







我们之前介绍了一些判别学习算法(discriminative learning algorithms),例如logistic regression,都是研究p(y|x),而接下来我们介绍生成学习算法(generative learning algorithms),是对p(y) 和p(x|y)进行建模,通过最大化联合似然来学习参数:
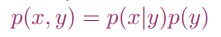
我们利用Bayes公式来将问题描述为:
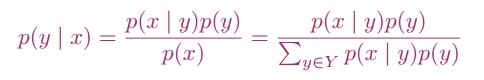
然而,我们不需要计算分母:
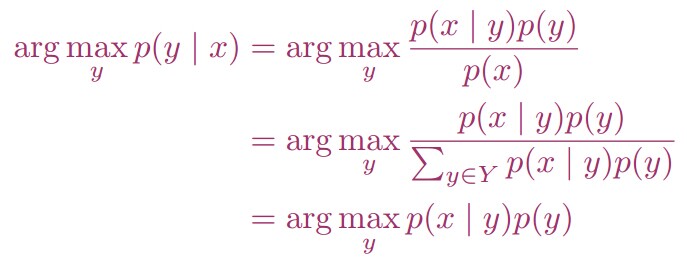
1. 高斯判别分析(Gaussian discriminant analysis)
这是我们要介绍的第一个生成学习算法。对此,我们有一个基本的假设,即p(x|y)服从多元高斯分布。首先,他是一个n维的分布,有两个参数给定:均值向量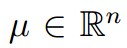
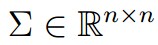
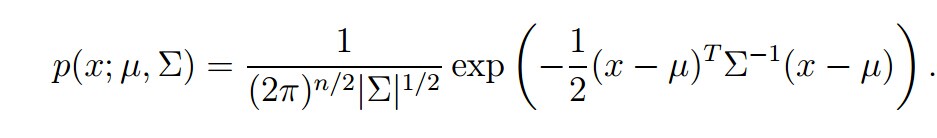
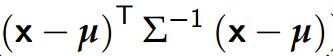
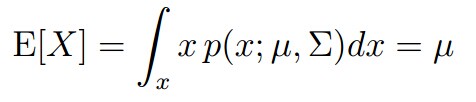
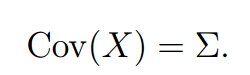
当n=1时,我们得到普通的正态分布:
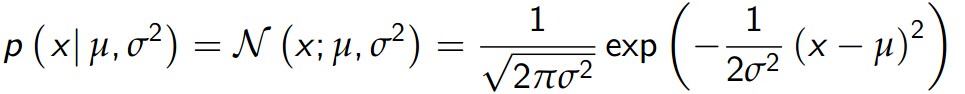
当n=2时,得到二维正态分布:
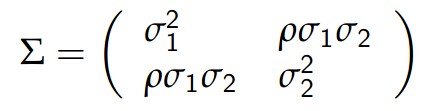
其中ρ = corr (X1 , X2)∈[ 1, 1]
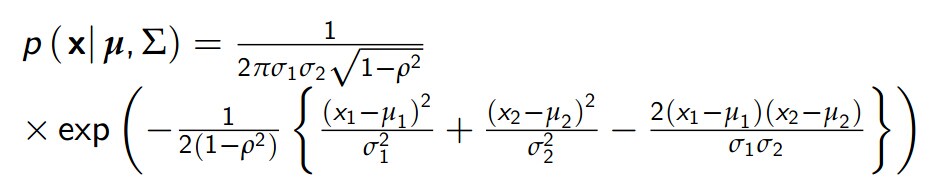
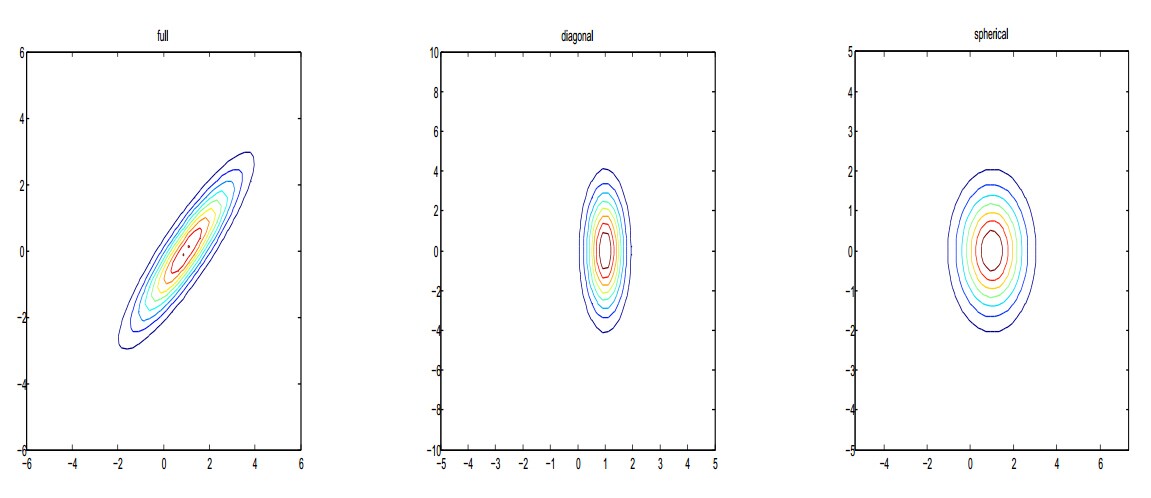
下面是不同协方差矩阵下的二维正态分布:
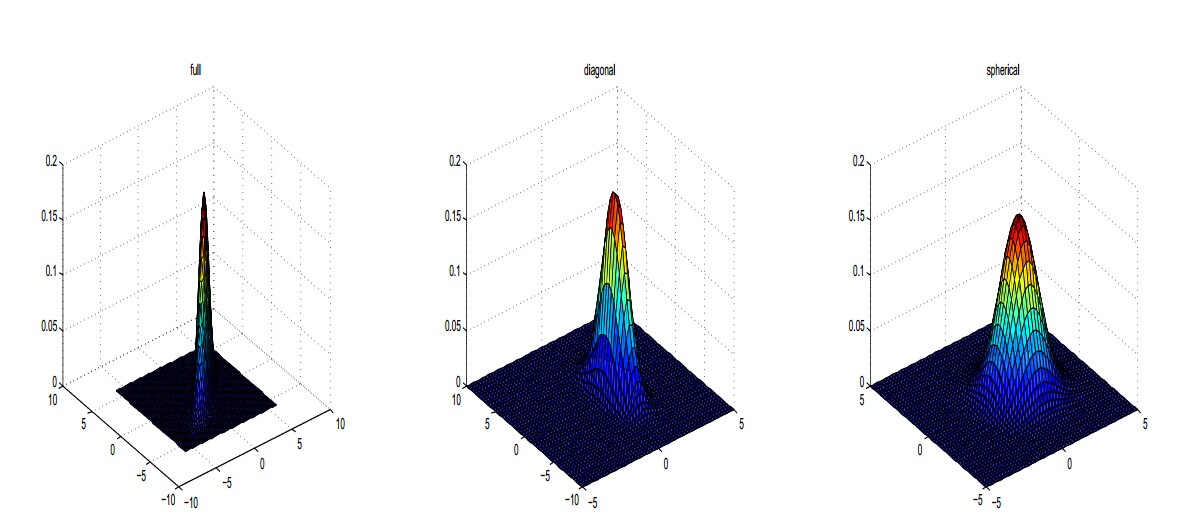
这里我们有一个疑问,为什么多维的高斯分布是椭圆形的呢?
如果我们绘制x,使得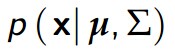
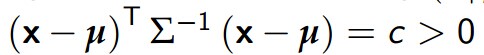
我们可以对Σ对角化:
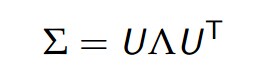
U是特征向量的正规矩阵,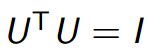
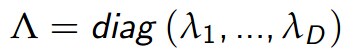
因此,有
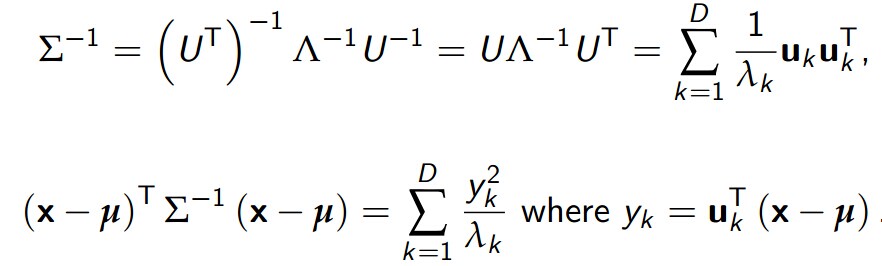
我们给出二维高斯分布对应的等高线:
多元高斯分布的性质:

我们假设我们的输入数据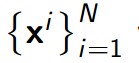
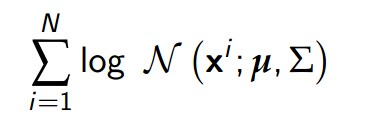
计算得到的极大似然估计的估计值
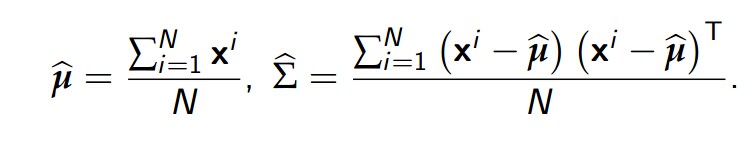
当我们面对一个分类问题,而输入特征x又是连续值的时候,我们可以用高斯判别分析(Gaussian Discriminant Analysis),我们对p(x|y)进行建模:
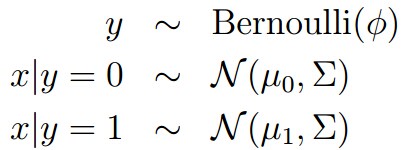
所以有:
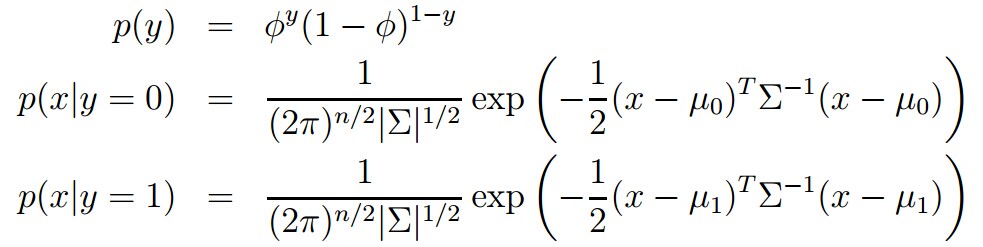
其似然估计的log形式为:
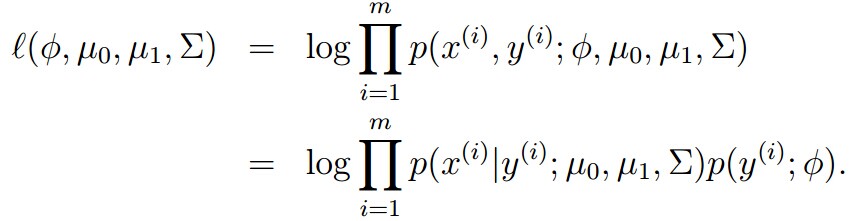
满足最大似然的参数形式为:
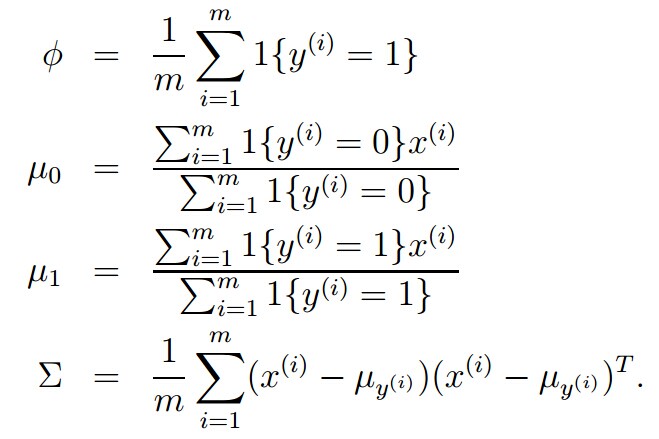
我们的算法做了下面的事情:
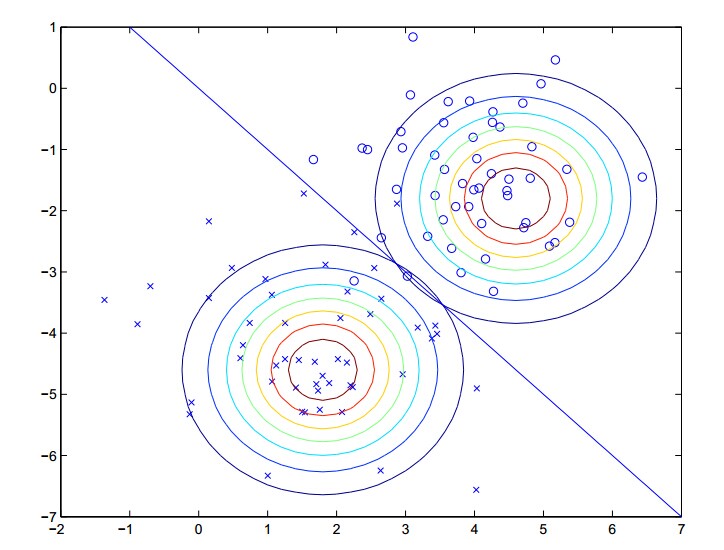
两个高斯分布拥有相同的Σ但是有不同的μ
GDA比logistic regression有更强的假设,是真包含的关系:
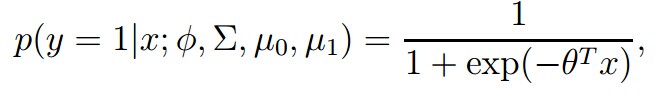
事实上,我们还有更一般的结论:
当x|y=1服从参数为η1的指数族分布,x|y=0服从参数为η0的指数族分布,这意味着p(y=1|x)是一个logistic函数。















 4945
4945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









