







 本文展示了如何利用JDBC连接Mysql数据库,并详细解释了如何通过代码统计指定关键词在某列中的出现次数。文章包含从原始数据展示到统计结果的呈现,以及关键代码的解析,如sql.next()和indexOf()的用法。
本文展示了如何利用JDBC连接Mysql数据库,并详细解释了如何通过代码统计指定关键词在某列中的出现次数。文章包含从原始数据展示到统计结果的呈现,以及关键代码的解析,如sql.next()和indexOf()的用法。
1:先看一下效果
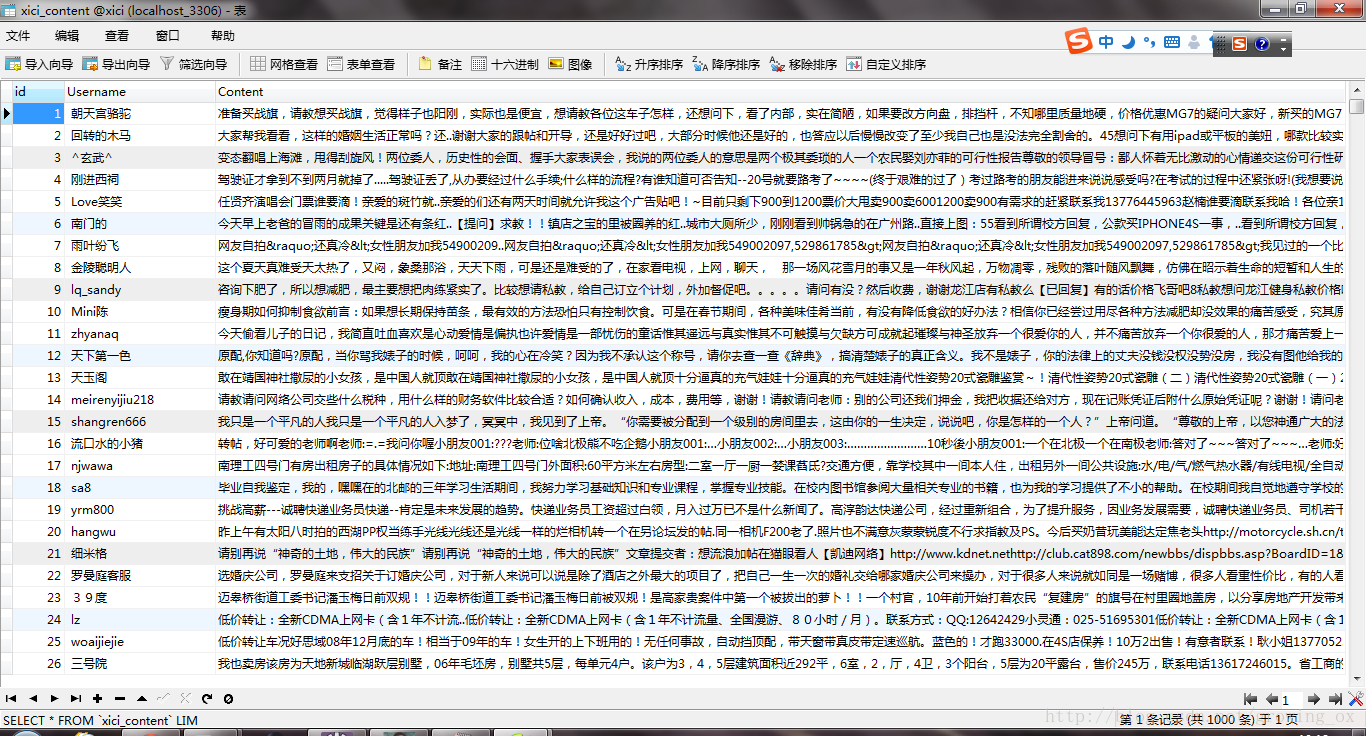
这个是原始内容数据:
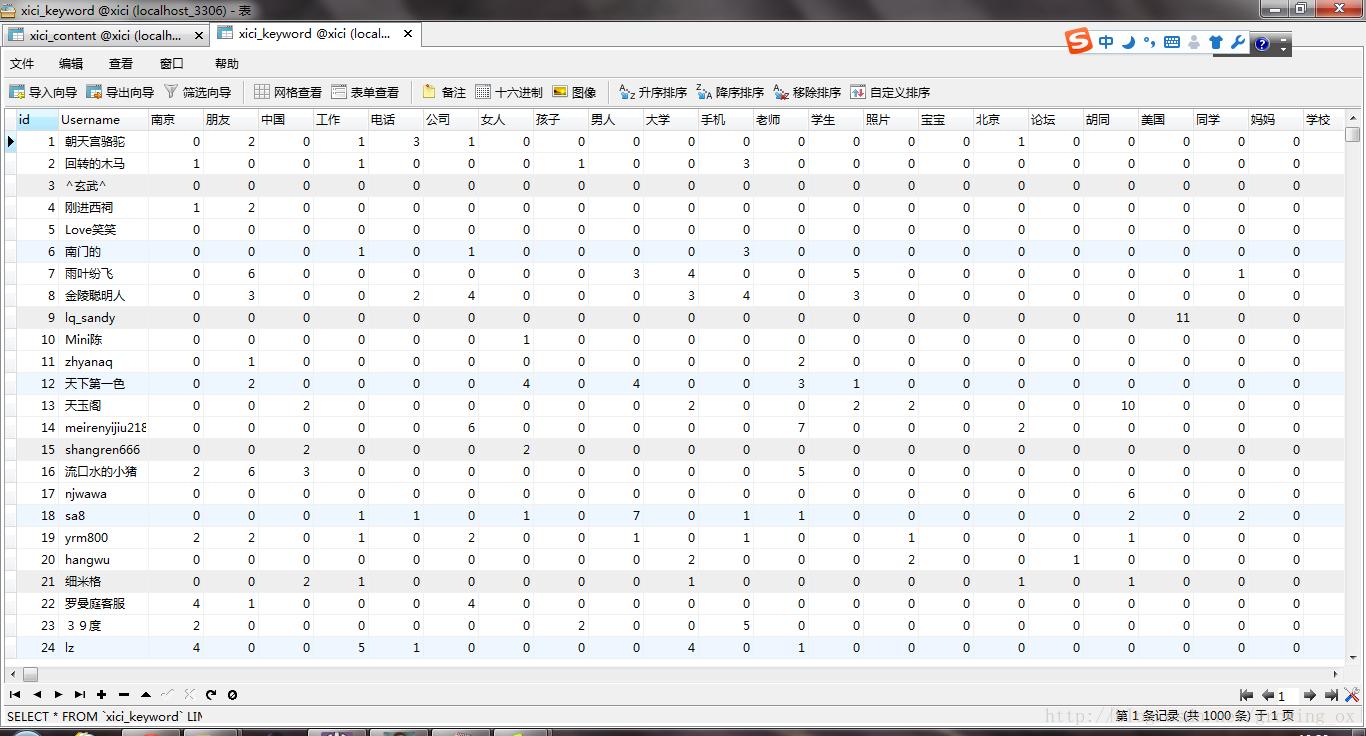
这个是统计后的数据显示,初始都为0
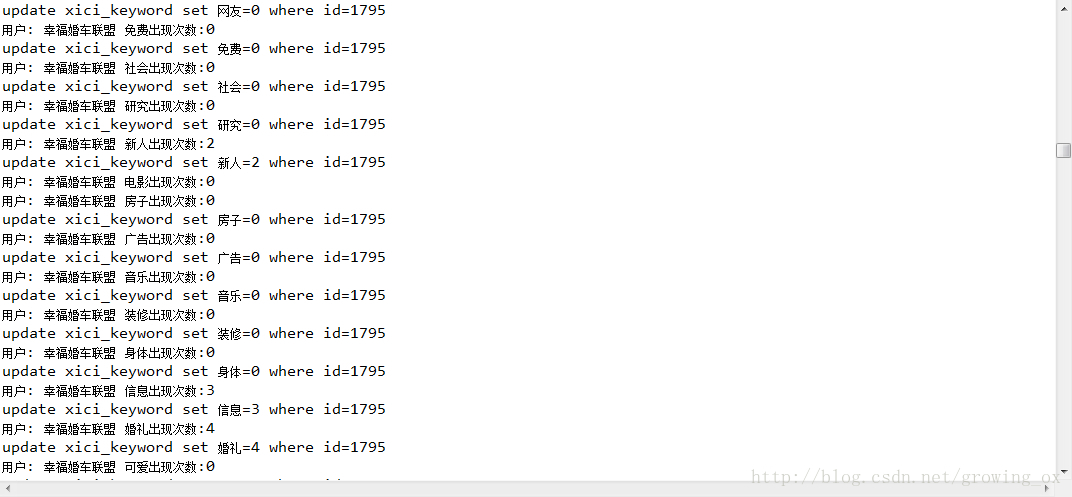
这个是执行过程中的状态:
2、贴出代码
import java.util.regex.Pattern;
import java.sql.*;
public class Statistics {
public static void main(String[] args) {
statistics();
}
public static Connection getConnection() throws SQLException,java.lang.ClassNotFoundException{
String url = "jdbc:mysql://localhost:3306/xici?useUnicode=true&characterEncoding=utf-8"; //连接xici数据库
Class.forName("com.mysql.jdbc.Driver"); //加载mysql支持包
String userName = "root"; //root用户
String password = "123"; //密码
Connection con = DriverManager.getConnection(url, userName, password);
return con;
}
public static void statistics(){
String str[]=new String[]{“内容1”,"内容二","内容三"}; //关键词输入
System.out.println("开始了");//个人习惯
try{
String s="select * from xici_content"; //选择数据库中一个表
Connection con = getConnection();
Statement sql=con.createStatement();
Statement sql1=con.createStatement();
ResultSet res=sql.executeQuery(s);
/*计算每个关键字在指定内容中出现的频率*/
while(res.next()){ //.next()见详解1
String contentString=res.getString("Content");
String id=res.getString("id");
//System.out.println(contentString); //供测试使用
int count=0,start=0,number=0; //初始化
System.out.println(str.length); //供测试
for(count=0;count<str.length;count++)
{
while ( contentString.indexOf(str[count],start)>=0 && start<contentString.length())//indexOf()见详解二
{
number++;
start=contentString.indexOf(str[count],start)+str[count].length();
}
if(number>=0)
{
System.out.println("用户:"+res.getString("Username")+" "+str[count]+"出现次数:"+number);
String si2="update xici_keyword set "+str[count]+"="+number+" where id="+id;
System.out.println(si2); //程序可视化
sql1.execute(si2); //执行sql语句
}
number=0;
start=0;
}
}
}
catch(java.lang.ClassNotFoundException e){ //捕获到ClassNotFoundException异常 ,输出异常信息
System.err.println("ClassNotFoundException:" + e.getMessage());
}
catch(SQLException ex){
System.err.println("SQLException:" + ex.getMessage()); //异常处理
}
System.out.println("一切都结束了"); //个人习惯
}
}3:代码讲解
详解1:sql.next()
依次使第123456789....行成为当前行.最常用语句。
详解2:indexOf()
public int indexOf(String str,int fromIndex)
官方解释:Returns the index within this string of the first occurrence of the specified substring, starting at the specified index. The integer returned is the smallest valuek for which:
返回关键词str出现的位置,为int型。fromIndex为起始位置。这里通过
start=contentString.indexOf(str[count],start)+str[count].length();
来增量改变start,从而统计这一条内容中所有的的关键词次数。
PS:注意编码格式,昨天汉字的编码格式不相符,耽误了不少时间找错。个人水平较低,也许会有错误,故作此记录。
官方解释:Returns the index within this string of the first occurrence of the specified substring, starting at the specified index. The integer returned is the smallest valuek for which:
返回关键词str出现的位置,为int型。fromIndex为起始位置。这里通过
start=contentString.indexOf(str[count],start)+str[count].length();
来增量改变start,从而统计这一条内容中所有的的关键词次数。
PS:注意编码格式,昨天汉字的编码格式不相符,耽误了不少时间找错。个人水平较低,也许会有错误,故作此记录。















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









