







我们之前已经学过了注意力模型,但是那是基于RNN模型的。RNN模型的结构决定了它不能并行运算,只能按照时间步一步一步地进行计算。自注意模型解决了这个问题。
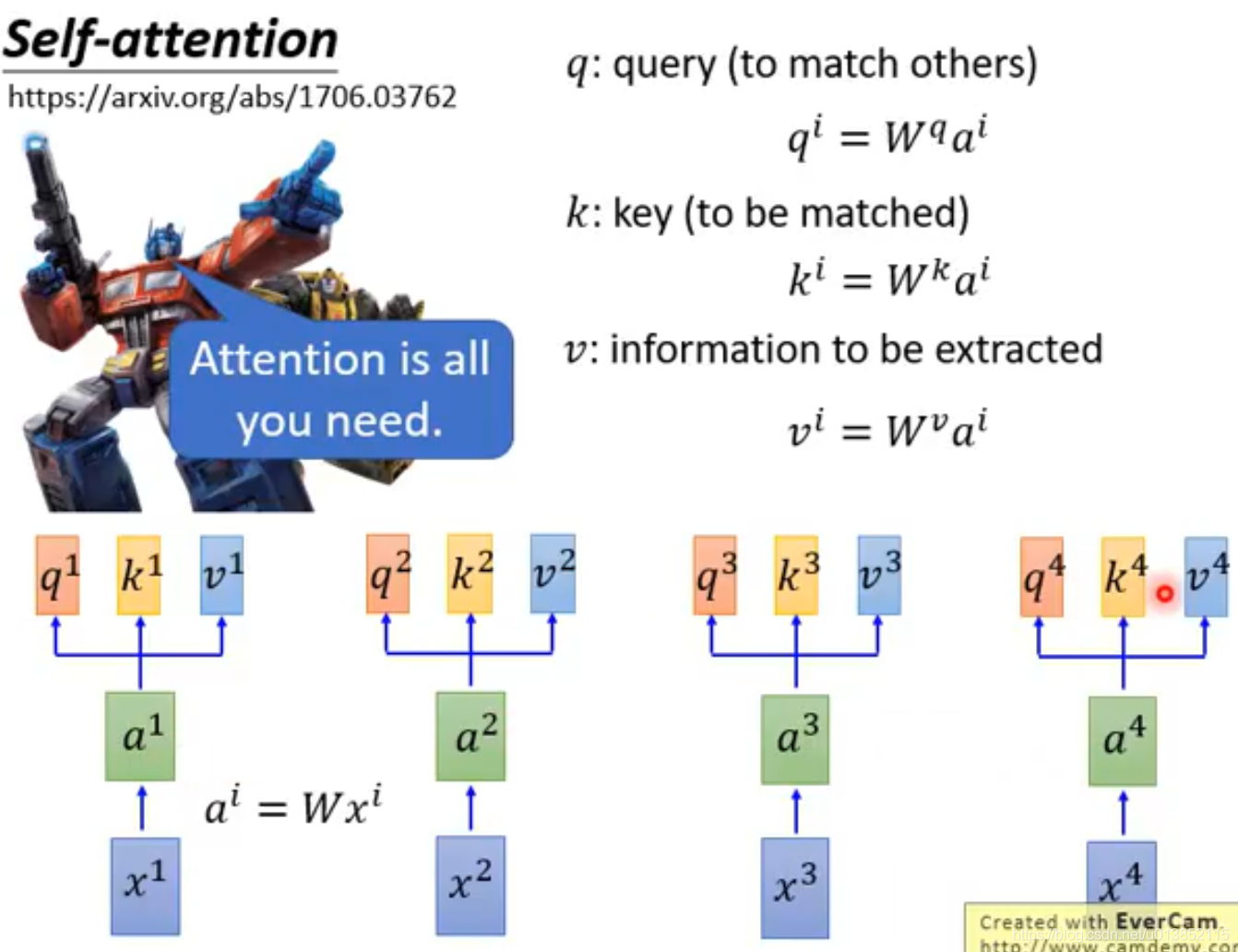
自注意模型引入了3个变量q,k,v。q是用来对其他的k进行匹配的,k是用来被其他q匹配的,这两个值用来计算注意力系数
α
\alpha
α。v是抽取出的特征。图中的a是one-hot编码经过embedding后的值。
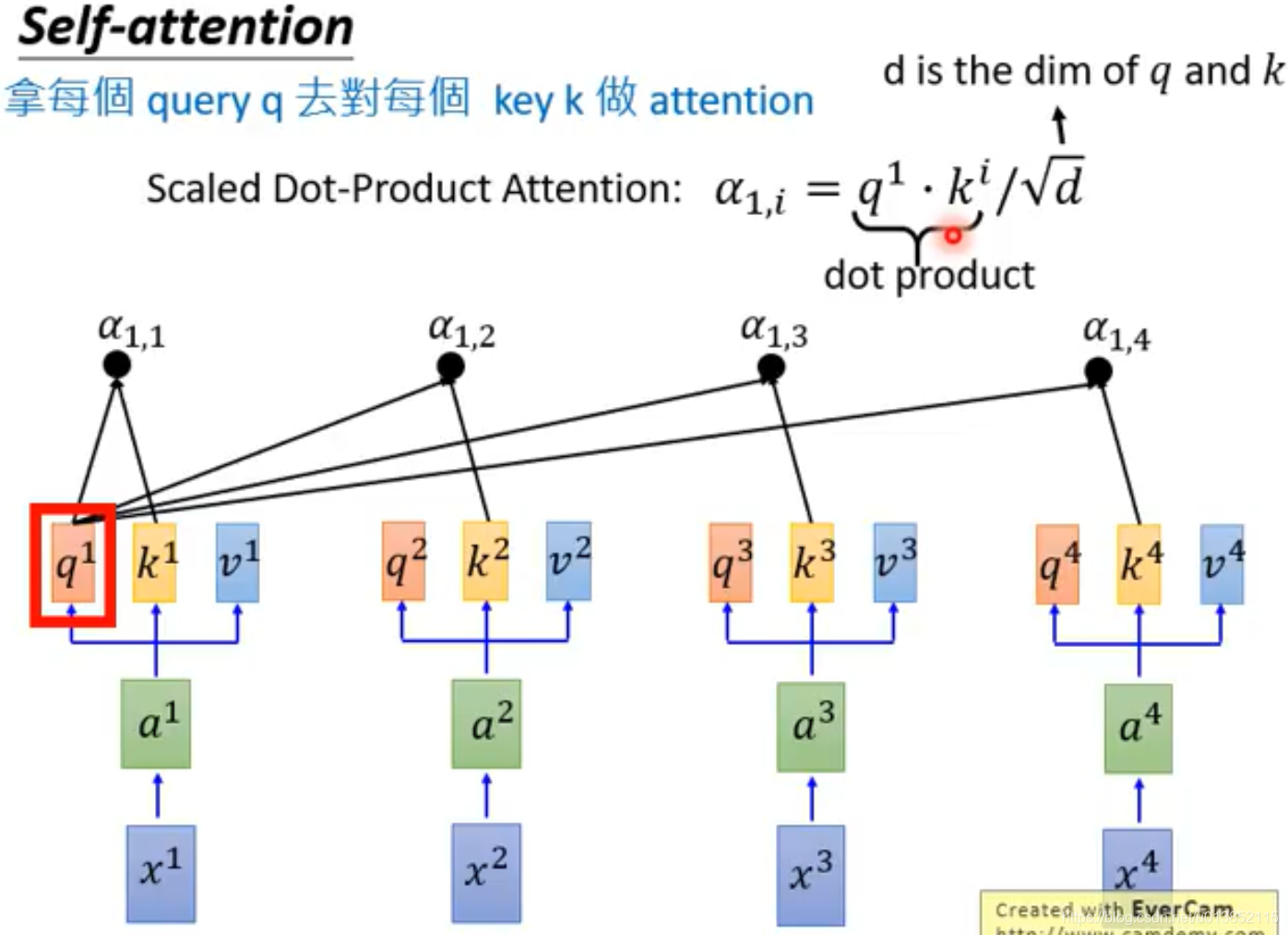
注意力系数是这样计算的:
α
i
,
j
=
q
i
⋅
k
j
/
d
\alpha_{i,j}=q^i \cdot k^j/\sqrt{d}
αi,j=qi⋅kj/d
其中d表示q和k的维度。
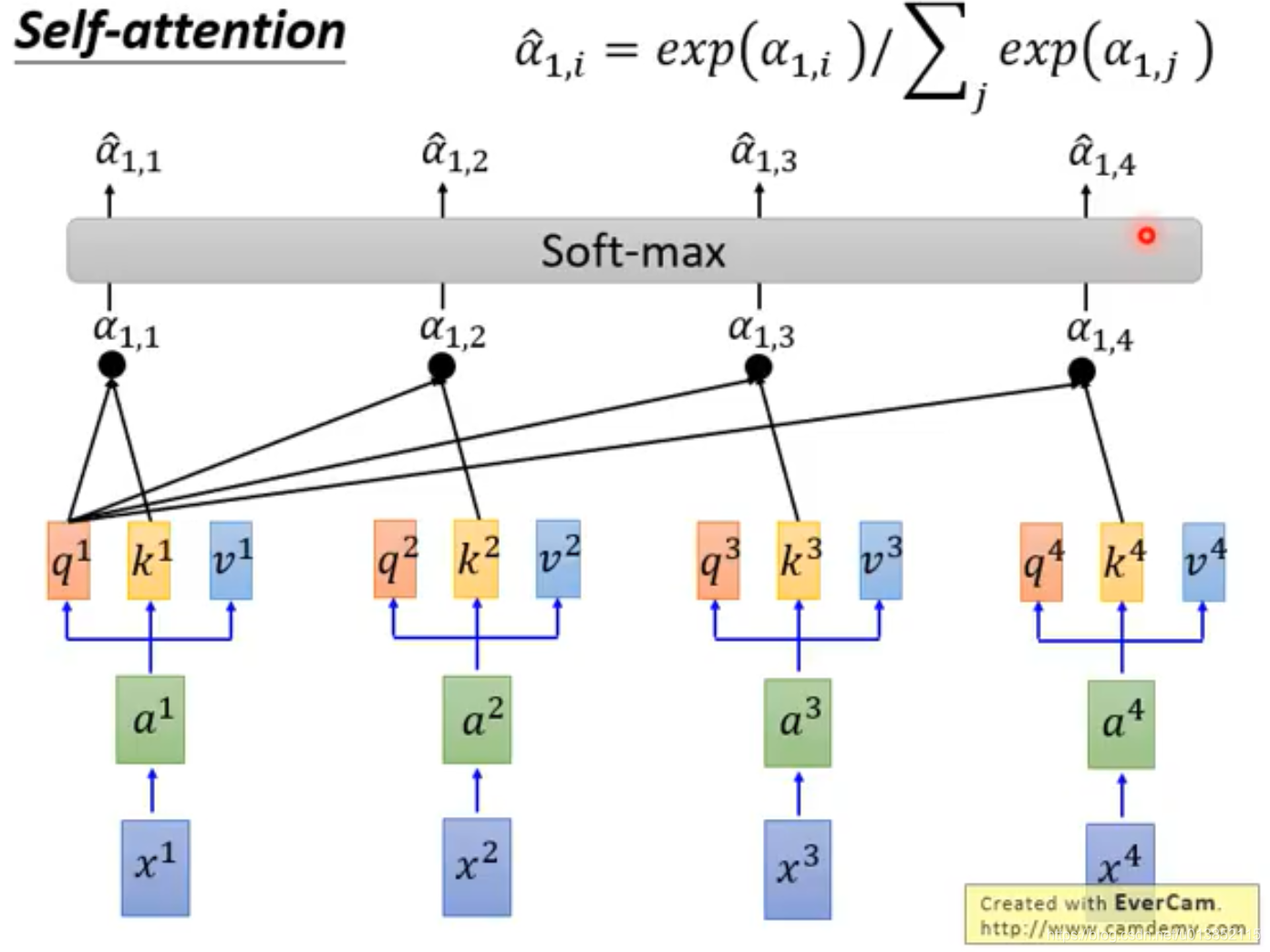
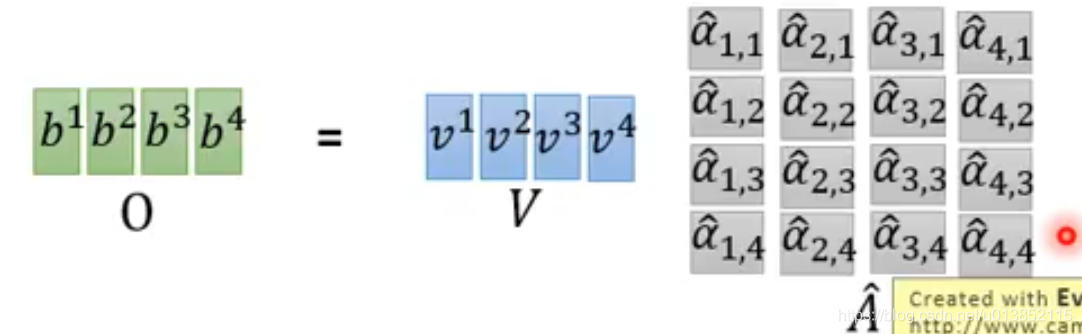
计算出的
α
\alpha
α通过一个softmax层变成
α
^
\hat{\alpha}
α^。
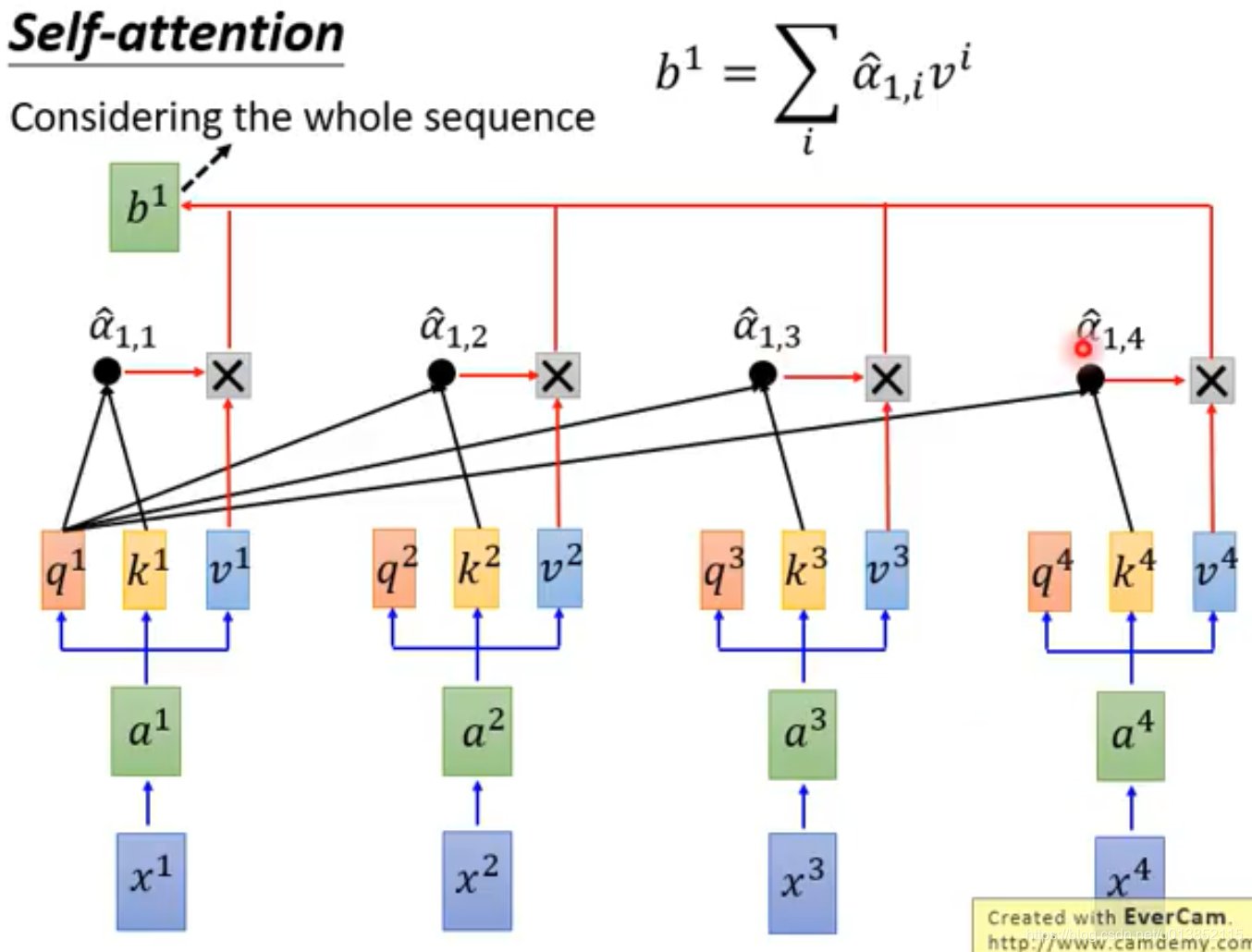
通过上图中的式子,会得到第一个输出b1。
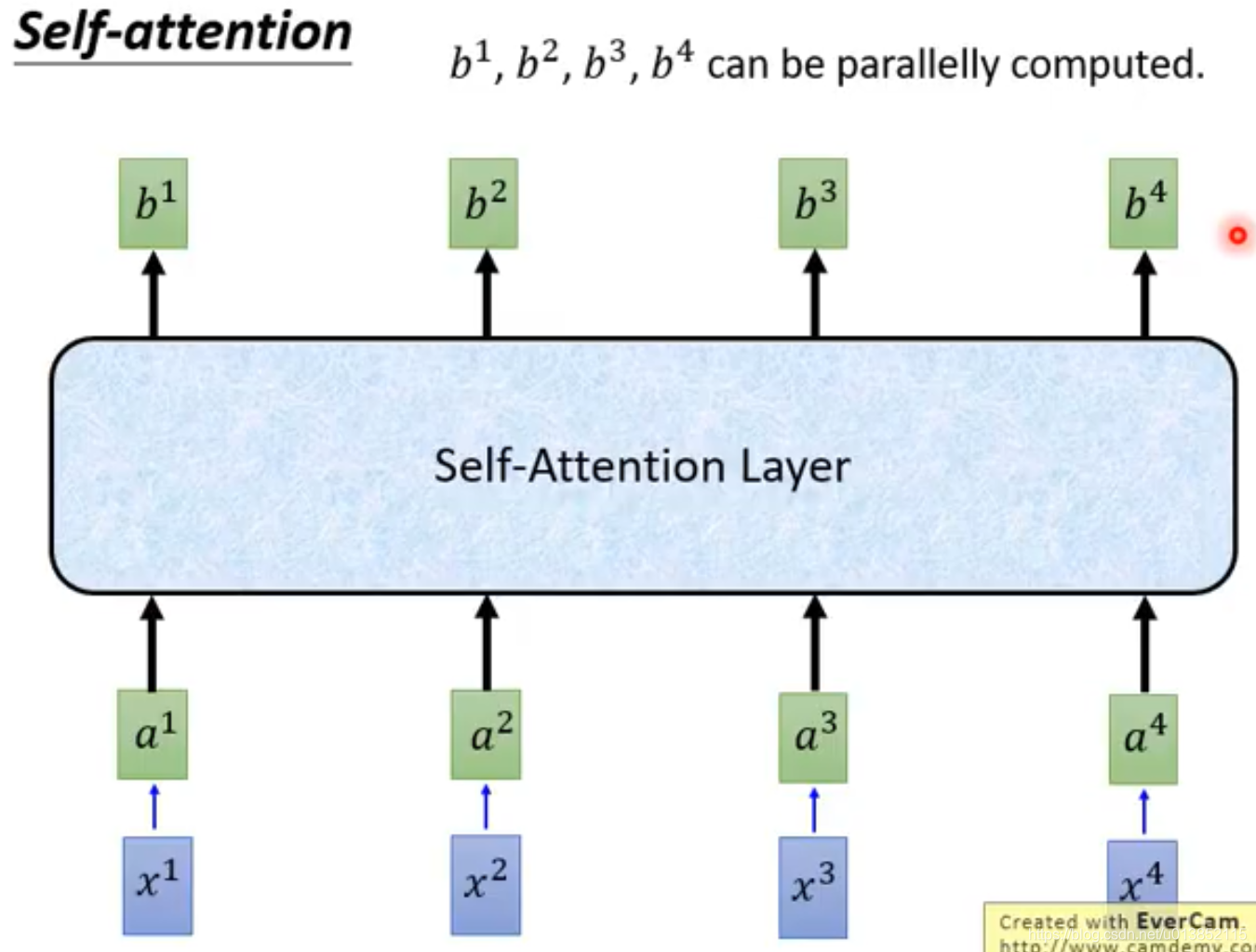
b1,b2,b3,b4是并行计算出来的。
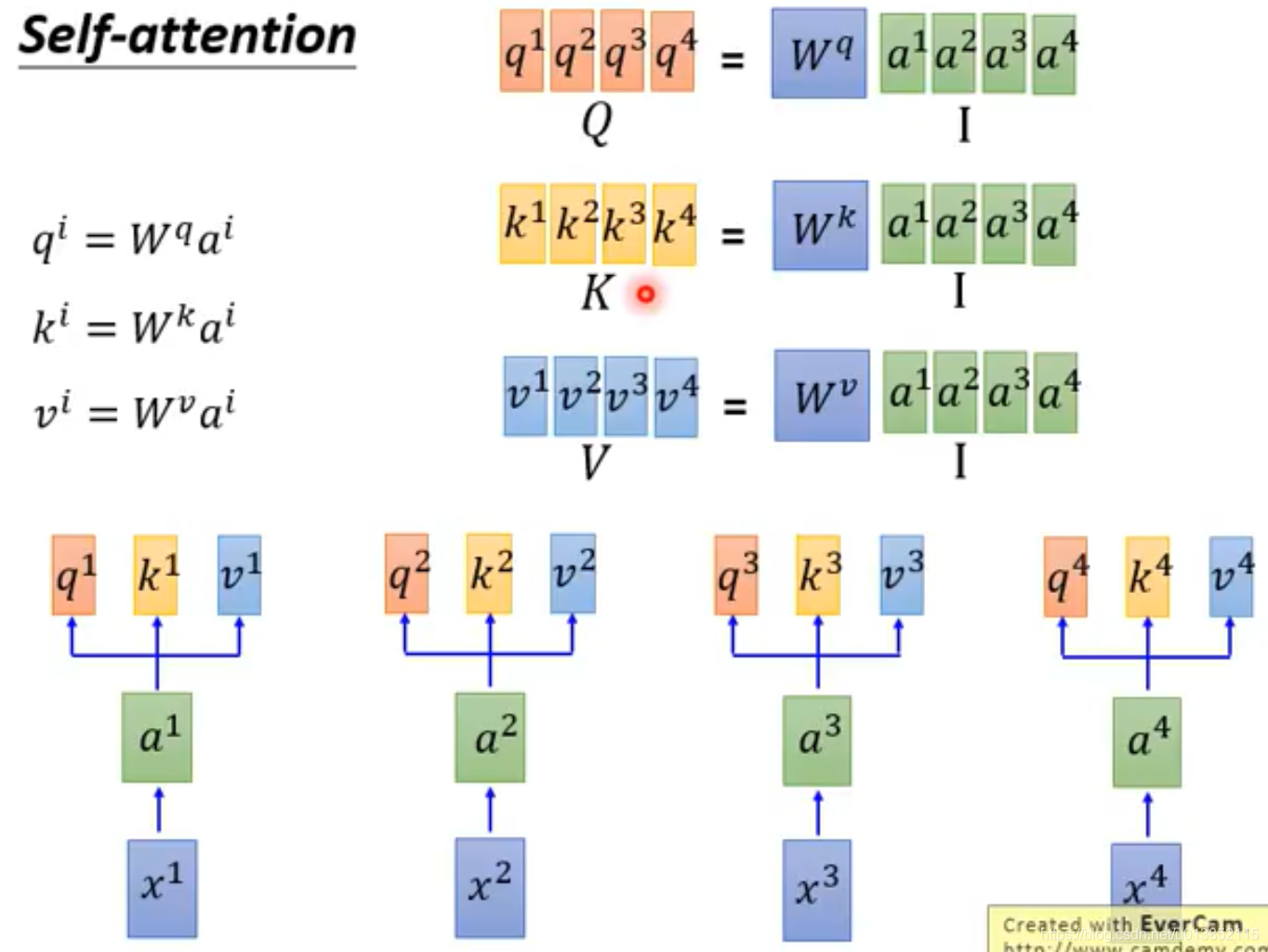
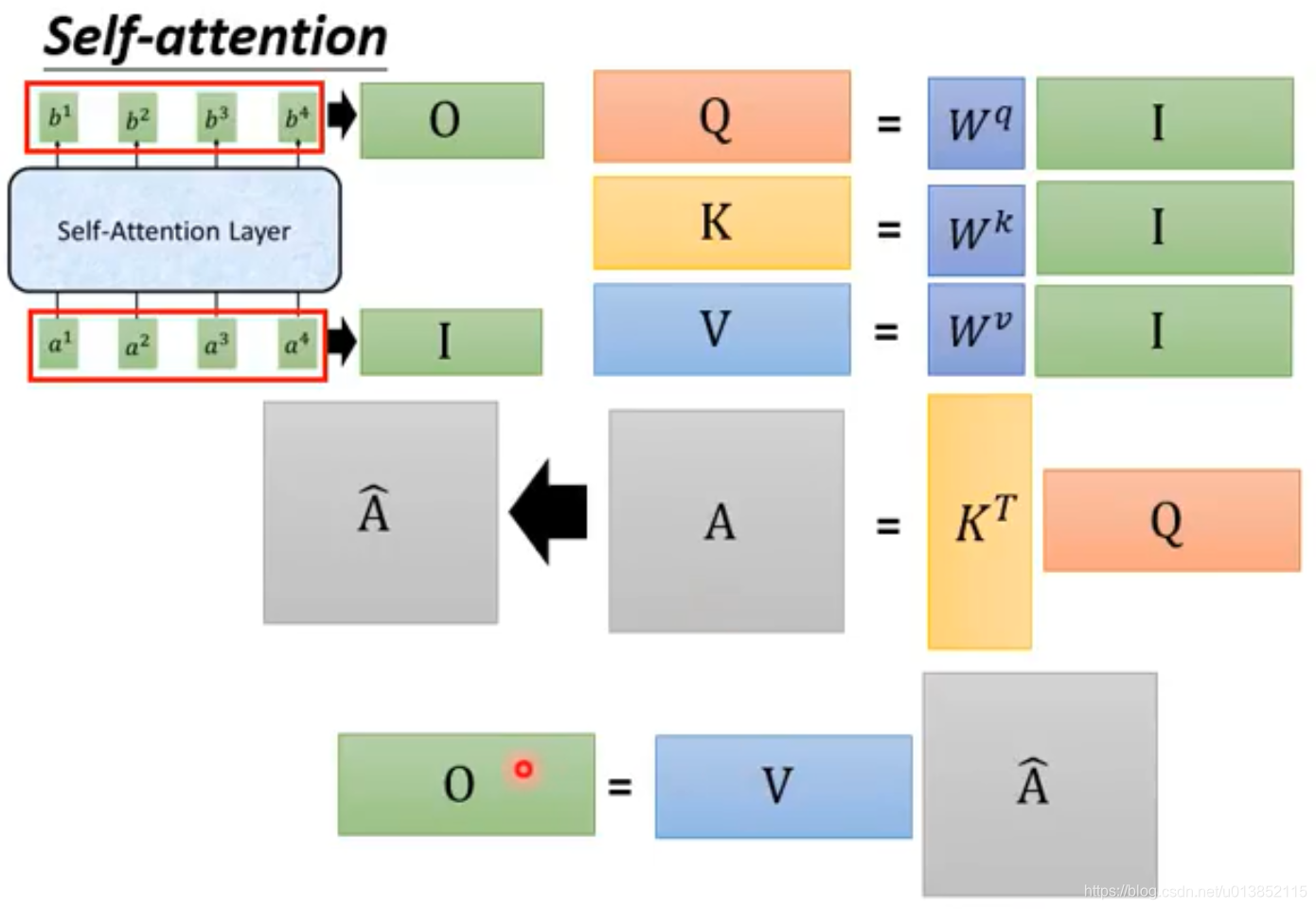
既然可以并行计算,我们就可以使用矩阵运算并使用GPU加速。















06-02
 9036
9036
9036
04-23
04-23
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









