







1. Wireshark抓包过程遇到的一点小问题
在使用wireshark进行抓包时,发现目标为本机时,无法抓包,这是由于wireshark并不会抓取本机loop的流量,只会抓取流经网卡的流量,如果需要使用wireshark抓取本机的数据包,那么可以采用新增路由的方法,具体如下:
route add 本机ip mask 255.255.255.255 网关ip,例如:
route add 10.133.146.63 mask 255.255.255.255 10.133.146.1
使用完毕以后需要注意的是,要及时删除该路由,不然否则所有本机报文都经过网卡出去走一圈回来很耗性能。删除方式如下所示:
route delete 10.133.146.63 mask 255.255.255.255 10.133.146.1
2. Telnet发送数据包规则
在开发telnet功能时,需要研究telnet发送数据包的规则,经过抓包以后发现,telnet客户端在用户每键入一个字符,都向服务端发送一个字符,以前已经发送过的字符,不会再次发送,因此服务端需要注意的是,在接收来自客户端的请求时,消费ByteBuf数据时,消费完毕以后,如果需要等待后续输入,那么需要将readerIndex复原。
3. 编写Netty客户端
编写Netty客户端时,遇到数据无法发送的问题,该问题是由于缺少编解码器造成的,需要添加编解码器,并且需要注意编解码器的问题,位于业务处理之前,但是与心跳检测的handler不知道有无位置要求,编写时最好不管是client还是server,都将编解码器
4. 使用javadoc-plugin遇到的问题
在使用javadoc-plugin时,经常遇到一些问题,主要是不能使用@date 注解,使用@return 注解时,后面不允许空着,还有就是在javadoc中使用html各种标签以及字符实体等,有些字符不允许直接使用,比如 "&、>、<" 等字符
5. 关于配置文件
SpringBoot中加载配置文件会直接将applicaiton.properties加载到environment中,因此可以直接从environment中获取配置文件中的配置,包括使用下面方式导入的配置文件:
10. Maven shade plugin的作用
该插件作用主要有两个,第一个是代码拷贝,当需要使用一个依赖中某些类时,可以通过shade打包这些类,这样可以不用自己进行类的拷贝,第二个作用是替换包名解决冲突,利用shade方式解决冲突有其局限性,当项目中有使用Class.forName等方法时时会出现问题,还有就是使用SPI时,由于包名已经改变,SPI加载类也会出现问题,因此shade的使用有一定的局限性,使用时需要考虑这些因素对项目是否有影响
11. Map使用computeIfAbsent阻塞问题
在使用ConcurrentHashMap时,由于内部自动同步,因此在使用computeIfAbsent等方法时,方法内部应该要避免操作该map,因为在方法内部操作map,由于分段锁的原因,如果我们操作的元素恰好是方法操作的元素,或者跟方法操作的元素落在同一个segment,那么就会出现死锁的情况,conputeIfAbsent持有node节点,方法内部操作map时,需要申请node节点,从而导致死循环
13. Netty开启内存泄漏检测
Netty提供了4个检测等级,不同的级别采样率不同,开销也不一样,用户可以根据实际情况选择合适的级别。
| 检测等级 | 说明 |
|---|---|
| DISABLED | 禁用检测 |
| SIMPLE(默认) | 简单检测,少量的采样,不报告泄漏的位置 |
| ADVANCED | 高级检测,少量的采样,会报告泄漏的位置 |
| PARANOID | 偏执检测,100%采样,会报告泄漏的位置 |
通过设置JVM参数-Dio.netty.leakDetection.level=PARANOID来调整检测等级。
14. jvm性能监控工具
14.1 jps
虚拟机进程查看工具,查看虚拟机中正在运行的所有Java进程以及进程ID
jps
14.2 jstat
虚拟机统计信息监视工具
jstat -gc 进程id 监控时间 监控次数 jstat -gc 24096 2s 3 // 表示监控pid为24096的Java进程,每隔2秒输出gc信息,总共输出3次信息
14.3 jinfo
用于查看正在运行的Java程序的扩展参数(可以通过System.getProperties()获取的参数,也就是运行时-D参数)
jinfo pid // 查看所有参数信息 jinfo -flag [+|-]name pid // 启用或者禁用某些参数 jinfo -flag name=value pid // 修改指定参数的值
14.4 jmap
Java内存映射工具(jdk9及以上被jhsdb jmap代替),用于查看JVM内存状态
jmap pid jmap -heap pid // 查看heap使用情况 jmap -histo[:alive] pid // 查看heap直方图,包括类名,对象数量,对象占用大小,alive则只统计存活对象信息
14.5 jhat
虚拟机堆转储快照分析工具,对堆进行离线分析的工具,可以对不同虚拟机中导出的heap文件进行分析
14.6 jstack
Java堆栈跟踪工具,jstack用于打印出给定的hava进程ID或core file或远程调试服务的Java堆栈信息
15. CompletableFuture
CompletableFuture与执行线程的关系,如果不传递线程池,ConpletableFuture默认在当前线程中执行,意思是CompletableFuture在handle、whenComplete等方法中,触发CompletableFuture完成的线程,继续执行handle、whenComplete等方法
16. @SuppressWarning
@SuppressWarning 注解的主要作用就是抑制编译时期所产生的警告,从而提高程序的可读性,可用的属性如下:
-
all,抑制所有警告
-
boxing,抑制与封装/拆装作业相关的警告
-
cast,抑制与强制转型作业相关的警告
-
dep-ann,抑制与淘汰注释相关的警告
-
deprecation,抑制与淘汰的相关警告
-
fallthrough,抑制与switch陈述式中遗漏break相关的警告
-
finally,抑制与未传回finally区块相关的警告
-
hiding,抑制与隐藏变数的区域变数相关的警告
-
incomplete-switch,抑制与switch陈述式(enum case)中遗漏项目相关的警告
-
javadoc,抑制与javadoc相关的警告
-
nls,抑制与非nls字串文字相关的警告
-
null,抑制与空值分析相关的警告
-
rawtypes,抑制与使用raw类型相关的警告
-
resource,抑制与使用Closeable类型的资源相关的警告
-
restriction,抑制与使用不建议或禁止参照相关的警告
-
serial,抑制与可序列化的类别遗漏serialVersionUID栏位相关的警告
-
static-access,抑制与静态存取不正确相关的警告
-
static-method,抑制与可能宣告为static的方法相关的警告
-
super,抑制与置换方法相关但不含super呼叫的警告
-
synthetic-access,抑制与内部类别的存取未最佳化相关的警告
-
sync-override,抑制因为置换同步方法而遗漏同步化的警告
-
unchecked,抑制与未检查的作业相关的警告
-
unqualified-field-access,抑制与栏位存取不合格相关的警告
-
unused,抑制与未用的程式码及停用的程式码相关的警告
-
UnusedReturnValue,抑制函数返回值未使用的警告
17. Consul 启动
consul 启动时,报下面错误:
==> Starting Consul agent...
Version: '1.10.1'
Node ID: '4dac0fbc-1b60-3ded-6597-c9777634ee24'
Node name: 'Nxxx'
Datacenter: 'dc1' (Segment: '<all>')
Server: true (Bootstrap: false)
Client Addr: [127.0.0.1] (HTTP: 8500, HTTPS: -1, gRPC: 8502, DNS: 8600)
Cluster Addr: 127.0.0.1 (LAN: 8301, WAN: 8302)
Encrypt: Gossip: false, TLS-Outgoing: false, TLS-Incoming: false, Auto-Encrypt-TLS: false
==> Log data will now stream in as it occurs:
2021-08-04T16:24:10.270+0800 [INFO] agent.server.raft: initial configuration: index=1 servers="[{Suffrage:Voter ID:4dac0fbc-1b60-3ded-6597-c9777634ee24 Address:127.0.0.1:8300}]"
2021-08-04T16:24:10.279+0800 [INFO] agent.server.raft: entering follower state: follower="Node at 127.0.0.1:8300 [Follower]" leader=
2021-08-04T16:24:10.280+0800 [INFO] agent.server.serf.wan: serf: EventMemberJoin: N80261252.dc1 127.0.0.1
2021-08-04T16:24:10.287+0800 [INFO] agent.server: shutting down server
2021-08-04T16:24:10.287+0800 [WARN] agent.server.serf.wan: serf: Shutdown without a Leave
2021-08-04T16:24:10.287+0800 [WARN] agent.server: error removing WAN area: error="area ID "wan" does not exist"
2021-08-04T16:24:10.287+0800 [ERROR] agent: Error starting agent: error="Failed to start Consul server: Failed to start LAN Serf: Failed to create memberlist: Could not set up network transport: failed to obtain an address: Failed to start TCP listener on "127.0.0.1" port 8301: listen tcp 127.0.0.1:8301: bind: An attempt was made to access a socket in a way forbidden by its access permissions."
2021-08-04T16:24:10.288+0800 [INFO] agent: Exit code: code=1
原因是监控软件winrdlv3进程占用端口,解决办法是修改consul启动端口,可通过配置文件方式实现,配置文件内容如下:
{
"ports":{
"server":8300,
"serf_lan":9301,
"serf_wan":9302,
"http":8500,
"dns":8600
}
}
启动命令如下:
consul agent -server -bootstrap-expect 1 -config-dir D:\consul\ -dev
-config-dir:配置文件所在目录,会自动加载该目录下所有json和hcl文件,加载顺序配置文件为字母表顺序;可用配置多个此配置,从而加载多个文件夹,子文件夹的配置不会被加载。
18. HTTP2
HTTP2 采用二进制格式传输数据,HTTP 1.X采用文本格式传输数据,这一段话是什么意思?(直接抓包看下)
19. Git 修改提交记录(message、author、email等)
最近在开发开源项目时,遇到一个问题,在云桌面内部开发,author 以及 email 等忘记修改为公司账号,因此提交记录里面含有私人账号信息,不符合公司要求,因此需要将云桌面内部的多次提交进行修改,修改 author 以及 email ,下面是修改的几种方法:
19.1 修改最近一次提交
通过指令 git commit --amend --author "Iron <iron.yehong@outlook.com>" --no-edit 可以修改最近一次提交的内容,其中 --author 表示修改 author 信息,如果想修改 message 的话,可以使用 --message 来修改
19.2 依次修改多次提交信息
这种方法需要使用到指令 git rebase -i ,使用该指令可以修改最近多次的提交,后面可以跟上最近提交的次数 HEAD~n , 或者跟上某次提交的 SHA-1 值,如下:
git rebase -i HEAD~2 git rebase -i e1adc8ccddbdb8a8eae03553358b6918889490fc
上述指令,前者表示对最近两次提交进行修改,后者表示对 e1adc8ccddbdb8a8eae03553358b6918889490fc 这次提交(不包含该次提交) 到最新提交(包含最新提交)之间所有提交进行修改,上述指令运行后,出现如下界面:
pick a4959eb Modify README pick 5e10451 Add Test file # Rebase 1bd28ff..5e10451 onto 1bd28ff (2 commands) # # Commands: # p, pick = use commit # r, reword = use commit, but edit the commit message # e, edit = use commit, but stop for amending # s, squash = use commit, but meld into previous commit # f, fixup = like "squash", but discard this commit's log message # x, exec = run command (the rest of the line) using shell # d, drop = remove commit # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # # However, if you remove everything, the rebase will be aborted. # # Note that empty commits are commented out
将最顶上两行的 pick 修改为 edit(这两行代表两次 commit),然后 wq 保存并退出,接下来依次使用上述修改最近一次 commit 信息的指令修改信息,每次修改完以后,执行指令 git rebase --continue 进行下一次修改,直到所有修改都完成,比如上面有两次 commit 需要进行修改,那么需要依次执行指令:
git commit --amend --author "Iron <iron.yehong@outlook.com>" --no-edit git rebase --continue git commit --amend --author "Iron <iron.yehong@outlook.com>" --no-edit git rebase --continue
注意,如果没有修改完成,git bash 当前分支会带有后缀(分数),表示修改到第几次了,全部修改完以后,次数消失
19.3 批量修改
如果需要修改的 commit 过多,那么可以使用指令 git filter-branch 进行范围修改,如下:
git filter-branch --commit-filter "GIT_AUTHOR_NAME='Iron'; GIT_AUTHOR_EMAIL='iron.yehong@outlook.com'"
其中,--commit-filter 指的是提交过滤器,即对提交内容进行修改。同级的参数还有 --tree-filter 、--env-filter 等。如上命令的输出结果为:
Rewrite 5e10451f6149808b463c6cdf7bcd08a6f962608e (3/3) (7 seconds passed, remaining 0 predicted) Ref 'HEAD' was rewritten
即修订了每次提交中的用户名和邮箱,如果只想对符合条件的提交进行修订,则可参考如下脚本:
#!/bin/sh git filter-branch --commit-filter ' OLD_EMAIL="your-old-email@example.com" CORRECT_NAME="Your Correct Name" CORRECT_EMAIL="your-correct-email@example.com" if [ "$GIT_COMMITTER_EMAIL" = "$OLD_EMAIL" ] then export GIT_COMMITTER_NAME="$CORRECT_NAME" export GIT_COMMITTER_EMAIL="$CORRECT_EMAIL" fi' HEAD
该脚本运行完毕会对匹配成功的 commit 修改其 author 和 email,但是我在使用该方式时,报错了,因此选择了上面第二种方式
19.4 push
在修改完 commit 信息以后,只是本地修改,远程仓库中的 commit 信息认为发生变化,此时需要执行以下指令强制更新信息
git push origin --force --all
执行完以后,可以看到远程 commit 信息已经修改成功
21. 重载问题
在跨语言的情况中,重载是一个问题,Java中支持方法的重载,但是很多其它语言根本就不支持该特性,比如 GO 语言中方法不允许重载,这会造成一定的问题,比如 dubbo 协议能够解决重载问题,但是如果将 dubbo 协议转换为 HTTP 协议,这时就面临一个问题,我的一个 url ,该如何表示两个重载的方法,唯一解决办法就是将重载的信息加到 url 中,这会造成 url 复杂性增大
22. protoc报错
在使用 protoc 命令生成go文件时,报下面错误:
PS C:\Users\xxxx\go\src\go-micro-v2\proto> protoc --go_out=. --micro_out=. .\order.proto protoc-gen-go: unable to determine Go import path for "order.proto" Please specify either: • a "go_package" option in the .proto source file, or • a "M" argument on the command line. See https://developers.google.com/protocol-buffers/docs/reference/go-generated#package for more information. --go_out: protoc-gen-go: Plugin failed with status code 1.
原因是protoc-gen-go的不同版本兼容性问题。
解决办法: 一是,在proto文件中加上option go_package = "/proto"; 二是采用老版本的proto-gen-go,使用命令切换为v1.3.2版本 go get -u github.com/golang/protobuf/protoc-gen-go@v1.3.2
26. go get 访问私有仓库
go get默认采用的https下载项目依赖,而私有仓库一般采用的ssh key的方式鉴权,所以直接使用go get会出现https鉴权失败的问题,解决办法有两种。
1. 将https替换为ssh
这种方式适合在自己的电脑上使用。
让git执行 git clone https://gitlab.com/xx.git时,自动替换为执行git clone git@gitlab.etsus.net:xx.git,需要执行如下命令:
git config --global url."git@gitlab域名:".insteadof "https://gitlab域名/"
2. 利用Gitlab 的 Access Token鉴权
在有些情况下,比如对于编译服务器,可能采用ssh key的方式权限太大,可以采用Access Token的方式来解决问题。
进入Gitlab—>Settings—>Access Tokens,然后创建一个personal access token,这里权限最好选择只读(read_repository)。
然后让git在执行 git clone https://gitlab.com/xx.git时,自动替换为执行git clone https://oauth2:${your_access_token}@gitlab.com/xx.git,需要执行如下命令:
git config --global url."https://oauth2:${your_access_token}@gitlab域名".insteadOf "https://gitlab域名"
将${your_access_token}替换为自己的 token
3. GOPROXY的导致的问题
在完成了上面的配置以后,还要看当前是否配置了GOPROXY,如果配置了GOPROXY,会导致私有库不可用。因为GOPROXY会导致go get所有的请求通过PROXY下载,最终导致鉴权失效。因此需要配置GOPRIVATE来指定私有库,配置到GOPRIVATE中的地址将不会转发到GOPROXY中了。
命令:
go env -w GOPRIVATE=gitlab域名
4. http导致的问题
需要运行在golang 1.14 版本及以上 go get默认采用的https,当我们的私有库是http的时候,需要利用GOINSECURE将https转为http。命令如下:
go env -w GOINSECURE=gitlab域名
27. go module项目引用含有subGroup的项目
由于 gitlab 的版本问题,如果使用了 subgroup,则不能正确返回 meta tag。也就是说,我们使用的 gitlab 版本只支持一层 namespace 下建的项目,如果使用了两层namespace就会拉取不到仓库依赖。问题原因参见"go get" fails for subgroups,Go get fails with the usage of subgroups,cmd/go: get fails on gitlab subgroups due to go-import meta tags referring to nonexistent repos,解决办法如下:
1. 迁移项目,将项目整理到一个namespace下。
该方法是最简单的方法,不需要用户进行其他操作就可以解决问题
2. 在go.mod中使用replace替换。
replace ( gitlab.company.com/aa/bb/xlib => gitlab.company.com/aa/bb/xlib.git v1.0.0 )
该方法需要用户进行特别的配置,不可取,并且该方法无法引用 master 以外分支的代码,有其局限性(或者是我的使用方式不当造成的?)
3. 修改go源码(不可取)
go/src/cmd/go/internal/modload/query.go
4. 在gitlab下创建.netrc文件
windows 下创建 _netrc 文件,用于权限校验,具体设置可参见Git - How to use .netrc file on Windows to save user and password
以上四种解决方案,除了第一种以外,其他三种解决方案都对用于代码或者对于用户环境有侵入性,不建议使用,建议使用第一种方案,将仓库从 subgroups 中移出来,整理到一个 namespace 下进行管理。
28. maven批量修改版本号
新版本开发时,我们需要修改一下项目中pom.xml的版本号。但是如果这个maven项目有很多的子模块项目,那么一个个手动的去改就显得费时费力又繁琐。还好,maven为我们提供了以下三个命令(需要进入顶级pom所在的目录)来帮助我们解决这个问题。
设置新的版本号 mvn versions:set -DnewVersion=1.1.3 当新版本号设置不正确时可以撤销新版本号的设置 mvn versions:revert 确认新版本号无误后提交新版本号的设置 mvn versions:commit
29. 守护线程
Java中线程分为守护线程和用户线程,新建线程默认为用户线程,当程序中所有用户线程都执行完毕,此时不管守护线程是否执行完毕,程序都结束。也就是说守护线程依赖于用户线程而存在。
30. 首次请求慢50ms(类加载或者JIT导致)
restlight今天遇到一个问题,项目启动后,首次请求会比后续请求慢50ms左右(IDEA启动),如果通过Java -jar启动可能会更慢,超过100ms,这个问题一般是由于类加载导致的,比如restlight中,初次请求会导致Netty相关的类被加载,从而导致了首次启动时间的损耗,除了类加载,JIT也会导致时间损耗不同,JIT会对热点代码进行编译,编译成机器码,不用通过解释器解释执行,可以直接执行,从而能够减少调用耗时,但是该功能需要代码被频繁访问,比如一段时间内被访问上千次才会对该部分代码进行JIT。
解决办法是服务预热,在框架启动后对外提供服务前,框架自己先调用一下接口,这样可以去除由于类加载导致的损耗。至于JIT问题,可以预热需要JIT的方法。
31. Comparable和Comparator的区别
Java 中的两种排序方式:
-
Comparable 自然排序。(实体类实现)
-
Comparator 是定制排序。(无法修改实体类时,直接在调用方创建)
同时存在时采用 Comparator(定制排序)的规则进行比较。
对于一些普通的数据类型(比如 String, Integer, Double…),它们默认实现了Comparable 接口,实现了 compareTo 方法,我们可以直接使用。
而对于一些自定义类,它们可能在不同情况下需要实现不同的比较策略,我们可以新创建 Comparator 接口,然后使用特定的 Comparator 实现进行比较。
总结: Comparable是类内建的排序规则,一旦写好,不能改变,Comparator则是外部的排序规则,在集合等排序中,可以通过传入不同的Comparator实现类,在不改变集合类的排序规则的情况下,实现新的排序规则,即Comparable属于内建规则,Comparator属于外部规则,同时存在,以外部规则为主
32. redis和zk如何实现分布式锁,各自使用场景如何?
1. 为什么需要使用分布式锁?
单机场景下可以通过锁来控制并发,从而控制同步,保证多线程下操作的安全,但是在分布式系统中,项目多机部署,此时Java原生的锁(synchronized和ReentrantLock)就无法实现同步功能了,因为不同机器有不同JVM,Java原生锁无法跨JVM锁对象,这样就会出现多机情况下多线程安全问题,要解决这个问题,最简单的就是多个机器上代码锁住一个对象(竞争同一把锁),这个同一把锁也就是分布式锁了。
分布式锁的思路是:在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。
至于这个“东西”,可以是 Redis、Zookeeper,也可以是数据库。
2. redis实现分布式锁
加锁
在 Redis 中设置一个值表示加了锁,然后释放锁的时候就把这个 Key 删除
-
一定要用 SET key value NX PX milliseconds 命令。如果不用,先设置了值,再设置过期时间,这个不是原子性操作,有可能在设置过期时间之前宕机,会造成死锁(Key 永久存在)
-
Value 要具有唯一性。这个是为了在解锁的时候,需要验证 Value 是和加锁的一致才删除 Key。
// 加锁
public static boolean tryGetDistributedLock(Jedis jedis,String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
}
这个set()方法一共有五个形参:
第一个为key,我们使用key来当锁,因为key是唯一的。
第二个为value,我们传的是requestId,很多童鞋可能不明白,有key作为锁不就够了吗,为什么还要用到value?原因就是,通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。requestId可以使用UUID.randomUUID().toString()方法生成。
第三个为nxxx,这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作;
第四个为expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
第五个为time,与第四个参数相呼应,代表key的过期时间。
总的来说,执行上面的set()方法就只会导致两种结果:
-
当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。
-
已有锁存在,不做任何操作。
解锁
// 解锁
public static void wrongReleaseLock1(Jedis jedis, String lockKey) {
jedis.del(lockKey);
}
这段代码的问题是容易导致误删,假如某线程成功得到了锁,并且设置的超时时间是30秒。如果某些原因导致线程A执行的很慢很慢,过了30秒都没执行完,这时候锁过期自动释放,线程B得到了锁。 随后,线程A执行完了任务,线程A接着执行del指令来释放锁。但这时候线程B还没执行完,线程A实际上删除的是线程B加的锁。
怎么避免这种情况呢?可以在del释放锁之前做一个判断,验证当前的锁是不是自己加的锁。 至于具体的实现,可以在加锁的时候把当前的线程ID当做value,并在删除之前验证key对应的value是不是自己线程的ID。
public static void wrongReleaseLock2(Jedis jedis, String lockKey, String requestId) {
// 判断加锁与解锁是不是同一个客户端
if (requestId.equals(jedis.get(lockKey))) {
// 若在此时,这把锁突然不是这个客户端的,则会误解锁
jedis.del(lockKey);
}
}
但是,这样做又隐含了一个新的问题,判断和释放锁是两个独立操作,不是原子性。 解决方案就是使用lua脚本,把它变成原子操作,代码如下:
public class RedisTool {
private static final Long RELEASE_SUCCESS = 1L;
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
续约问题
上面加锁最后的代码就完美了吗?假想这样一个场景,如果过期时间为30S,A线程超过30S还没执行完,但是自动过期了。这时候B线程就会再拿到锁,造成了同时有两个线程持有锁。这个问题可以归结为”续约“问题,即A没执行完时应该过期时间续约,执行完成才能释放锁。怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续约”。 其实,后面解锁出现的删除非自己锁,也属于“续约”问题。
集群同步延迟问题
用于redis的服务肯定不能是单机,因为单机就不是高可用了,一量挂掉整个分布式锁就没用了。 在集群场景下,如果A在master拿到了锁,在没有把数据同步到slave时,master挂掉了。B再拿锁就会从slave拿锁,而且会拿到。又出现了两个线程同时拿到锁。 基于以上的考虑,Redis 的作者也考虑到这个问题,他提出了一个 RedLock 的算法。 这个算法的意思大概是这样的:假设 Redis 的部署模式是 Redis Cluster,总共有 5 个 Master 节点。 通过以下步骤获取一把锁:
-
获取当前时间戳,单位是毫秒。
-
轮流尝试在每个 Master 节点上创建锁,过期时间设置较短,一般就几十毫秒。
-
尝试在大多数节点上建立一个锁,比如 5 个节点就要求是 3 个节点(n / 2 +1)。
-
客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了。
-
要是锁建立失败了,那么就依次删除这个锁。
-
只要别人建立了一把分布式锁,你就得不断轮询去尝试获取锁。
但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确。 这个问题的根本原因就是redis的集群属于AP,分布式锁属于CP,用AP去实现CP是不可能的。
Redisson
Redisson是架设在Redis基础上的一个Java驻内存数据网格(In-Memory Data Grid)。充分的利用了Redis键值数据库提供的一系列优势,基于Java实用工具包中常用接口,为使用者提供了一系列具有分布式特性的常用工具类。 Redisson通过lua脚本解决了上面的原子性问题,通过“看门狗”解决了续约问题,但是它应该解决不了集群中的同步延迟问题。
总结
redis分布式锁的方案,无论用何种方式实现都会有续约问题与集群同步延迟问题。总的来说,是一个不太靠谱的方案。如果追求高正确率,不能采用这种方案。 但是它也有优点,就是比较简单,在某些非严格要求的场景是可以使用的,比如社交系统一类,交易系统一类不能出现重复交易则不建议用。
3. zk实现分布式锁(公平可重入锁,临时顺序节点+监听)
ZooKeeper的临时顺序节点,天生就有一副实现分布式锁的胚子。
-
ZooKeeper的每一个节点,都是一个天然的顺序发号器。 在每一个节点下面创建临时顺序节点(EPHEMERAL_SEQUENTIAL)类型,新的子节点后面,会加上一个次序编号,而这个生成的次序编号,是上一个生成的次序编号加一。 例如,有一个用于发号的节点“/test/lock”为父亲节点,可以在这个父节点下面创建相同前缀的临时顺序子节点,假定相同的前缀为“/test/lock/seq-”。第一个创建的子节点基本上应该为/test/lock/seq-0000000000,下一个节点则为/test/lock/seq-0000000001,依次类推,如下所示:
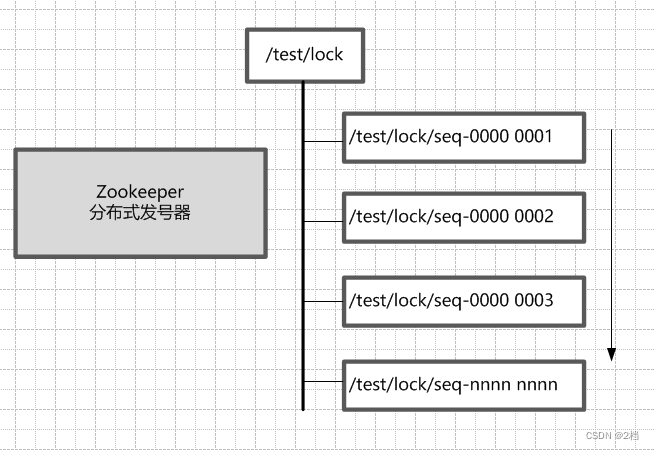
-
ZooKeeper节点的递增有序性,可以确保锁的公平 一个ZooKeeper分布式锁,首先需要创建一个父节点,尽量是持久节点(PERSISTENT类型),然后每个要获得锁的线程,都在这个节点下创建个临时顺序节点。由于ZK节点,是按照创建的次序,依次递增的。
为了确保公平,可以简单的规定:编号最小的那个节点,表示获得了锁。所以,每个线程在尝试占用锁之前,首先判断自己是排号是不是当前最小,如果是,则获取锁。
-
ZooKeeper的节点监听机制,可以保障占有锁的传递有序而且高效
每个线程抢占锁之前,先尝试创建自己的ZNode。同样,释放锁的时候,就需要删除创建的Znode。创建成功后,如果不是排号最小的节点,就处于等待通知的状态。等谁的通知呢?不需要其他人,只需要等前一个Znode的通知就可以了。前一个Znode删除的时候,会触发Znode事件,当前节点能监听到删除事件,就是轮到了自己占有锁的时候。第一个通知第二个、第二个通知第三个,击鼓传花似的依次向后。
ZooKeeper的节点监听机制,能够非常完美地实现这种击鼓传花似的信息传递。具体的方法是,每一个等通知的Znode节点,只需要监听(linsten)或者监视(watch)排号在自己前面那个,而且紧挨在自己前面的那个节点,就能收到其删除事件了。 只要上一个节点被删除了,就进行再一次判断,看看自己是不是序号最小的那个节点,如果是,自己就获得锁。
另外,ZooKeeper的内部优越的机制,能保证由于网络异常或者其他原因,集群中占用锁的客户端失联时,锁能够被有效释放。一旦占用Znode锁的客户端与ZooKeeper集群服务器失去联系,这个临时Znode也将自动删除。排在它后面的那个节点,也能收到删除事件,从而获得锁。正是由于这个原因,在创建取号节点的时候,尽量创建临时znode
-
ZooKeeper的节点监听机制,能避免羊群效应(惊群)
ZooKeeper这种首尾相接,后面监听前面的方式,可以避免羊群效应。所谓羊群效应就是一个节点挂掉,所有节点都去监听,然后做出反应,这样会给服务器带来巨大压力,所以有了临时顺序节点,当一个节点挂掉,只有它后面的那一个节点才做出反应。
总结
优点:ZooKeeper分布式锁(如InterProcessMutex),能有效的解决分布式问题,不可重入问题,使用起来也较为简单。
缺点:ZooKeeper实现的分布式锁,性能并不太高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。大家知道,ZK中创建和删除节点只能通过Leader服务器来执行,然后Leader服务器还需要将数据同不到所有的Follower机器上,这样频繁的网络通信,性能的短板是非常突出的。
总之,在高性能,高并发的场景下,不建议使用ZooKeeper的分布式锁。而由于ZooKeeper的高可用特性,所以在并发量不是太高的场景,推荐使用ZooKeeper的分布式锁。
4. 总结
在目前分布式锁实现方案中,比较成熟、主流的方案有两种:
-
基于Redis的分布式锁
-
基于ZooKeeper的分布式锁
两种锁,分别适用的场景为:
-
基于ZooKeeper的分布式锁,适用于高可靠(高可用)而并发量不是太大的场景;
-
基于Redis的分布式锁,适用于并发量很大、性能要求很高的、而可靠性问题可以通过其他方案去弥补的场景。
总之,这里没有谁好谁坏的问题,而是谁更合适的问题。
33. HashMap
jdk8 及以上版本中 HashMap 底层数据结构为 Node 数组,TreeNode 为子类表示红黑树,其余为链表,当容量小于 64,即使数组中某个链表长度大于等 8,也不会触发链表转红黑树的操作,而是会进行扩容,当容量大于等于 64 时,如果某个链表长度大于 8,才会触发链表转红黑树
33.1 hash 的计算
如何计算 key 的 hash 值?
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Key hashcode 高 16 位和低 16 位进行异或
hash 这样计算的原因跟获取数组下标方式有关,计算一个 Key 在数组中的下表,直接将 Key 的 hash 值与数组长度 - 1 相与,结果就是该元素在数组中的下表,这也解释了为什么 HashMap 的数组长度一定要是 2 的幂次方,因为这样数组长度刚好可以作为掩码使用
但是这样问题就来了,如果我的 hash 值就是简单的 Key.hashcode,那么就算散列值再分散,要是只取最后几位(表示数组长度的位数),碰撞也会很严重,更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复,就无比蛋疼。
这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图,
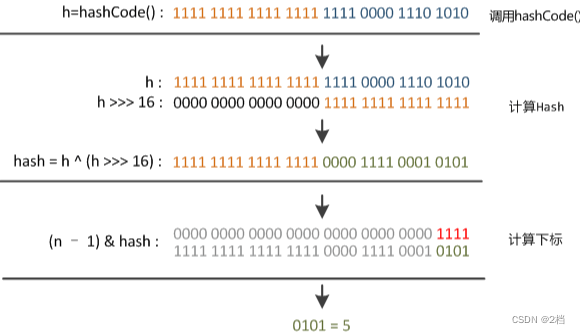
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位参杂了高位的部分特征,这样高位信息也变相保留了下来。因此在计算 Key 的 hash 值时需要使用扰动函数将 Key hashcode 的高 16 位和低 16 位进行异或来计算 hash 值。
33.2 resize(初始化或者扩容)
33.1 put 流程
-
通过hash方法计算hash码,计算过程为通过Key的hashcode方法得到h,将h右移16位跟h进行异或求得hash值
-
如果table为空(HahsMap底层是Node<K,V>数组——table)或者table长度为0,通过resize方法(初始化或者扩容)进行初始化,resize方法中流程为:
-
旧的cap大于0
-
如果旧的cap大于等于最大容量,修改threshold为最大整数
-
如果旧cap翻倍结果小于最大容量并且旧容量大于16,则将threshold翻倍
-
-
旧的threshold大于0,新cap就等于旧的threshold
-
否则新cao为16,新threshold为16*0.75=12
-
如果新的threshold为0
-
新cap小于最大cap并且新cap*loadfactory小于最大cap,那么新的threshold为新cap*loadfactory
-
否则新的新threshold为最大整型值
-
-
设置新的threshold,并且利用新的cap创建数组
-
如果旧数组为空,表示本次resize为初始化,直接返回新数组即可
-
如果旧数组不为空,那么需要将旧数组中元素搬迁到新数组中然后返回,遍历旧数组,遇到非空元素:
-
如果只有一个节点元素,那么该元素在新数组中位置为hash值和新容量-1相与
-
如果是链表,那么通过计算,将链表拆分为两个链表,链表中元素hash值和旧cap相与结果为0的组成一个low链表,剩余的组成另外一个high链表,结束后low链表下标位置不变,high链表下标位置变为旧位置+旧cap,注意,此处使用的是尾插法
-
如果是树节点,表明该下标元素为红黑树,那么此时通过红黑树的split方法搬迁节点,该方法中仍旧是首先按照hash值将树拆分为两个链表,然后根据链表长度,小于等于6的直接为链表,大于等于的转换为红黑树
-
-
-
通过hash值计算index((cap - 1) & hash),如果数组对应index上元素为null,那么直接根据hash、key、value创建一个新的节点放入数组
-
如果该index上已经有元素
-
如果头节点元素hash值和key的hash值相等并且头节点key和传入的key引用相等或者通过equals方法相等,那么传入的key和头节点key相等,新值覆盖旧值
-
如果为红黑树,走红黑树put流程添加元素
-
如果为链表,走链表流程添加元素,在此处,当key在原map中不存在,需要添加元素时(尾插法),如果添加后,链表长度大于等于8,那么将链表转换为红黑树(treeifyBin方法中如果当前容量大于64才转换为红黑树,否则会调用resize方法触发扩容)
-
在前面过程中,如果该key已经在map中存在,那表明我们只是更新值,不会涉及map的扩容,因此执行完后直接返回oldValue
-
否则size++,如果size大于threshold,调用resize方法进行扩容,最后返回null
-
比较规范的回答如下:
-
判断数组是否为空,为空进行初始化;
-
不为空,计算 k 的 hash 值,通过(n - 1) & hash计算应当存放在数组中的下标 index;
-
查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中;
-
存在数据,说明发生了hash冲突(存在二个节点key的hash值一样), 继续判断key是否相等,相等,用新的value替换原数据(onlyIfAbsent为false);
-
如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中;(如果当前节点是树型节点证明当前已经是红黑树了)
-
如果不是树型节点,创建普通Node加入链表中;判断链表长度是否大于 8并且数组长度大于64, 大于的话链表转换为红黑树;
-
插入完成之后判断当前节点数是否大于阈值,如果大于开始扩容为原数组的二倍。
33.2 如何实现HashMap的有序?
使用LinkedhashMap或者TreeMap,LinkedHashMap有序的原因是在HashMap中维护了一个head节点,该节点是一个双向链条的头节点,在put或者remove时会更新该链表的值,当我们遍历Map时,其实就是在遍历该双向链表
TreeMap更进一步,它是根据key排序的Map,排序规则为Comparable接口(自然排序)和Comparator接口(外部排序),在创建TreeMap时可以传入一个Comparator来指定排序规则,如果不传入,那么根据key的Comparable接口规则调用comparaTo方法进行排序,其内部通过红黑树来维护顺序,遍历时其实遍历的是该红黑树
33.3 扩容机制原理 → 初始容量、加载因子 → 扩容后的rehash(元素迁移)
-
一般情况下,当元素数量超过阈值时便会触发扩容(调用resize()方法)。
-
每次扩容的容量都是之前容量的2倍。
-
扩展后Node对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
JDK8中扩容机制如下:
-
空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
-
有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让 阈值 = 容量 x 加载因子 。(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!)
-
如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,加载因子0.75不变)
此外还有几个点需要注意:
-
首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;可见首次扩容可能会调用两次resize()方法。
-
不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
扩容时,要扩大空间,为了使hash散列均匀分布,原有部分元素的位置会发生移位。
33.4 插入后的数据顺序会变的原因是什么?
TreeMap中插入数据可能导致遍历顺序发生变化,这是因为TreeMap根据key的comparable以及创建时的comparator进行排序存储
33.5 HashMap在JDK1.7-JDK1.8都做了哪些优化?
-
存储结构由数组+链表转化为数组+链表+红黑树,时间复杂度由O(n)降为O(logn);
-
初始化方式集成到resize方法,没有单独的初始化方法
-
hash计算扰动处理7中需要9次,8中只需要2次
-
无冲突时都直接存放数组中,有冲突时7存放链表,8中可能是链表,可能是红黑树
-
插入方式由头插法改为尾插法,解决死链问题
-
扩容后元素搬迁位置计算,7中需要按照原有的计算index方式重新计算一遍,8中扩容后位置只可能是原位置或者是原位置+扩容容量
33.6 链表红黑树如何互相转换?阈值多少?
链表转换为红黑树阈值为8,红黑树转换为链表阈值为6
在hash函数设计合理的情况下,发生hash碰撞8次的几率为百万分之6,从概率上讲,阈值为8足够用;至于为什么红黑树转回来链表的条件阈值是6而不是7或9?因为如果hash碰撞次数在8附近徘徊,可能会频繁发生链表和红黑树的互相转化操作,为了预防这种情况的发生。
33.7 头插法改成尾插法为了解决什么问题?
解决死链问题,当多个线程同时put时,可能同时触发扩容操作,在多线程扩容HashMap过程中,在transforTo方法中可能出现一个线程在遍历一个Entry时,
34. ThreadLocal
ThreadLocal的作用主要是做数据隔离,填充的数据只属于当前线程,变量的数据对别的线程而言是相对隔离的,在多线程环境下,防止自己的变量被其它线程篡改。
Spring采用Threadlocal的方式,来保证单个线程中的数据库操作使用的是同一个数据库连接,同时,采用这种方式可以使业务层使用事务时不需要感知并管理connection对象,通过传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
当 threadlocal 使用完后,将栈中的 threadlocal 变量置为 null,threadlocal 对象下一次 GC 会被回收,那么 Entry 中的与之关联的弱引用 key 就会变成 null,如果此时当前线程还在运行,那么 Entry 中的 key 为 null 的 Value 对象并不会被回收(存在强引用),这就发生了内存泄漏,当然这种内存泄漏分情况,如果当前线程执行完毕会被回收,那么 Value 自然也会被回收,但是如果使用的是线程池呢,线程跑完任务以后放回线程池(线程没有销毁,不会被回收),Value 会一直存在,这就发生了内存泄漏。
35. 关于 CompletableFuture 的一些细节
CF 中基本所有方法都是异步的,并且异步方法的回调的执行线程是哪个线程 completable CF,那该线程就执行异步方法的回调(如果用户有指定特定的线程池,那回调线程会将回调操作交给该线程池来处理)
36. Go build 的一些细节
【问题】:go build xxx.go,其 build 过程是什么?当项目比较复杂,比如有很多模块时,build 如何执行?
37. 线程死亡自动调用 notifyAll 方法
线程在die的时候会自动调用自身的notifyAll方法,来释放所有的资源和锁。通知所有的等待线程继续执行。
38. agent 开发
运行 agent 两种方式:静态和动态
39. ThreadLocal
Thread 持有 ThreadLocalMap,ThreadLocalMap 中有个 Entry 数组,Entry 定义如下:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
如上,Entry 是一个 WeakReference,如果 ThreadLocal 的强引用被取消后,GC 时会自动回收掉 Entry 持有的 ThreadLocal,此时出现 key 为null,但是 value 仍有值得情况,如果不做处理,发生内存泄漏,因为该 value 永远无法被释放(除非线程结束执行),ThreadLocal 解决的办法是在 get、set、remove 方法调用时,会清理掉这些 key 为 null 的 Entry 所持有的 value。
ThreadLocal 效率低的问题是发生 hash 冲突时,采用的是线性再探测解决策略,时间复杂度 O(n),不管是 set 还是 get 都会出现冲突的情况
40. FastThreadLocal
FastThreadLocal 是 Netty 重新造的轮子,主要解决 ThreadLocal 效率底下的问题,在 ThreadLocal 中由于存在 hash 冲突导致时间复杂度变为 O(n),因此 FastThreadLocal 中主要解决 hash 冲突导致问题,解决办法是每个 FastThreadLocal 持有一个 index 变量,该变量记录该 FastThreadLocal 的 value 在数组中的存放位置,由于该 index 是由 InternalThreadLocalMap 来生成的,生成方式如下:
private static final AtomicInteger nextIndex = new AtomicInteger();
public static int nextVariableIndex() {
int index = nextIndex.getAndIncrement();
if (index >= ARRAY_LIST_CAPACITY_MAX_SIZE || index < 0) {
nextIndex.set(ARRAY_LIST_CAPACITY_MAX_SIZE);
throw new IllegalStateException("too many thread-local indexed variables");
}
return index;
}
由上可知,该 index 在项目中一定是唯一的
FastThreadLocalThread 持有 InternalThreadLocalMap,InternalThreadLocalMap 有一个 obejct 数组存放 FastThreadLocal 的 value,如下:
public final class InternalThreadLocalMap extends UnpaddedInternalThreadLocalMap {
// 如果 Thread 不是 FastThreadLocalThread,退化成从 ThreadLocal 中获取 InternalThreadLocalMap
private static final ThreadLocal<InternalThreadLocalMap> slowThreadLocalMap =
new ThreadLocal<InternalThreadLocalMap>();
private static final AtomicInteger nextIndex = new AtomicInteger();
// ...
public static final Object UNSET = new Object();
// 存放 value 的数组
private Object[] indexedVariables;
// ...
// 获取 InternalThreadLocalMap
public static InternalThreadLocalMap get() {
Thread thread = Thread.currentThread();
if (thread instanceof FastThreadLocalThread) {
return fastGet((FastThreadLocalThread) thread);
} else {
return slowGet();
}
}
private static InternalThreadLocalMap fastGet(FastThreadLocalThread thread) {
InternalThreadLocalMap threadLocalMap = thread.threadLocalMap();
if (threadLocalMap == null) {
thread.setThreadLocalMap(threadLocalMap = new InternalThreadLocalMap());
}
return threadLocalMap;
}
// 不是 FastThreadLocalThread,降级从 ThreadLocal 中获取
private static InternalThreadLocalMap slowGet() {
InternalThreadLocalMap ret = slowThreadLocalMap.get();
if (ret == null) {
ret = new InternalThreadLocalMap();
slowThreadLocalMap.set(ret);
}
return ret;
}
}
FastThreadLocal 回收机制:
-
自动,执行一个被FastThreadLocalRunnable wrap的Runnable任务,在任务执行完毕后会自动进行FastThreadLocal的清理
-
手动,FastThreadLocal和InternalThreadLocalMap都提供了remove方法,在合适的时候用户可以(有的时候也是必须,例如普通线程的线程池使用FastThreadLocal)手动进行调用,进行显示删除
-
自动,为当前线程的每一个FastThreadLocal注册一个Cleaner,当线程对象不强可达的时候,该Cleaner线程会将当前线程的当前ftl进行回收
netty推荐使用前两种方式,第三种方式需要另起线程,耗费资源,而且多线程就会造成一些资源竞争。
final class FastThreadLocalRunnable implements Runnable {
private final Runnable runnable;
private FastThreadLocalRunnable(Runnable runnable) {
this.runnable = ObjectUtil.checkNotNull(runnable, "runnable");
}
// 最主要的是重写 run 方法,run 执行完毕以后进行清理
@Override
public void run() {
try {
runnable.run();
} finally {
FastThreadLocal.removeAll();
}
}
static Runnable wrap(Runnable runnable) {
return runnable instanceof FastThreadLocalRunnable ? runnable : new FastThreadLocalRunnable(runnable);
}
}
java -XX:+PrintFlagsFinal -version | findstr "GC"
| 注解 | 作用对象 | 作用 | 可用属性 |
|---|---|---|---|
| @API | controller | 说明controller作用 | description |
| @ApiOperation | pathOperation | 说明pathOperation作用 | description,tags |
| @ApiParam | 参数 | 参数说明 | name、value、defaultValue、required、example |
| @ApiImplicitParams | pathOperation | 非对象参数描述 | name、value、required、defaultValue、example |
| @ApiResponse | pathOperation | 返回描述 | |
| @ApiResponses | pathOperation | 返回集 | |
| @ResponseHeader | pathOperation | 返回头描述 | |
| @ApiModel | object | 对象描述 | value、description |
| @ApiModelProperty | filed | 对象属性描述 | value、name、required、example |


















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









