







来自caffeCN的一个简要的总结(http://caffecn.cn/?/question/255):
先上Paper列表:
- [v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
- [v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
- [v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
- [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
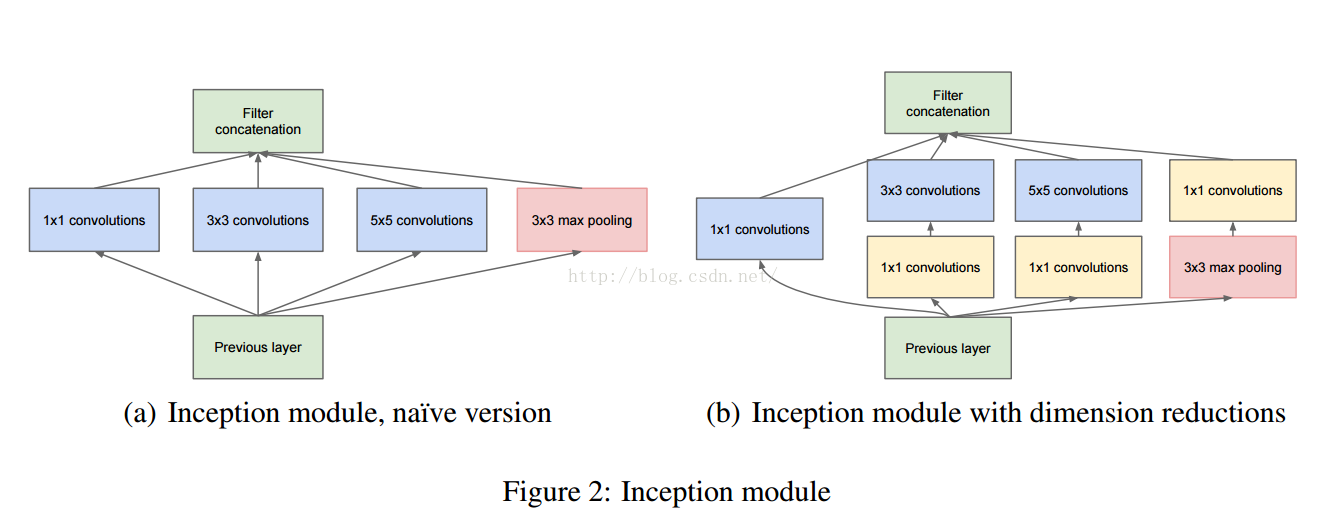
- Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
- v2的网络在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
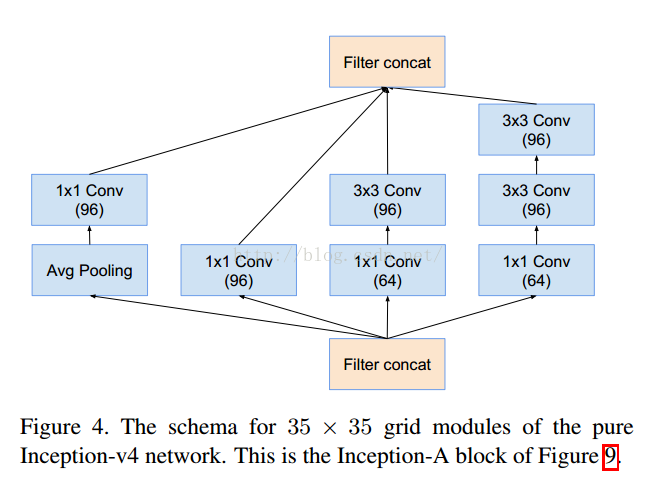
- v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块;
- v4研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能
=========================================================================================
基础单元:
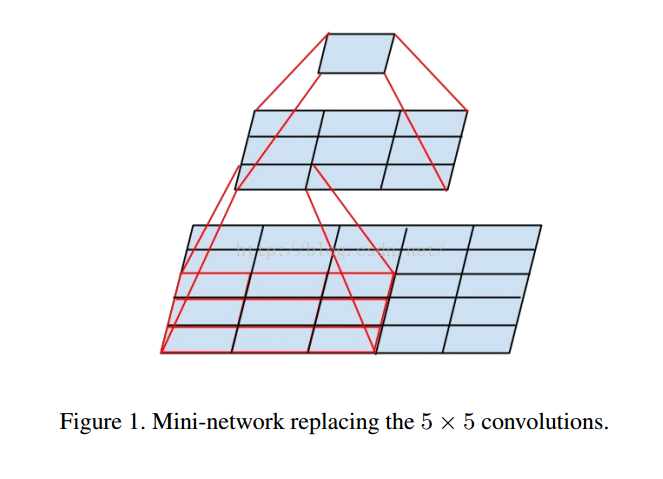
一个5x5的网格等于两个3x3的降级
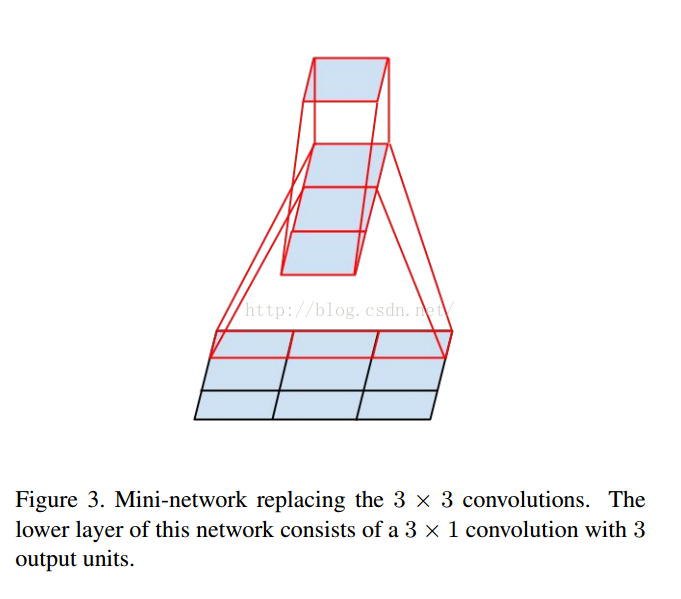
一个3x3的可以降维成一个由3x1的卷积的3个输出网络
35降维可以理解为1+9+25
17降维理解为每次降7个点,17=>11=>5
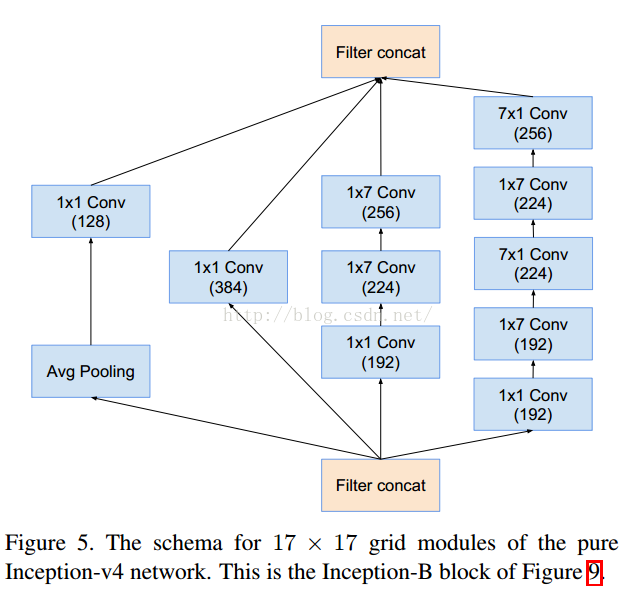
8降维可以理解为8=>6=>4=>2
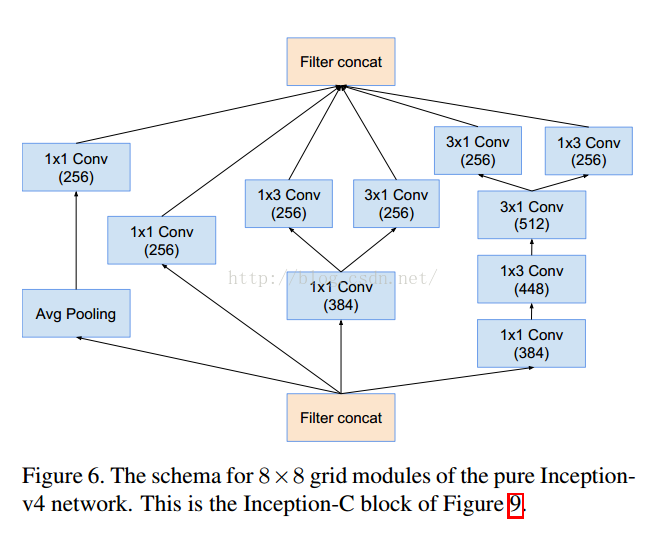
这个是V1对应的3个Inception结构,V2添加相应的BN就可以。
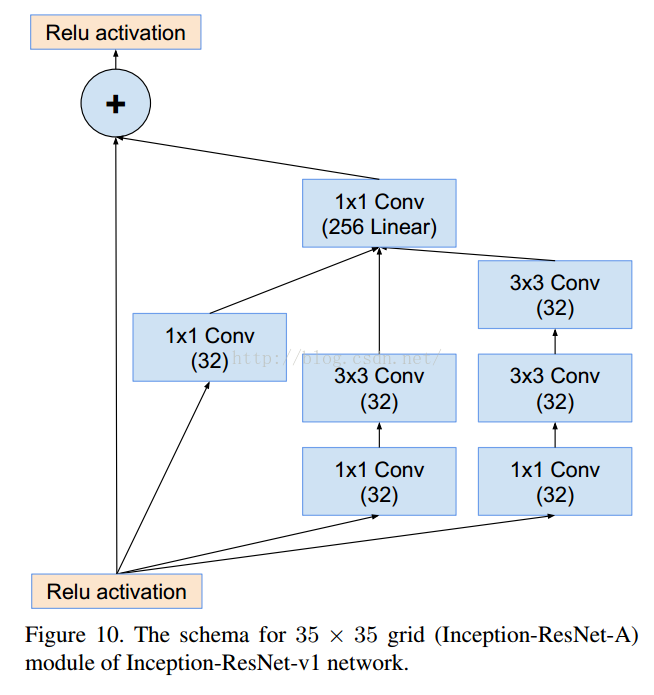
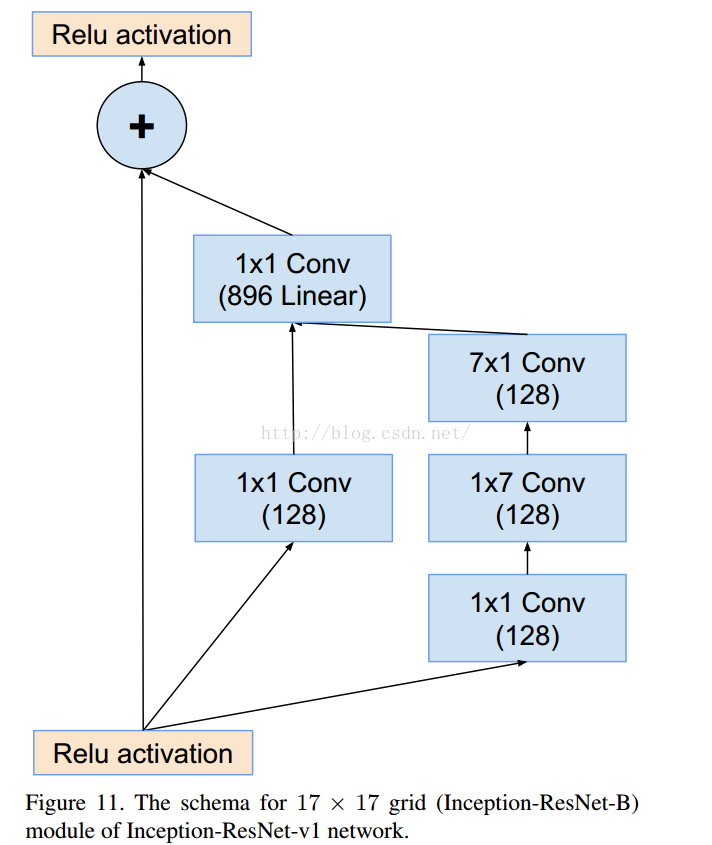
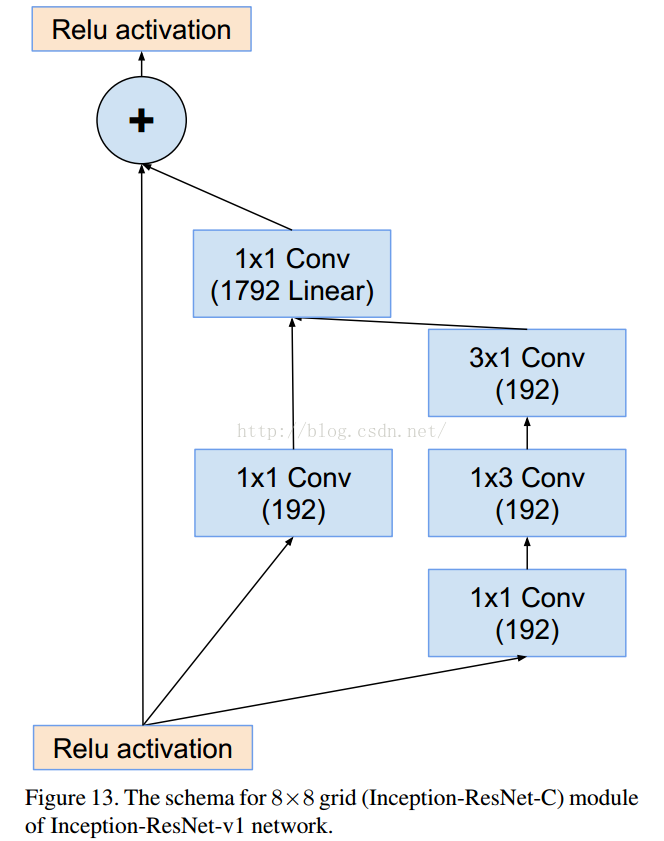
=========================================================================================
推荐参考博客:
http://blog.csdn.NET/cv_family_z/article/details/50789805
http://blog.csdn.Net/stdcoutzyx/article/details/51052847
Github上面有写好的这几个版本的Python实现:
https://github.com/soeaver/caffe-model
https://github.com/titu1994/Inception-v4
Keras框架是一个不错的框架,不仅框架安装方便,代码易修改,更重要的是API文档写的非常完美,个人推荐用Keras上手学习DL。















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









