塞住,这样就能保证拥有锁的线程可以安全的执行临界区内的代码,不用担心线程上下文切换。
// 基本语法
synchronized(对象) {
//临界区
}
// 用在方法上
public class Test {
// 在方法上加上synchronized关键字
public synchronized void test() {
}
// 等价于
public void test() {
synchronized(this) { // 锁住的是对象
}
}
}
静态方法锁对象为Class对象,实例方法锁对象为实例本身
2.3 Monitor概念
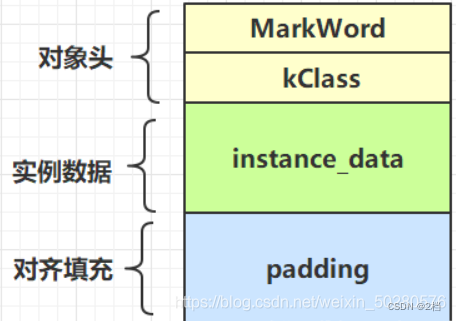
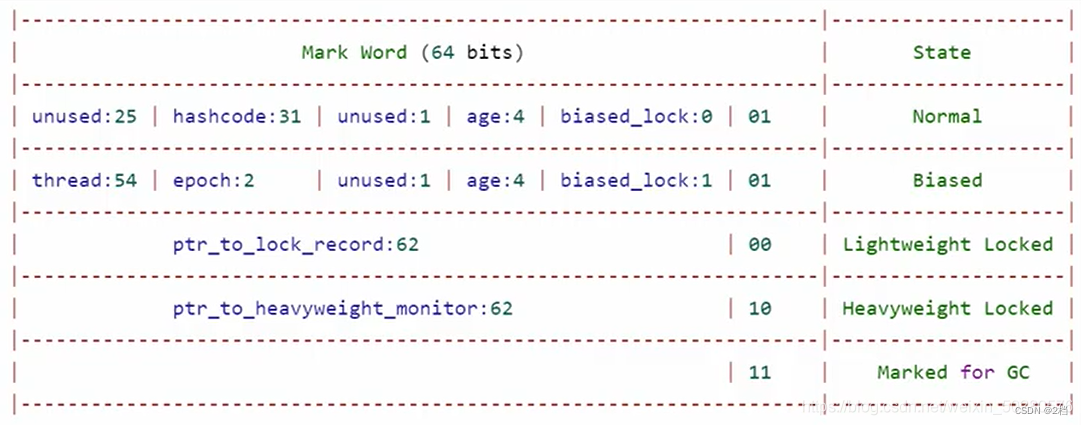
2.3.1 对象头(mark word)
以 32 位虚拟机为例
普通对象的对象头结构如下,其中的 Klass Word 为指针,指向对应的 Class 对象;
普通对象

数组对象

Mark word结构
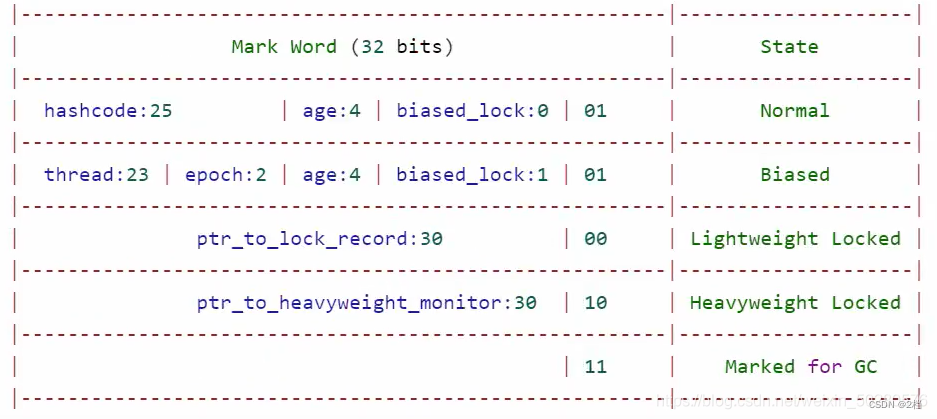
对象结构
2.3.2 Monitor原理
每个 java 对象都可以关联一个 Monitor ,如果使用 synchronized 给对象上锁(重量级),该对象头的 Mark Word 中就被设置为指向 Monitor 对象的指针。
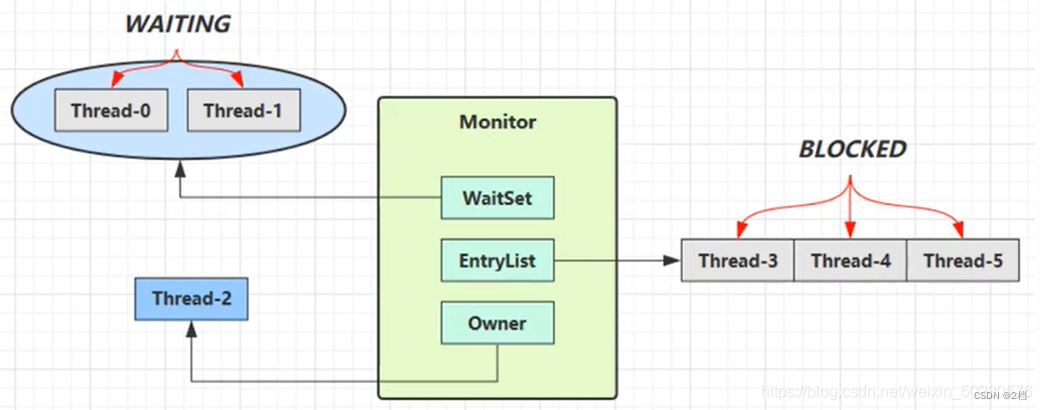
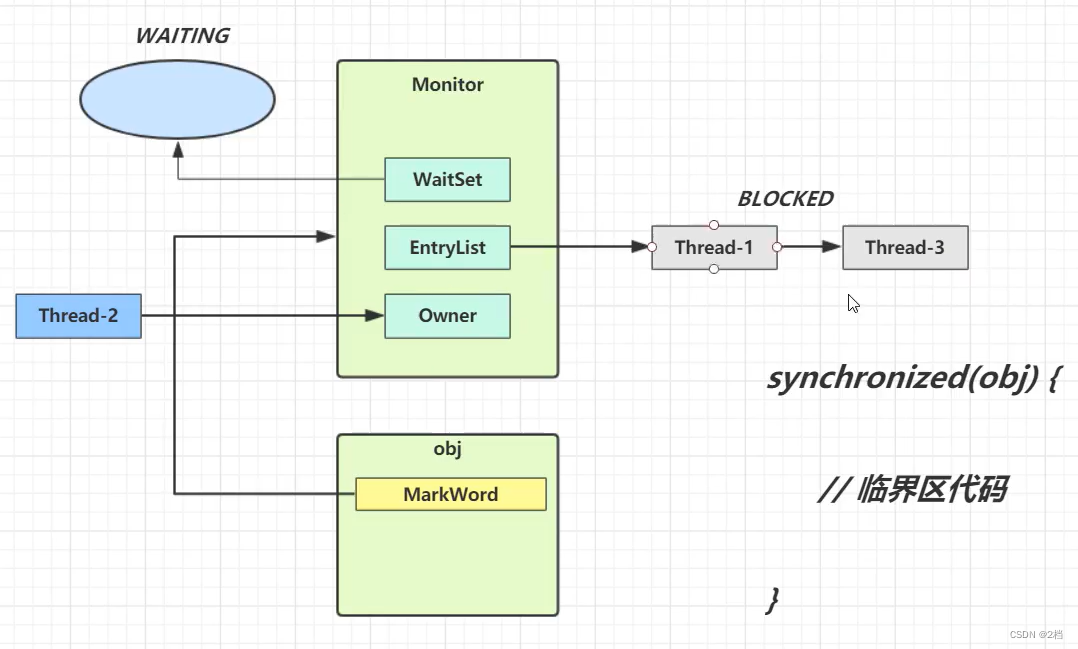
-
刚开始时 Monitor 中的 Owner 为 null
-
当 Thread-2 执行 synchronized(obj){} 代码时就会将 Monitor 的所有者Owner 设置为 Thread-2,上锁成功,Monitor 中同一时刻只能有一个 Owner
-
当 Thread-2 占据锁时,如果线程 Thread-3 ,Thread-4 也来执行synchronized(obj){} 代码,就会进入 EntryList(阻塞队列) 中变成BLOCKED(阻塞) 状态
-
Thread-2 执行完同步代码块的内容,然后唤醒 EntryList 中等待的线程来竞争锁,竞争时是非公平的
-
图中 WaitSet 中的 Thread-0,Thread-1 是之前获得过锁,但条件不满足进入 WAITING 状态的线程,后面讲 wait-notify 时会分析
注意:synchronized 必须是进入同一个对象的 monitor 才有上述的效果不加 synchronized 的对象不会关联监视器,不遵从以上规则
2.3.3 synchronized原理
static final Object lock = new Object();
static int counter = 0;
public static void main (String[] args) {
synchronized (lock) {
counter++;
}
}
反编译字节码为:

2.4 锁优化
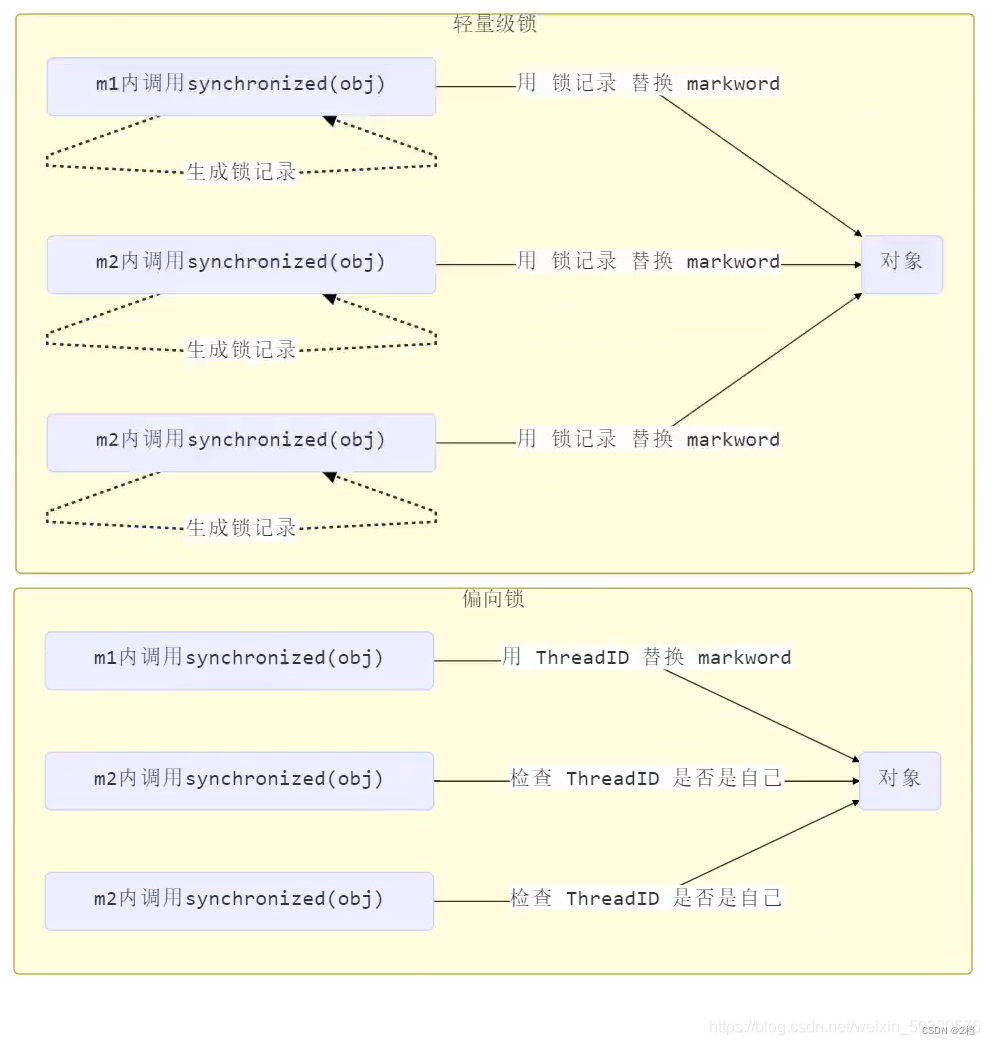
2.4.1 轻量级锁
轻量级锁的使用场景是:如果一个对象虽然有多个线程要对它进行加锁,但是加锁的时间是错开的(也就是没有人可以竞争的),那么可以使用轻量级锁来进行优化。轻量级锁对使用者是透明的,即语法仍然是 synchronized ,假设有两个方法同步块,利用同一个对象加锁
static final Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// 同步块 A
method2();
}
}
public static void method2() {
synchronized( obj ) {
// 同步块 B
}
}
-
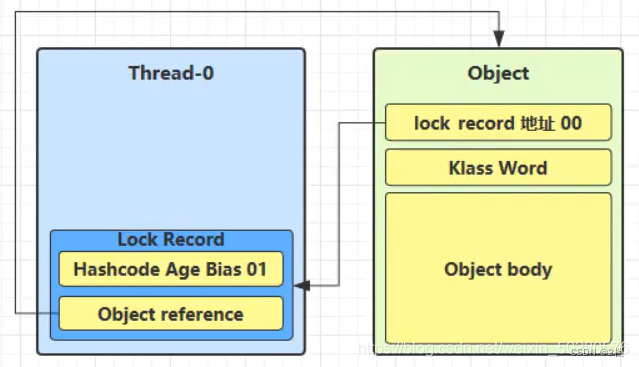
每次指向到 synchronized 代码块时,都会创建锁记录(Lock Record)对象,每个线程都会包括一个锁记录的结构,锁记录内部可以储存对象的 Mark Word 和对象引用 reference
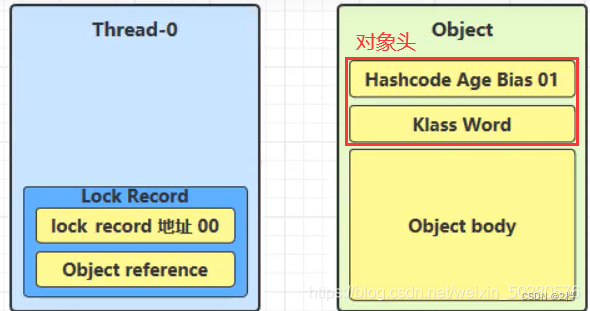
-
让锁记录中的 Object reference 指向对象,并且尝试用 cas(compare and sweep) 替换 Object 对象的 Mark Word ,将 Mark Word 的值存入锁记录中。
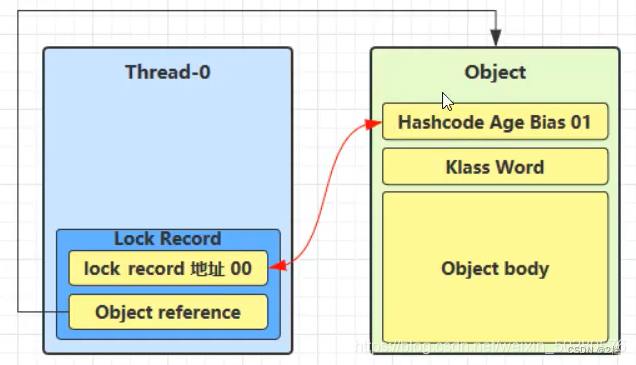
-
如果 cas 替换成功,那么对象的对象头储存的就是锁记录的地址和状态 00 表示轻量级锁,如下所示
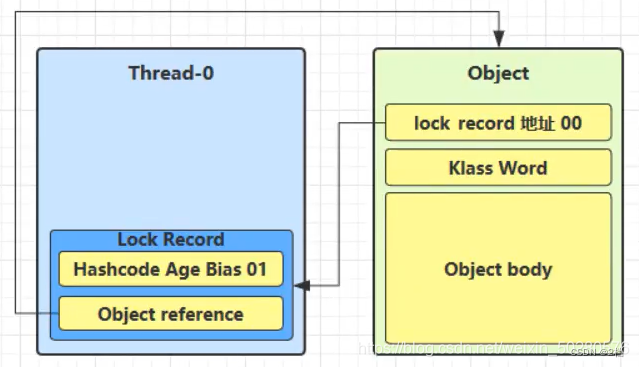
-
如果cas失败,有两种情况
-
如果是其它线程已经持有了该 Object 的轻量级锁,那么表示有竞争,首先会进行自旋锁,自旋一定次数后,如果还是失败就进入锁膨胀阶段。
-
如果是自己的线程已经执行了 synchronized 进行加锁,那么再添加一条 Lock Record 作为重入的计数。
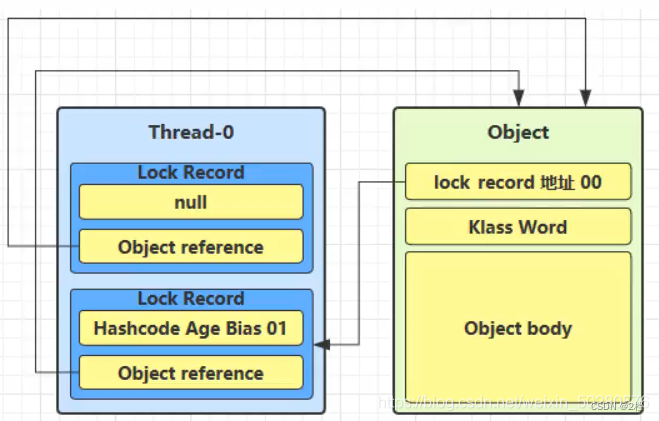
-
-
当线程退出 synchronized 代码块的时候,如果获取的是取值为 null 的锁记录,表示有重入,这时重置锁记录,表示重入计数减一
-
当线程退出 synchronized 代码块的时候,如果获取的锁记录取值不为 null,那么使用 CAS 将 Mark Word 的值恢复给对象
-
成功则解锁成功
-
失败,则说明轻量级锁进行了锁膨胀或已经升级为重量级锁,进入重量级锁解锁流程
-
2.4.2 锁膨胀
如果在尝试加轻量级锁的过程中,cas 操作无法成功,这是有一种情况就是其它线程已经为这个对象加上了轻量级锁,这是就要进行锁膨胀,将轻量级锁变成重量级锁。
-
当 Thread-1 进行轻量级加锁时,Thread-0 已经对该对象加了轻量级锁
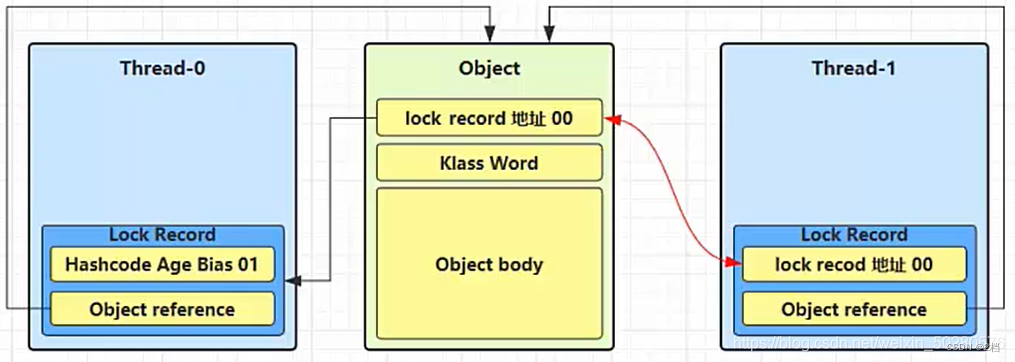
-
这时 Thread-1 加轻量级锁失败,进入锁膨胀流程,
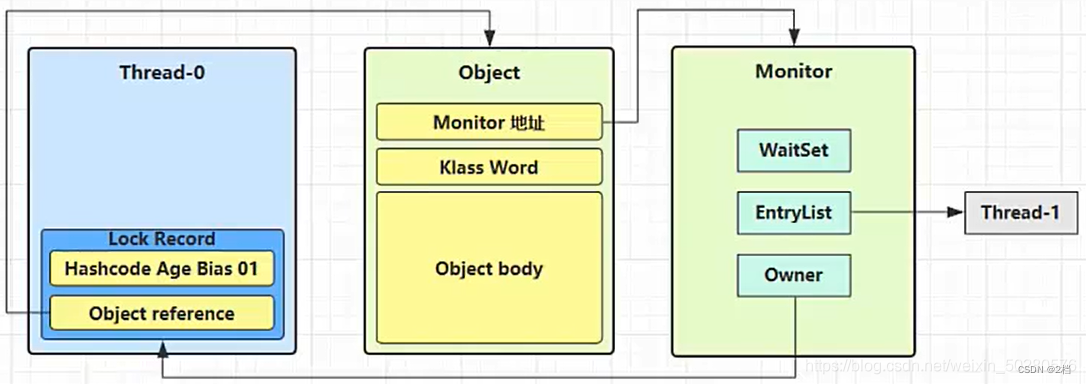
-
即为对象申请Monitor锁,让Object指向重量级锁地址
-
然后自己进入Monitor 的EntryList 变成BLOCKED状态
-
-
当 Thread-0 退出 synchronized 同步块时,使用 CAS 将 Mark Word 的值恢复给对象头,对象的对象头指向 Monitor,那么会进入重量级锁的解锁过程,即按照 Monitor 的地址找到 Monitor 对象,将 Owner 设置为 null ,唤醒 EntryList 中的 Thread-1 线程
2.4.3 自旋锁
2.4.4 偏向锁
在轻量级的锁中,我们可以发现,如果同一个线程对同一个对象进行重入锁时,也需要执行 CAS 操作,这是有点耗时滴,那么 java6 开始引入了偏向锁的东东,只有第一次使用 CAS 时将对象的 Mark Word 头设置为偏向线程 ID,之后这个入锁线程再进行重入锁时,发现线程 ID 是自己的,那么就不用再进行CAS了。 分析代码,比较轻量级锁与偏向锁
static final Object obj = new Object();
public static void m1() {
synchronized(obj) {
// 同步块 A
m2();
}
}
public static void m2() {
synchronized(obj) {
// 同步块 B
m3();
}
}
public static void m3() {
synchronized(obj) {
// 同步块 C
}
}
分析如图:
偏向状态
对象头格式如下:
一个对象的创建过程
-
如果开启了偏向锁(默认是开启的),那么对象刚创建之后,Mark Word 最后三位的值101,并且这是它的 Thread,epoch,age 都是 0 ,在加锁的时候进行设置这些的值.
-
偏向锁默认是延迟的,不会在程序启动的时候立刻生效,如果想避免延迟,可以添加虚拟机参数来禁用延迟: -XX:BiasedLockingStartupDelay=0 来禁用延迟
-
注意:处于偏向锁的对象解锁后,线程 id 仍存储于对象头中
撤销偏向
以下几种情况会使对象的偏向锁失效
-
调用对象的 hashCode 方法
-
多个线程使用该对象
-
调用了 wait/notify 方法(调用wait方法会导致锁膨胀而使用重量级锁)
批量重偏向
-
如果对象虽然被多个线程访问,但是线程间不存在竞争,这时偏向 t1 的对象仍有机会重新偏向 t2
-
重偏向会重置Thread ID
-
-
当撤销超过20次后(超过阈值),JVM 会觉得是不是偏向错了,这时会在给对象加锁时,重新偏向至加锁线程。
批量撤销(当撤销超过40次,就会将整个类置为不可偏向状态)
当撤销偏向锁的阈值超过 40 以后,就会将整个类的对象都改为不可偏向的
2.5 wait-notify
2.5.1 原理
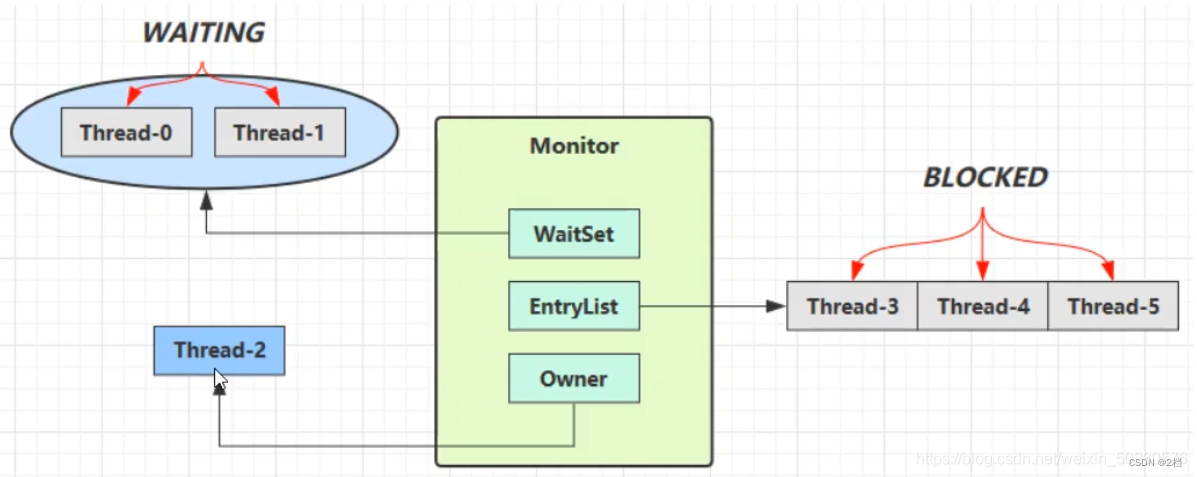
-
锁对象调用wait方法(obj.wait),就会使当前线程进入 WaitSet 中,变为 WAITING 状态。
-
处于BLOCKED和 WAITING 状态的线程都为阻塞状态,CPU 都不会分给他们时间片。但是有所区别:
-
BLOCKED 状态的线程是在竞争对象时,发现 Monitor 的 Owner 已经是别的线程了,此时就会进入 EntryList 中,并处于 BLOCKED 状态
-
WAITING 状态的线程是获得了对象的锁,但是自身因为某些原因需要进入阻塞状态时,锁对象调用了 wait 方法而进入了 WaitSet 中,处于 WAITING 状态
-
-
BLOCKED 状态的线程会在锁被释放的时候被唤醒,但是处于 WAITING 状态的线程只有被锁对象调用了 notify 方法(obj.notify/obj.notifyAll),才会被唤醒。
注:只有当对象加锁以后,才能调用 wait 和 notify 方法
2.5.2 Wait 与 Sleep 的区别
-
Sleep 是 Thread 类的静态方法,Wait 是 Object 的方法,Object 又是所有类的父类,所以所有类都有Wait方法。
-
Sleep 在阻塞的时候不会释放锁,而 Wait 在阻塞的时候会释放锁,它们都会释放 CPU 资源。
-
Sleep 不需要与 synchronized 一起使用,而 Wait 需要与 synchronized 一起使用(对象被锁以后才能使用) 使用 wait 一般需要搭配 notify 或者 notifyAll 来使用,不然会让线程一直等待。
2.5.3 优雅使用wait-notify
-
当线程不满足某些条件,需要暂停运行时,可以使用 wait 。这样会将对象的锁释放,让其他线程能够继续运行。如果此时使用 sleep,会导致所有线程都进入阻塞,导致所有线程都没法运行,直到当前线程 sleep 结束后,运行完毕,才能得到执行。 使用wait/notify需要注意什么(需要在synchronized中使用这些方法,因为只有持有锁对象才能调用这些方法)
-
当有多个线程在运行时,对象调用了 wait 方法,此时这些线程都会进入 WaitSet 中等待。如果这时使用了 notify 方法,可能会造成虚假唤醒(唤醒的不是满足条件的等待线程),这时就需要使用 notifyAll 方法
synchronized (lock) {
while(//不满足条件,一直等待,避免虚假唤醒) {
lock.wait();
}
//满足条件后再运行
}
synchronized (lock) {
//唤醒所有等待线程
lock.notifyAll();
}
2.5.4 保护性暂停(一个消息由一个线程产生,并由一个线程消费)
即 Guarded Suspension,用在一个线程等待另一个线程的执行结果,要点:
-
有一个结果需要从一个线程传递到另一个线程,让他们关联同一个 GuardedObject
-
如果有结果不断从一个线程到另一个线程那么可以使用消息队列(见生产者/消费者)
-
JDK 中,join 的实现、Future 的实现,采用的就是此模式
-
因为要等待另一方的结果,因此归类到同步模式
多任务版 GuardedObject 图中 Futures 就好比居民楼一层的信箱(每个信箱有房间编号),左侧的 t0,t2,t4 就好比等待邮件的居民,右侧的 t1,t3,t5 就好比邮递员如果需要在多个类之间使用 GuardedObject 对象,作为参数传递不是很方便,因此设计一个用来解耦的中间类,这样不仅能够解耦【结果等待者】和【结果生产者】,还能够同时支持多个任务的管理。和生产者消费者模式的区别就是:这个生产者和消费者之间是一一对应的关系,但是生产者消费者模式并不是。rpc 框架的调用中就使用到了这种模式。
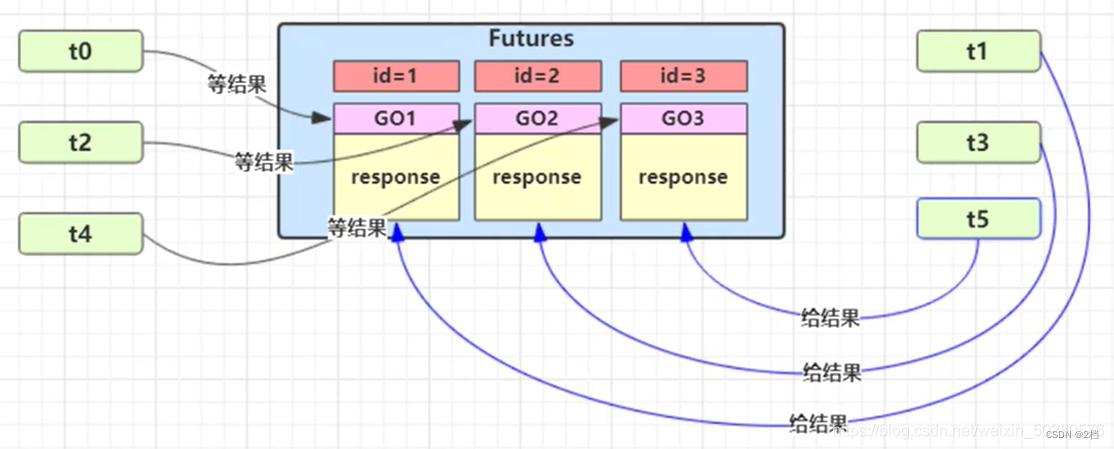
/**
* 同步模式-保护性暂停 (Guarded-Suspension-pattern)
*/
@Slf4j(topic = "c.Code_23_Test")
public class Code_23_Test {
public static void main(String[] args) {
// 三个居民创建三个传递信息的类放入邮箱,等待邮递员往里面传递信息
for (int i = 0; i < 3; i++) {
new People().start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 三个邮递员分别向一个传递信息的类中输入信息
for(Integer id : Mailboxes.getIds()) {
new Postman(id, "内容 " + id).start();
}
}
}
@Slf4j(topic = "c.People")
// 创建传递信息的类,并限时等待信息
class People extends Thread {
@Override
public void run() {
GuardedObject guardedObject = Mailboxes.createGuardedObject();
log.info("收信的为 id: {}", guardedObject.getId());
Object o = guardedObject.get(5000);
log.info("收到信的 id: {}, 内容: {}", guardedObject.getId(), o);
}
}
@Slf4j(topic = "c.Postman")
// 获取传递信息的类,并将信息进行传递
class Postman extends Thread {
private int id;
private String mail;
public Postman(int id, String mail) {
this.id = id;
this.mail = mail;
}
@Override
public void run() {
GuardedObject guardedObject = Mailboxes.getGuardedObject(id);
log.info("送信的 id: {}, 内容: {}", id, mail);
guardedObject.complete(mail);
}
}
// 保存传递信息的类
class Mailboxes {
private static int id = 1;
private static Map<Integer, GuardedObject> boxes = new Hashtable<>();
public static synchronized int generateId() {
return id++;
}
// 用户会进行投信
public static GuardedObject createGuardedObject() {
GuardedObject guardedObject = new GuardedObject(generateId());
boxes.put(guardedObject.getId(), guardedObject);
return guardedObject;
}
// 派件员会派发信
public static GuardedObject getGuardedObject(int id) {
return boxes.remove(id);
}
public static Set<Integer> getIds() {
return boxes.keySet();
}
}
// 传递信息的类
class GuardedObject {
private int id;
public GuardedObject(int id) {
this.id = id;
}
public int getId() {
return this.id;
}
private Object response;
// 优化等待时间
public Object get(long timeout) {
synchronized (this) {
long begin = System.currentTimeMillis();
long passTime = 0;
while (response == null) {
long waitTime = timeout - passTime; // 剩余等待时间
if(waitTime <= 0) {
break;
}
try {
this.wait(waitTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
passTime = System.currentTimeMillis() - begin;
}
return response;
}
}
public void complete(Object response) {
synchronized (this) {
this.response = response;
this.notify();
}
}
}
2.5.5 生产者消费者(一个线程可产生多个消息,一个线程可消费多个消息)
-
与前面的保护性暂停中的 GuardObject 不同,不需要产生结果和消费结果的线程一一对应
-
消费队列可以用来平衡生产和消费的线程资源
-
生产者仅负责产生结果数据,不关心数据该如何处理,而消费者专心处理结果数据
-
消息队列是有容量限制的,满时不会再加入数据,空时不会再消耗数据
-
JDK 中各种阻塞队列,采用的就是这种模式
“异步”的意思就是生产者产生消息之后消息没有被立刻消费,而“同步模式”中,消息在产生之后被立刻消费了。
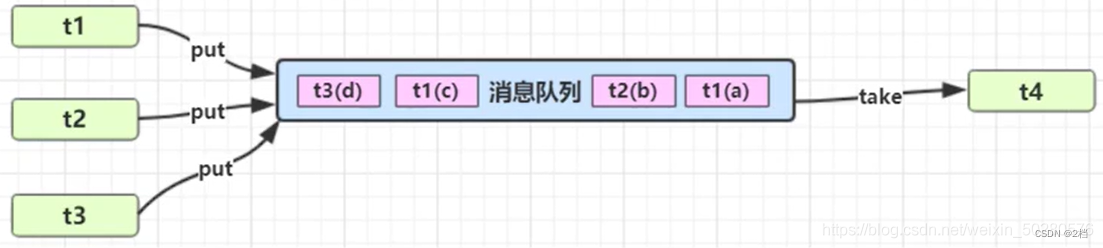
小结:
-
当调用 wait 时,首先需要确保调用了 wait 方法的线程已经持有了对象的锁(调用 wait 方法的代码片段需要放在 sychronized 块或者时 sychronized 方法中,这样才可以确保线程在调用wait方法前已经获取到了对象的锁)
-
当调用 wait 时,该线程就会释放掉这个对象的锁,然后进入等待状态 (wait set)
-
当线程调用了 wait 后进入到等待状态时,它就可以等待其他线程调用相同对象的 notify 或者 notifyAll 方法使得自己被唤醒
-
一旦这个线程被其它线程唤醒之后,该线程就会与其它线程以同开始竞争这个对象的锁(公平竞争);只有当该线程获取到对象的锁后,线程才会继续往下执行
-
当调用对象的 notify 方法时,他会随机唤醒对象等待集合 (wait set) 中的任意一个线程,当某个线程被唤醒后,它就会与其它线程一同竞争对象的锁
-
当调用对象的 notifyAll 方法时,它会唤醒该对象等待集合 (wait set) 中的所有线程,这些线程被唤醒后,又会开始竞争对象的锁
-
在某一时刻,只有唯一的一个线程能拥有对象的锁
// 消息队列,Java线程间通信
class MessageQueue {
// 消息队列集合
private final LinkedList<Message> list = new LinkedList<>();
// 队列容量
private int capacity;
public MessageQueue(int capacity) {
this.capacity = capacity;
}
// 获取消息的方法
public Message take() {
// 检查队列是否为空
synchronized (list) {
while (list.isEmpty()) {
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 从队列头部获取消息返回
Message message = list.removeFirst();
list.notifyAll();
return message;
}
}
// 存入消息的方法
public void put(Message message) {
synchronized (list) {
// 检查队列是否已满
while (list.size() == capacity) {
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 尾部
list.addLast(message);
list.notifyAll();
}
}
}
final class Message {
private final int id;
private final Object value;
public Message(int id, Object value) {
this.id = id;
this.value = value;
}
public int getId() {
return id;
}
public Object getValue() {
return value;
}
@Override
public String toString() {
return "Message{" +
"id=" + id +
", value=" + value +
'}';
}
}
2.5.5 park和unpark
2.5.5.1 基本使用
park & unpark 是 LockSupport 线程通信工具类的静态方法。
// 暂停当前线程 LockSupport.park(); // 恢复某个线程的运行 LockSupport.unpark;
2.5.5.2 原理
每个线程都有自己的一个 Parker 对象,由三部分组成 _counter, _cond 和 _mutex
-
打个比喻线程就像一个旅人,Parker 就像他随身携带的背包,条件变量 _ cond 就好比背包中的帐篷。_counter 就好比背包中的备用干粮(0 为耗尽,1 为充足)
-
调用 park 就是要看需不需要停下来歇息
-
如果备用干粮耗尽,那么钻进帐篷歇息
-
如果备用干粮充足,那么不需停留,继续前进
-
-
调用 unpark,就好比令干粮充足
-
如果这时线程还在帐篷,就唤醒让他继续前进
-
如果这时线程还在运行,那么下次他调用 park 时,仅是消耗掉备用干粮,不需停留继续前进
-
因为背包空间有限,多次调用 unpark 仅会补充一份备用干粮
-
-
先调用park再调用upark的过程
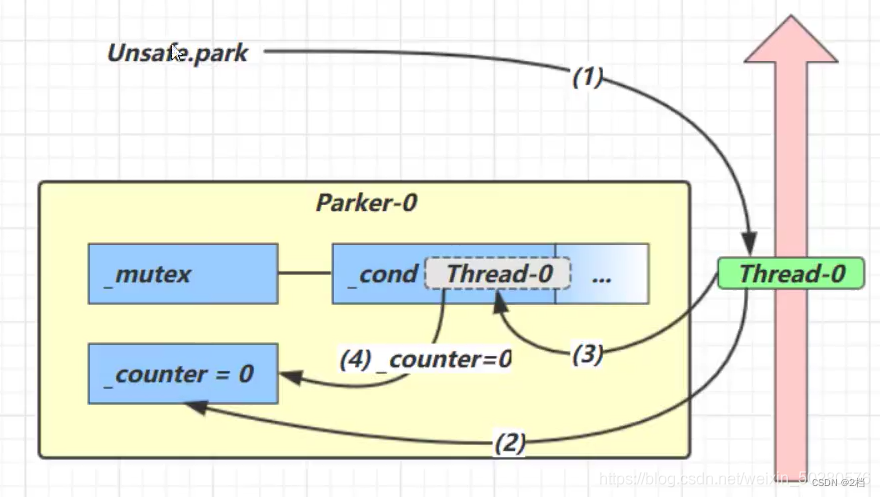
先调用 park
-
当前线程调用 Unsafe.park() 方法
-
检查 _counter ,本情况为 0,这时,获得 _mutex 互斥锁(mutex对象有个等待队列 _cond)
-
线程进入 _cond 条件变量阻塞
-
设置 _counter = 0
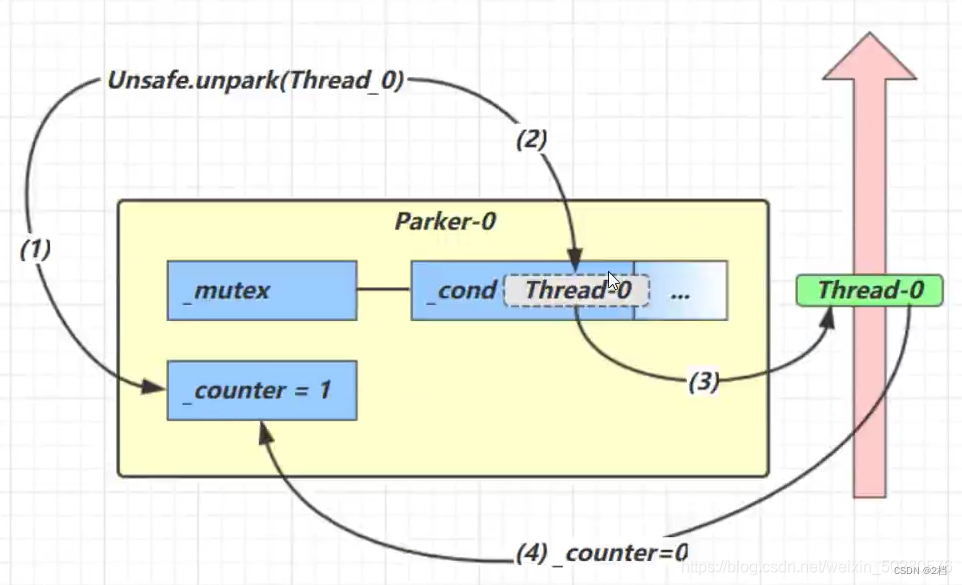
调用 upark
-
调用 Unsafe.unpark(Thread_0) 方法,设置 _counter 为 1
-
唤醒 _cond 条件变量中的 Thread_0
-
Thread_0 恢复运行
-
设置 _counter 为 0
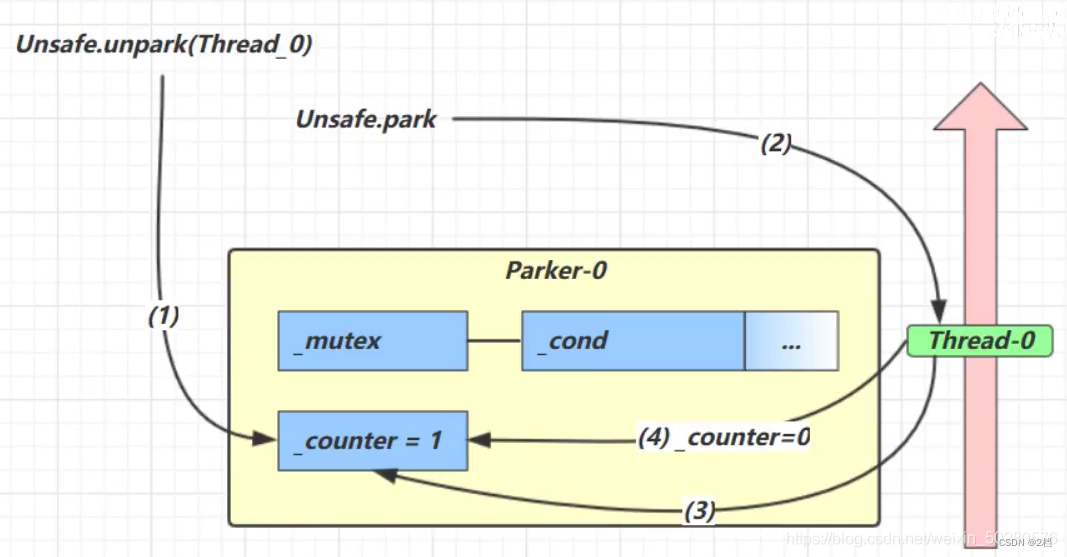
先调用upark再调用park的过程
-
调用 Unsafe.unpark(Thread_0) 方法,设置 _counter 为 1
-
当前线程调用 Unsafe.park() 方法
-
检查 _counter ,本情况为 1,这时线程无需阻塞,继续运行
-
设置 _counter 为 0
2.6 ReentrantLock
和 synchronized 相比具有的的特点
-
可中断
-
可以设置超时时间
-
可以设置为公平锁 (先到先得)
-
支持多个条件变量( 具有多个 WaitSet)
// 获取ReentrantLock对象
private ReentrantLock lock = new ReentrantLock();
// 加锁
lock.lock();
try {
// 需要执行的代码
}finally {
// 释放锁
lock.unlock();
}
2.6.1 可重入
-
可重入是指同一个线程如果首次获得了这把锁,那么因为它是这把锁的拥有者,因此有权利再次获取这把锁
-
如果是不可重入锁,那么第二次获得锁时,自己也会被锁挡住
2.6.2 可打断
如果某个线程处于阻塞状态,可以调用其 interrupt 方法让其停止阻塞,获得锁失败,简而言之就是:处于阻塞状态的线程,被打断了就不用阻塞了,直接停止运行
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
try {
// 加锁,可打断锁
lock.lockInterruptibly();
} catch (InterruptedException e) {
e.printStackTrace();
// 被打断,返回,不再向下执行
return;
}finally {
// 释放锁
lock.unlock();
}
});
lock.lock();
try {
t1.start();
Thread.sleep(1000);
// 打断
t1.interrupt();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
2.6.3 锁超时
使用 lock.tryLock 方法会返回获取锁是否成功。如果成功则返回 true ,反之则返回 false 。 并且 tryLock 方法可以指定等待时间,参数为:tryLock(long timeout, TimeUnit unit), 其中 timeout 为最长等待时间,TimeUnit 为时间单位 简而言之就是:获取锁失败了、获取超时了或者被打断了,不再阻塞,直接停止运行。 不设置等待时间
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
// 未设置等待时间,一旦获取失败,直接返回false
if(!lock.tryLock()) {
System.out.println("获取失败");
// 获取失败,不再向下执行,返回
return;
}
System.out.println("得到了锁");
lock.unlock();
});
lock.lock();
try{
t1.start();
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
设置等待时间
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
try {
// 判断获取锁是否成功,最多等待1秒
if(!lock.tryLock(1, TimeUnit.SECONDS)) {
System.out.println("获取失败");
// 获取失败,不再向下执行,直接返回
return;
}
} catch (InterruptedException e) {
e.printStackTrace();
// 被打断,不再向下执行,直接返回
return;
}
System.out.println("得到了锁");
// 释放锁
lock.unlock();
});
lock.lock();
try{
t1.start();
// 打断等待
t1.interrupt();
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
2.6.4 公平锁
在线程获取锁失败,进入阻塞队列时,先进入的会在锁被释放后先获得锁。这样的获取方式就是公平的。
// 默认是不公平锁,需要在创建时指定为公平锁 ReentrantLock lock = new ReentrantLock(true);
2.6.5 条件变量
synchronized 中也有条件变量,就是我们讲原理时那个 waitSet 休息室,当条件不满足时进入waitSet 等待。 ReentrantLock 的条件变量比 synchronized 强大之处在于,它是支持多个条件变量的,这就好比
-
synchronized 是那些不满足条件的线程都在一间休息室等消息
-
而 ReentrantLock 支持多间休息室,有专门等烟的休息室、专门等早餐的休息室、唤醒时也是按休息室来唤醒
使用要点:
-
await 前需要获得锁
-
await 执行后,会释放锁,进入 conditionObject 等待
-
await 的线程被唤醒(或打断、或超时)取重新竞争 lock 锁
-
竞争 lock 锁成功后,从 await 后继续执
2.7 AQS
AQS:Abstract Queued Synchronizer(抽象队列同步器)
作用是提供一个获取以及释放锁的框架,AQS完成了大部分内容,我们只需要按需重写:
tryAcquire(int i) // 尝试从state获取i
tryRelease(int i) //尝试从state返还i
tryAcquireShared(int i) // 尝试以共享方式从state获取i
tryReleaseShared(int i) //尝试以共享方式从state返还i
isHeldExclusive() //判断当前线程是否是独占线程
AQS 的核心是 state 变量的维护,通过修改该变量的值,我们可以利用CAS实现锁的功能,其实本质就是将state的值通过 CAS 从一个状态转换为另外一个状态是否成功,成功就表示获取锁成功,否则失败,因此 AQS 的基础是 CAS,而我们经常使用的 ReentrantLock、ReentrantReadWriteLock、CountdownLach、CyclicBarrier、Semaphore 等都是基于 AQS 实现的。
获取锁:
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
首先尝试获取锁,此处的 tryAcquire 方法就是我们需要重写的方法,我们只需要这个方法中明确写出 state 状态从一个状态转换为另一个状态是否成功即可,以 ReentrantLock 的非公平锁为例:
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
final boolean nonfairTryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 获取当前 state 的值
int c = getState();
// 如果 state 为 0,则尝试将之从 0 变为非 0,非 0 表示加锁成功
if (c == 0) {
// 尝试将 state 修改为 acquires
if (compareAndSetState(0, acquires)) {
// 如果修改成功,则表示获取锁成功,将线程设置为当前 ExclusiveOwnerThread
setExclusiveOwnerThread(current);
return true;
}
}
// 如果 state 不为 0,则表示已经有线程已经加锁成功,判断该线程是否是当前线程
else if (current == getExclusiveOwnerThread()) {
// 如果是当前线程,锁重入,将 state 的值增加
int nextc = c + acquires;
// 如果冲入次数过大溢出,则抛异常
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
// 修改 state 的值并返回 true
setState(nextc);
return true;
}
// 否则返回 0
return false;
}
从 ReentrantLock 的 acquire 方法,我们可以知道 ReentrantLock 的中 AQS 的使用理念,state 为 0 表示未加锁,非 0 表示加锁并且数值表示重入次数
当获取锁失败,进入 acquireQueued(addWaiter(Node.EXCLUSIVE), arg),该方法作用很简单,请求入队并阻塞等待锁,请求入队代码如下:
private Node addWaiter(Node mode) {
// 创建 node
Node node = new Node(mode);
// 将节点加入链表尾部
for (;;) {
// 获取尾节点
Node oldTail = tail;
if (oldTail != null) {
// 设置节点前驱节点为尾节点
node.setPrevRelaxed(oldTail);
// 将该节点设置为新的尾节点
if (compareAndSetTail(oldTail, node)) {
// 设置成功,老的尾节点的 next 指向新的尾节点
oldTail.next = node;
// 返回节点
return node;
}
} else {
// 尾节点位空,则创建队列
initializeSyncQueue();
}
}
}
//初始化队列很简单,创建一个 node,head 和 tail 都指向该 node(该 node 称之为 dummy 哨兵节点)
private final void initializeSyncQueue() {
Node h;
if (HEAD.compareAndSet(this, null, (h = new Node())))
tail = h;
}
阻塞等待代码如下:
final boolean acquireQueued(final Node node, int arg) {
boolean interrupted = false;
try {
for (;;) {
// 找新建节点的前驱节点
final Node p = node.predecessor();
// 如果当前节点前驱节点为头节点(当前节点为老二节点),尝试获取锁
if (p == head && tryAcquire(arg)) {
// 如果获取成功,将当前节点设为头节点,并且将旧的头节点 next 置为 null
setHead(node);
p.next = null; // help GC
return interrupted;
}
// 判断当前节点是否应该 park,只有当当前节点的前驱节点 waitStatus 为 -1 时才为 true
if (shouldParkAfterFailedAcquire(p, node))
// park 被解除以后重新尝试获取锁
interrupted |= parkAndCheckInterrupt();
}
} catch (Throwable t) {
cancelAcquire(node);
if (interrupted)
selfInterrupt();
throw t;
}
}
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
// 节点前驱节点被取消,从前往后找到第一个未被取消的节点并返回 false
if (ws > 0) {
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// waitStatus 为 0 或者 PROPAGATE,尝试将其修改为 -1,返回 false
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
pred.compareAndSetWaitStatus(ws, Node.SIGNAL);
}
return false;
}
// park 当前线程,当被 unpark 时,查看当前线程是否被 interrupt
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
// 会重置 interrupt 为 false
return Thread.interrupted();
}
AQS 中还有 acquireNanos,acquireInterrupted 等方法,这些方法本质不同就在于 park 时调用什么方法以及 interrupt 时怎么反应,如下:
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
// 基本跟 acquireQueued 方法一样,只不过这里如果 interrupt 为 true,直接抛异常
throw new InterruptedException();
}
} catch (Throwable t) {
cancelAcquire(node);
throw t;
}
}
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (nanosTimeout <= 0L)
return false;
final long deadline = System.nanoTime() + nanosTimeout;
final Node node = addWaiter(Node.EXCLUSIVE);
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
return true;
}
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0L) {
cancelAcquire(node);
return false;
}
// 基本上跟 acquireQueued 方法一样,只不过维护了 timeout 属性,并且调用的是
// LockSupport.parkNanos 限时阻塞方法
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > SPIN_FOR_TIMEOUT_THRESHOLD)
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} catch (Throwable t) {
cancelAcquire(node);
throw t;
}
}
ReentrantReadWriteLock 中将 state 高16位 用作记录写锁,低 16 位用作记录读锁,这样可以用一个变量表示读写加锁条件
CountdownLatch 中则将 state 为 0 作为 acquire 成功的标志,await 方法调用 acquireSharedInterruptibly 方法,我们重写的 tryAcquire 方法如下:
// 只有当 state 为 0 时,acqire 才为 true,await 才能解除阻塞
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
CyclicBarrier 中则是通过 ReentrantLock 来实现的
Semaphre 中则是将 state 用作可用资源数量记录,当 state 不为 0 时,每次 acquire 会将 state 值减一,直至减为 0,当 state 值为 0 时,阻塞等待
甚至 ThreadPoolExecutor 中的 Worker 也使用 AQS,Worker 新建时 state 为 -1,运行时会先将 state 修改为 0,然后在真正执行 task 时会获取 lock(为什么需要获取 lock 呢?因为在计算 activeCount、taskCount 等时需要先暂停执行 task,统计完成以后在恢复运行)















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









