






首先说结论:
(1)443端口占用,网上解决方案一大堆。我这里就不废话了。
(2)80端口占用就比较麻烦了,其实说到底,占用该端口的肯定都是一些系统级的软件。如:sqlserver (微软的)、 IIS(微软的)、Apache、或者mysql、oracle 之类的数据库软件、或者虚拟机软件如VMWare等等占用的。
所以解决方案只有:
回忆。
回忆你电脑都装了哪些系统级的端口监听软件,然后百度搜对应的改端口方法。
我这里以sqlserver举例:
SQL Server占用的端口是80,而占用80端口的程序,正是其Reporting Services监听模块,所以我们找到其配置管理器,如下图:
(我这里以sql server 2008 R2举例)
1. 找到" Reporting Service 配置管理器 "
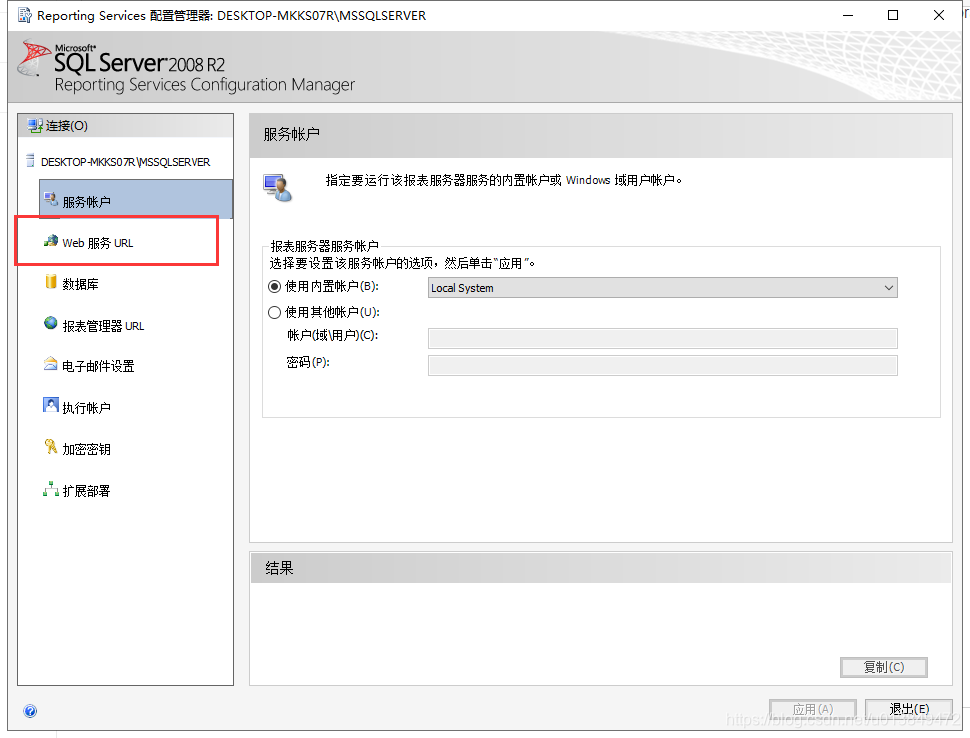
2.打开后看到如下图,我们选择 " web服务url配置 "
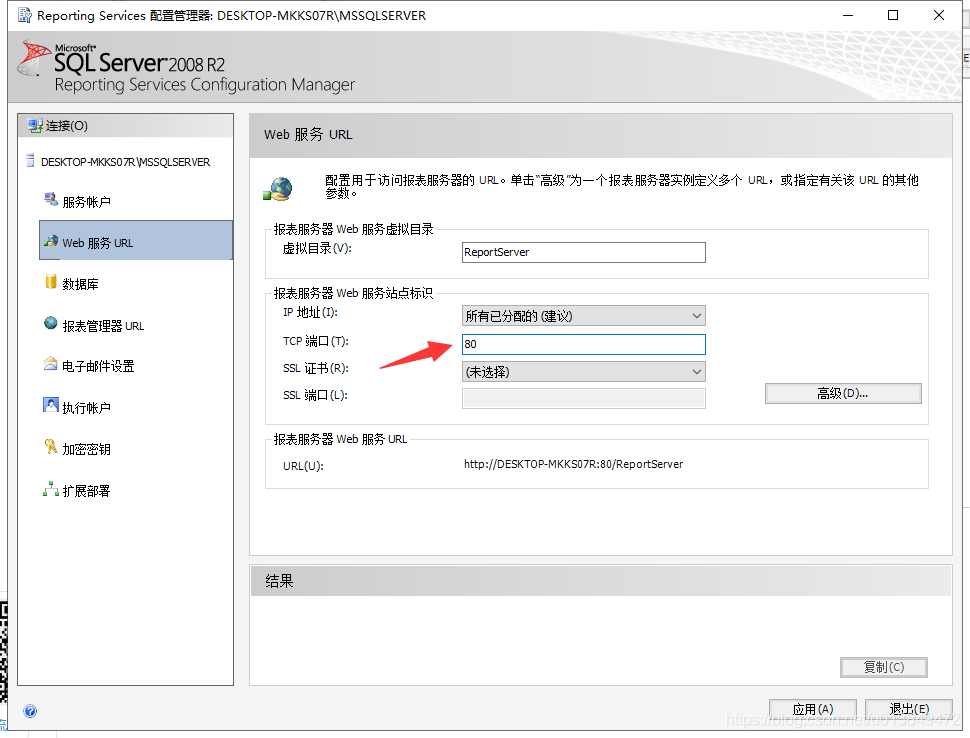
3.看到那个熟悉的80了么,把" TCP 端口 "的80改成别的数值,保存即可!修改后不影响Sql Server监听功能
(这个数值建议改成八十几,因为八十几的端口段,使用的程序很少,不会和别的程序有冲突,我自己改的是81)
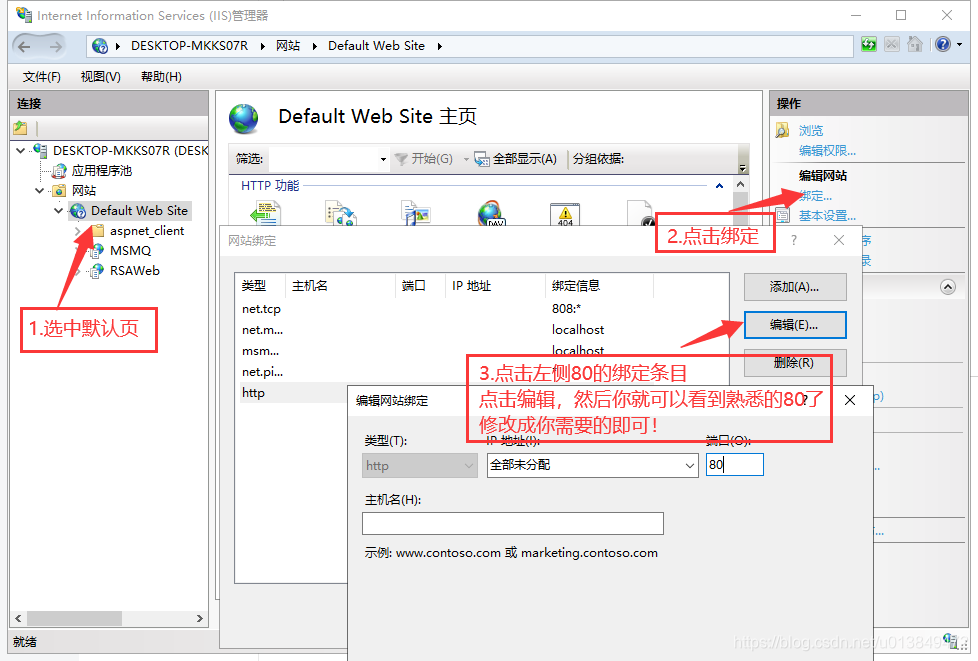
类似的修改还有IIS的,我就不解释了,直接上图!

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









