







 本文介绍了如何利用Vim在大量HTML数据中高效地统计含有特定class的行数,提取所需用户信息,并通过正则表达式去除重复行进行排序。通过具体的Vim命令,如`%s/pattern/&/g`、`:g/pattern/d`和`:sort`等,实现了数据处理的便捷操作。
本文介绍了如何利用Vim在大量HTML数据中高效地统计含有特定class的行数,提取所需用户信息,并通过正则表达式去除重复行进行排序。通过具体的Vim命令,如`%s/pattern/&/g`、`:g/pattern/d`和`:sort`等,实现了数据处理的便捷操作。
最近在做基于Nutch网络爬虫爬取数据及一些数据处理的内容,涉及到在网络爬虫爬取到的HTML文件中提取一些用户名,之前想的一直是导入数据库再进行操作,从而忽略了强大的Vim。
问题来源:
根据网络爬虫爬取了一些淘宝BBS的一些数据,dump出一些HTML文件数据,一共120多万行,如下所示: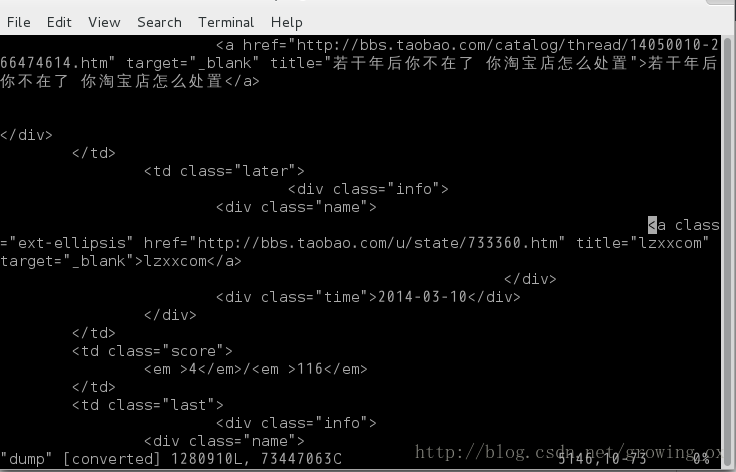
分析发现,含有用户名的具有统一的class=“ext-ellipasis”,想把如lzxxcom这样的用户全部提取出来。
实现思路:
1:先提取出ext-ellopsis所在的行。
2:根据正则表达式提取所需要的用户信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









