







Graph Attention Network with Memory Fusion for Aspect-level Sentiment Analysis(方面级情感分析的带有记忆融合的图注意力网络)
1 摘要
方面级情感分析(ASC)预测文本或评论中每个特定方面术语的情感极性。最近的研究使用基于注意力的方法能有效提升方面级情感分析的表现。这些方法忽略了方面和它相应的上下文单词之间的句法关系,导致模型错误地关注语法上不相关的单词。一个提出的解决方案,图卷积网络(GCN),不能完全避免这个问题。但它的确包含了关于语法的有用信息,它为所有的相关单词之间的边分配了相同的权重。它仍然可能通过图卷积传播的迭代错误地将不相关的单词与目标方面联系起来。在这个研究中,提出了一个带有记忆融合的图注意力网络,通过赋予边缘不同的权值来扩展GCN的思想。句法约束可以用来阻止不相关单词的图卷积传播。采用卷积层和记忆融合技术来学习和利用多字关系并比较不同的单词权重来进一步提高性能。在五个数据集上的实验表明,该方法比现有的方法具有更好的性能。本文的代码在https://github.com/YuanLi95/GATT-For-Aspect.
2 引言
本文提出的模型从两个方面扩展了图卷积网络的想法。首先,图注意机制为边分配不同的权重,所以可以施加语法约束来阻止语法无关的单词传播目标方面。第二,一个卷积操作被用来利用多词关系抽取局部信息,例如“not good”,“far from perfect”,可以进一步提高性能。为了集成所有特性,使用了一个记忆融合层(类似一个记忆网络),根据单词对最终分类的贡献分配不同的权重。
Yao et al. (2019)将图卷积网络引入情绪分类任务和取得了良好的表现。随后,Zhang et al. (2019)提出在句子的依赖树上使用GCN抽取长范围的句法信息。
3 带有记忆融合的图注意网络
此算法主要由四个部分组成:一个文本编码器,一个图注意层,一个卷积层,和一个记忆融合层,如图2.
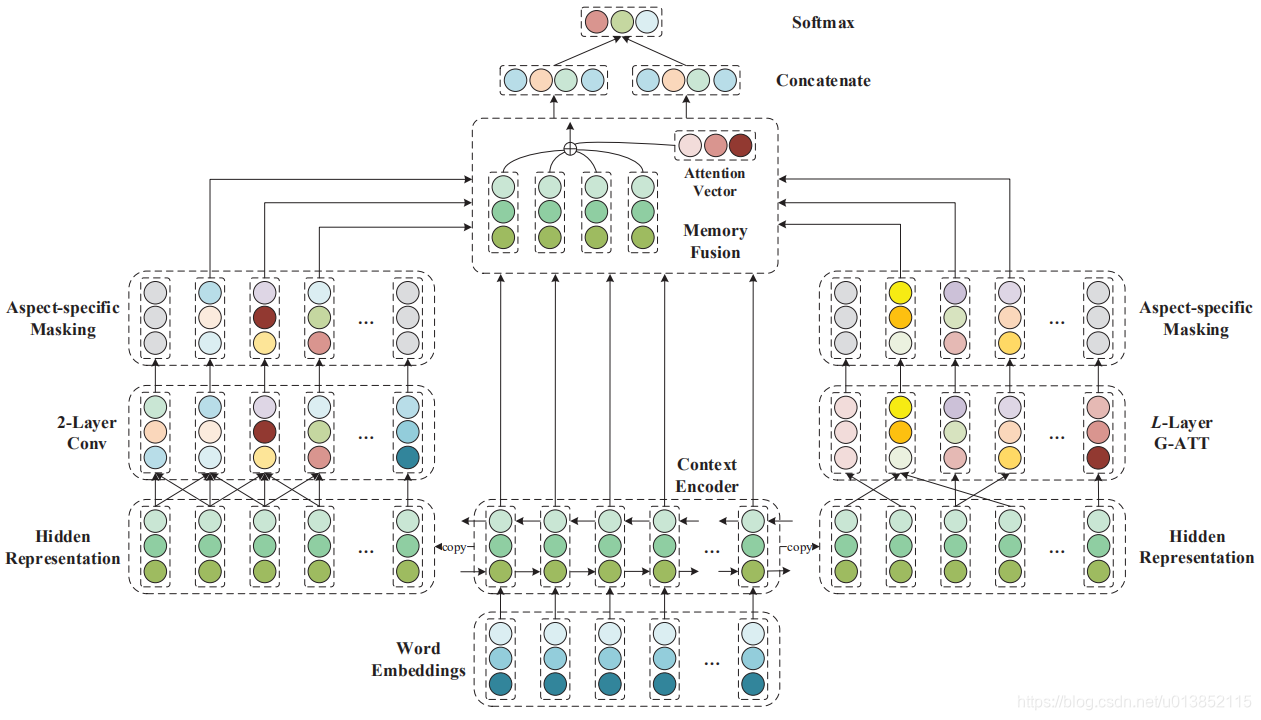
文本编码器使用一个vanilla bidirectional LSTM来表现原文的特征。它包含一个word embedding 层和一个BiLSTM层去产生一个文本的隐藏表示。使用这个隐藏表示作为输入,图注意层(G-ATT)在依赖树上训练以单词之间显式的结构化信息。卷积层被用来提取情感单词周围的局部信息,可以动态处理非单字的单词方面,像“not good”和“far from perfect”,而不是只提取它们向量的平均值。为了合并所有特性,我们采用了一个类似memory network的记忆融合层,能够根据文本单词对最终分类的贡献分配不同的权重。详细描述如下。
3.1 文本编码器
给出一个句子
x
=
[
x
1
,
x
2
,
.
.
.
,
x
τ
+
1
,
.
.
.
,
x
τ
+
m
,
.
.
.
,
x
n
]
x=[x_{1},x_{2},...,x_{\tau +1},...,x_{\tau +m},...,x_{n}]
x=[x1,x2,...,xτ+1,...,xτ+m,...,xn] 包含n个单词,目标方面从第
(
τ
+
1
)
(\tau + 1)
(τ+1)个单词开始,长度为m。使用BiLSTM作为文本编码器,这样可以表达句子中的长距离依赖。我们平均前向和反向的隐藏表示,以获取上下文表示,定义如下,
(
h
→
i
E
,
c
→
i
E
)
=
L
S
T
M
(
x
i
,
h
→
i
−
1
E
,
h
→
c
−
1
E
)
(1)
(\overrightarrow{h}^E_i , \overrightarrow{c}^E_i)=LSTM(x_i,\overrightarrow{h}^E_{i-1},\overrightarrow{h}^E_{c-1}) \tag{1}
(hiE,ciE)=LSTM(xi,hi−1E,hc−1E)(1)
(
h
←
i
E
,
c
←
i
E
)
=
L
S
T
M
(
x
i
,
h
←
i
+
1
E
,
h
←
c
+
1
E
)
(2)
(\overleftarrow{h}^E_i , \overleftarrow{c}^E_i)=LSTM(x_i,\overleftarrow{h}^E_{i+1},\overleftarrow{h}^E_{c+1}) \tag{2}
(hiE,ciE)=LSTM(xi,hi+1E,hc+1E)(2)
h
i
=
(
h
i
→
⊕
h
i
←
)
/
2
(3)
h_i=(\overrightarrow{h_i}⊕\overleftarrow{h_i})/2 \tag{3}
hi=(hi⊕hi)/2(3)
⊕是矩阵相加操作。
h
i
→
\overrightarrow{h_i}
hi,
h
i
←
\overleftarrow{h_i}
hi,
h
i
h_i
hi分别是前向,后向,和输出表征。所以文本编码器的最终表征可以表示为
H
E
=
[
h
1
E
,
h
2
E
,
.
.
.
,
h
τ
+
1
E
,
.
.
.
,
h
τ
+
m
E
,
.
.
.
,
h
n
E
]
H^E=[h^E_1,h^E_2,...,h^E_{\tau +1},...,h^E_{\tau +m},...,h^E_n]
HE=[h1E,h2E,...,hτ+1E,...,hτ+mE,...,hnE]。
3.2 图注意层
图注意(G-ATT)层在依赖树上学习目标方面的语法相关词,这已经广泛应用于几种NLP任务,以有效地识别单词的关系及作用。在将给定的句子解析为依赖项树之后,根据树的拓扑结构建立起邻接矩阵。值得注意的是,依赖树是一个有向图。因此,我们考虑了图形注意机制的方向,但该机制可以适应于非定向感知的场景。因此,我们提出了一个变体适用于无向的依赖图。获取的隐藏状态
H
E
∈
R
n
×
d
h
H^E\in \Bbb{R}^{n \times d_h}
HE∈Rn×dh注入堆叠G-ATT模型,这个模型以带有一个L图注意层的多层方式执行。
在实践中,在l-the层中的表征没有立即被送入G-ATT层。为了增强相应方面上下文单词的相关性,我们采用一个位置权重方法到l层中单词i的表征,这在以前的工作中是广泛使用的(Li et al.,2018; Zhang et al., 2019),定义如下,
q
i
=
{
1
−
τ
+
1
−
i
n
1
≤
i
<
τ
+
1
0
τ
+
1
≤
i
≤
τ
+
m
1
−
i
−
τ
−
m
n
τ
+
m
<
i
≤
n
(4)
q_i=\left\{\begin{matrix} 1-\frac{\tau +1-i}{n} & 1\leq i< \tau +1\\ 0 & \tau +1\leq i\leq \tau +m\\ 1-\frac{i-\tau -m}{n} & \tau +m<i\leq n \end{matrix}\right. \tag{4}
qi=⎩⎨⎧1−nτ+1−i01−ni−τ−m1≤i<τ+1τ+1≤i≤τ+mτ+m<i≤n(4)
h
^
i
l
=
q
i
h
i
l
(5)
\hat{h}^l_i=q_i h^l_i \tag{5}
h^il=qihil(5)
q
i
∈
R
q_i\in \Bbb{R}
qi∈R是单词i的位置权重。
在每一层中,有一个注意力系数
α
i
j
l
\alpha^l_{ij}
αijl被用来衡量单词i和单词j之间的重要性,定义如下,
α
i
,
j
l
=
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
T
[
W
α
l
h
^
i
l
∣
∣
W
α
l
h
^
j
l
]
)
)
∑
k
∈
N
i
e
x
p
(
L
e
a
k
y
R
e
L
U
(
a
T
[
W
α
l
h
^
i
l
∣
∣
W
α
l
h
^
j
l
]
)
)
(6)
\alpha^l_{i,j}=\frac{exp(LeakyReLU(a^T[W^l_\alpha \hat{h}^l_i || W^l_\alpha \hat{h}^l_j]))}{\sum_{k\in N_i}exp(LeakyReLU(a^T[W^l_\alpha \hat{h}^l_i || W^l_\alpha \hat{h}^l_j]))} \tag{6}
αi,jl=∑k∈Niexp(LeakyReLU(aT[Wαlh^il∣∣Wαlh^jl]))exp(LeakyReLU(aT[Wαlh^il∣∣Wαlh^jl]))(6)其中
N
i
N_i
Ni是单词i的邻接集合,
W
α
l
∈
R
d
h
×
d
h
W^l_\alpha \in \Bbb R^{d_h \times d_h}
Wαl∈Rdh×dh是一个共享权重矩阵用来按顺序对每个单词进行线性变换以获得高级表征的充足的表达能力。||是连接运算符,
a
∈
R
2
d
h
a \in \Bbb R^{2d_h}
a∈R2dh是一个权重向量,LeakyReLU是非线性的。
为了稳定图注意力的学习过程,我们使用相同的参数设置实现了K个不同的注意,类似于Vaswani et al. (2017)提出的多头注意机制。因此,l+1层中单词i的最终表征
h
i
l
+
1
h^{l+1}_i
hil+1可以这样得到,
h
i
l
+
1
=
R
e
L
U
(
1
K
∑
k
=
1
K
∑
j
∈
N
i
α
i
,
j
l
,
k
W
k
l
h
^
j
l
)
(7)
h^{l+1}_i=ReLU(\frac{1}{K}\sum_{k=1}^{K} \sum_{j\in N_i}\alpha ^{l,k}_{i,j}W^l_k\hat h^l_j) \tag{7}
hil+1=ReLU(K1k=1∑Kj∈Ni∑αi,jl,kWklh^jl)(7)其中
α
i
,
j
l
,
k
\alpha ^{l,k}_{i,j}
αi,jl,k是第k个公式(6)中计算的注意力系数,
W
k
l
W^l_k
Wkl是对应的第l层GAT层中第k个注意力的权重矩阵,并且非线性函数是ReLU。L层G-ATT的最终表征定义为
H
L
=
[
h
1
L
,
h
2
L
,
.
.
.
,
h
τ
+
1
L
,
.
.
.
,
h
τ
+
m
L
,
.
.
.
,
h
n
L
]
H^L=[h^L_1,h^L_2,...,h^L_{\tau +1},...,h^L_{\tau +m},...,h^L_n]
HL=[h1L,h2L,...,hτ+1L,...,hτ+mL,...,hnL],
h
i
L
∈
R
d
h
h^L_i \in \Bbb R^{d_h}
hiL∈Rdh。
3.3 卷积层
卷积层用于提取那些多种情绪词组的局部n元信息,为了提高对于n元特征的学习能力。文本编码器的隐藏表征
H
E
H^E
HE被输入进两个卷积层。在每个卷积层中,我们使用F个卷积滤波器去学习局部n元特征。在一个w个单词的窗口
h
i
:
i
+
w
−
1
h_{i:i+w-1}
hi:i+w−1,第f个过滤器生成特征映射
c
i
f
c^f_i
cif如下,
c
i
f
=
R
e
L
U
(
W
f
∘
h
i
:
i
+
w
−
1
E
+
b
f
)
(8)
c^f_i=ReLU(W^f\circ h^E_{i:i+w-1}+b^f) \tag{8}
cif=ReLU(Wf∘hi:i+w−1E+bf)(8)其中
∘
\circ
∘是一个卷积操作,
W
f
∈
R
w
×
d
h
W^f\in \Bbb R^{w\times d_h}
Wf∈Rw×dh和
b
f
∈
R
d
h
b^f\in \Bbb R^{d_h}
bf∈Rdh分别表示权重矩阵和bias,w是过滤器的长度,非线性函数是ReLU。通过连接所有的特征映射,单词i的表征将是
h
i
c
=
[
c
i
1
,
c
i
2
,
.
.
.
,
c
i
f
,
.
.
.
,
c
i
F
]
h^c_i=[c^1_i,c^2_i,...,c^f_i,...,c^F_i]
hic=[ci1,ci2,...,cif,...,ciF]。确保输出的shape与卷积层中输入的shape一致,我们将F设置为
d
h
d_h
dh,并用零向量填充语料库中每个句子到最大的输入长度。然后,我们将特征映射发送到第二个卷积层,去获取卷积层的最终表征
H
C
=
[
h
1
C
,
h
2
C
,
.
.
.
,
h
τ
+
1
C
,
.
.
.
,
h
τ
+
m
C
,
.
.
.
,
h
n
C
]
H^C=[h^C_1,h^C_2,...,h^C_{\tau +1},...,h^C_{\tau +m},...,h^C_n]
HC=[h1C,h2C,...,hτ+1C,...,hτ+mC,...,hnC],
h
i
C
∈
R
d
h
h^C_i \in \Bbb R^{d_h}
hiC∈Rdh。
3.4 Aspect-Specific Masking
特定方面的掩蔽层旨在学习用于记忆融合和最终分类的特定方面的内容。因此,我们mask out来自G-ATT和卷积层的输入的隐藏状态向量,
H
L
H^L
HL和
H
C
H^C
HC。在形式上,我们将非方面词的所有向量设置为零,并保持方面词的向量不变,定义如下,
h
i
=
{
0
1
≤
i
<
τ
+
1
,
τ
+
m
<
i
≤
n
h
i
τ
+
1
≤
i
≤
τ
+
m
(9)
h_i=\left\{\begin{matrix} 0 & 1\leq i<\tau +1,\tau +m<i\leq n\\ h_i & \tau +1 \leq i\leq \tau +m \end{matrix}\right. \tag{9}
hi={0hi1≤i<τ+1,τ+m<i≤nτ+1≤i≤τ+m(9)
G-ATT层经过mask操作后的输出向量是
H
m
a
s
k
e
d
L
=
[
0
,
.
.
.
,
h
τ
+
1
L
,
.
.
.
,
h
τ
+
m
L
,
.
.
.
,
0
]
H^L_{masked}=[0,...,h^L_{\tau +1},...,h^L_{\tau +m},...,0]
HmaskedL=[0,...,hτ+1L,...,hτ+mL,...,0],它能感知方面附近的上下文,因此能够考虑句法依赖和长范围的多词关系,卷积层经过mask操作后的输出表征是
H
m
a
s
k
e
d
C
=
[
0
,
.
.
.
,
h
τ
+
1
C
,
.
.
.
,
h
τ
+
m
C
,
.
.
.
,
0
]
H^C_{masked}=[0,...,h^C_{\tau +1},...,h^C_{\tau +m},...,0]
HmaskedC=[0,...,hτ+1C,...,hτ+mC,...,0]。
3.5 记忆融合
记忆融合的目的是学习与方面词的意义相关的最终表征。其思想是通过联合G-ATT和Conv的向量到隐藏向量,从隐藏表征中得到与方面词具有语义相关的重要特征。形式上,我们计算
H
E
H^E
HE中第i个字和
H
L
H^L
HL中第j个字的注意得分,定义为,
e
i
=
∑
j
=
1
n
h
i
L
T
W
l
h
j
E
=
∑
j
=
τ
+
1
τ
+
m
h
i
L
T
W
l
h
j
E
(10)
e_i=\sum_{j=1}^{n}h_i^{L^T}W_lh_j^E=\sum_{j=\tau +1}^{\tau +m}h_i^{L^T}W_lh_j^E \tag{10}
ei=j=1∑nhiLTWlhjE=j=τ+1∑τ+mhiLTWlhjE(10)
其中
W
l
∈
R
d
h
×
d
h
W_l\in \Bbb R^{d_h\times d_h}
Wl∈Rdh×dh是一个双线性项,它与这两个向量相互作用,并捕获特定的语义关系。根据Socher et al.(2013),这样一个张量运算能被用来在这些向量之间建立更复杂的模型。因此,注意力得分权重和G-ATT的最终表征这样计算,
α
i
=
e
x
p
(
e
i
)
∑
k
=
1
n
e
x
p
(
e
k
)
(11)
\alpha_i=\frac{exp(e_i)}{\sum_{k=1}^{n}exp(e_k)} \tag{11}
αi=∑k=1nexp(ek)exp(ei)(11)
S
g
=
∑
i
=
1
n
α
i
h
i
E
(12)
S_g=\sum_{i=1}^{n}\alpha_ih_i^E \tag{12}
Sg=i=1∑nαihiE(12)
因此,卷积层的最终表征这样计算
r
i
=
∑
j
=
1
n
h
i
C
T
W
c
h
j
E
=
∑
j
=
τ
+
1
τ
+
m
h
i
C
T
W
c
h
j
E
(13)
r_i=\sum_{j=1}^nh_i^{C^T}W_ch_j^E=\sum_{j=\tau+1}^{\tau+m}h_i^{C^T}W_ch_j^E \tag{13}
ri=j=1∑nhiCTWchjE=j=τ+1∑τ+mhiCTWchjE(13)
β
i
=
e
x
p
(
r
i
)
∑
k
=
1
n
e
x
p
(
r
k
)
(14)
\beta_i=\frac{exp(r_i)}{\sum_{k=1}^{n}exp(r_k)} \tag{14}
βi=∑k=1nexp(rk)exp(ri)(14)
S
c
=
∑
i
=
1
n
β
i
h
i
E
(15)
S_c=\sum_{i=1}^{n}\beta_ih_i^E \tag{15}
Sc=i=1∑nβihiE(15)
3.6 情感分类
得到表征
s
g
s_g
sg和
s
c
s_c
sc之后,他们被喂给一个全连接层,然后经过一个softmax层生成一个所有类别的概率分布,
y
^
=
s
o
f
t
m
a
x
(
W
s
[
s
g
∣
∣
s
c
]
+
b
s
)
(16)
\hat{y}=softmax(W_s[s_g||s_c]+b_s) \tag{16}
y^=softmax(Ws[sg∣∣sc]+bs)(16)
其中
W
s
W_s
Ws和
b
s
b_s
bs分别表示输出层的权重和bias。因此,给出一个训练集
{
x
(
t
)
,
y
(
t
)
}
t
=
1
T
=
1
\begin{Bmatrix} x^(t),y^(t) \end{Bmatrix}_{t=1}^T=1
{x(t),y(t)}t=1T=1,其中
x
(
t
)
x^{(t)}
x(t)是训练样本,
y
(
t
)
y^{(t)}
y(t)是对应真实的情感标签,T是语料库中训练样本的数量。训练目标是最小化交叉熵
L
c
l
s
(
θ
)
L_{cls}(\theta)
Lcls(θ),定义如下,
L
c
l
s
(
θ
)
=
−
1
T
∑
t
=
1
T
l
o
g
p
(
y
^
(
t
)
∣
x
(
t
)
;
θ
)
+
λ
∣
∣
θ
∣
∣
2
2
(17)
L_{cls}(\theta)=-\frac{1}{T}\sum_{t=1}^Tlog p(\hat y^{(t)}|x^{(t)};\theta)+\lambda||\theta||_2^2 \tag{17}
Lcls(θ)=−T1t=1∑Tlogp(y^(t)∣x(t);θ)+λ∣∣θ∣∣22(17)
其中
θ
\theta
θ表示所有可训练参数。为了避免过拟合,训练时损失函数引入了一个
L
2
L_2
L2-regularization
λ
∣
∣
θ
∣
∣
2
2
\lambda||\theta||_2^2
λ∣∣θ∣∣22,其中
λ
\lambda
λ时衰减因子。
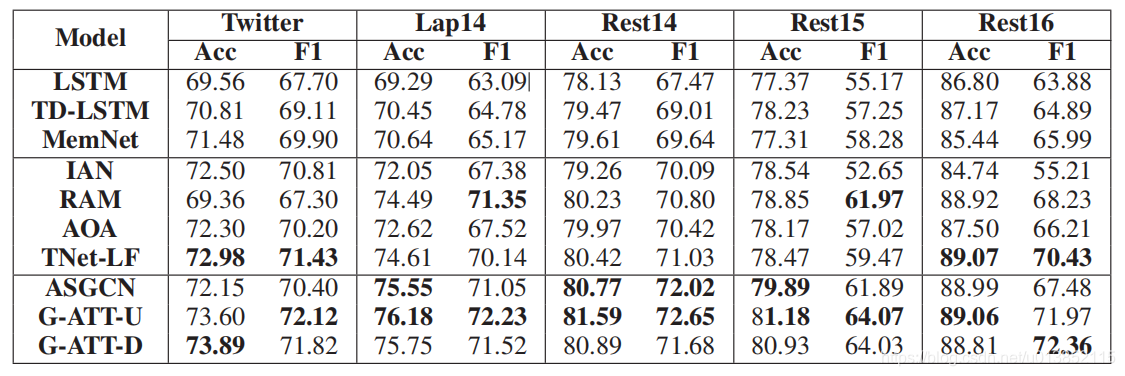
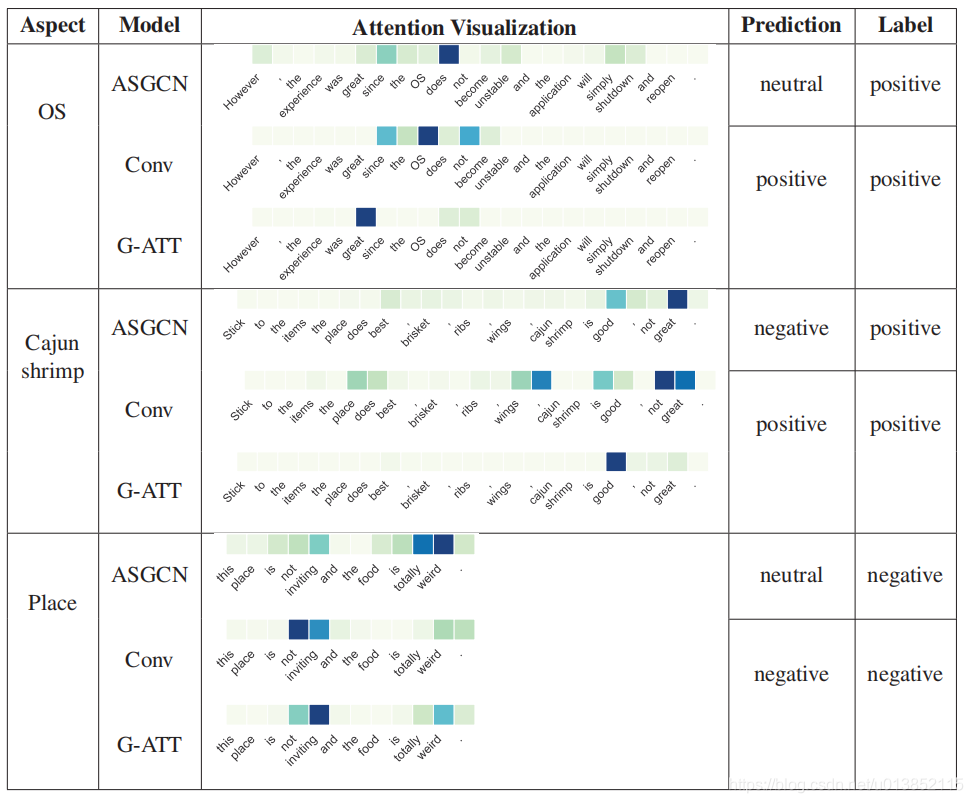
4 实验结果
本节对之前提出的几种方面层面情绪分析方法在五个语料库上进行了比较实验。然后详细介绍了实验设置和实证结果。

4.2 实施细节
所有模型均使用840B Common Crawl上预先训练的300维GloVe向量(Pennington et al.,2014)作为初始词嵌入。未在GloVe中出现的字初始化为U(-0.25,0.25)的均匀分布。隐藏层向量的维数都是300,所有的模型权值都用xavier正则化(gloria and Bengio,2010)进行初始化。采用RMSprop作为优化器,学习率为0.001,对所有模型进行训练。我们设置L2正则化衰减因子为1e-4,batch大小为40。在G-ATT层中LeakyReLU的负输入斜率设置为0.2。所有提到的超参数是使用网格搜索策略选择的。迭代的设定取决于早停策略。如果没有改善,训练过程将在五次迭代后停止。通过对三次随机初始化运行的结果进行平均,得到了实验结果。














 3946
3946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









