







大神请绕道
Python多线程与多进程的对比
使用Python时,什么场合适合使用多线程?什么场合适合使用多进程?
- 对于io操作来说,多线程优于多进程
- 对于计算密集型任务来说(计算密集型可以理解为很耗CPU),多进程优于多线程
首先声明一点:Python中存在GIL(注意这不是Python语言本身的锅,而是Cython的锅),导致同一时刻只有一个线程在一个cpu上执行字节码, 无法将多个线程映射到多个cpu上执行
那为何对于io操作,多线程优于多进程呢?因为io操作会引起阻塞,阻塞会导致进程和线程切换,而线程的切换效率要优于进程。而对于计算密集型任务,需要充分发挥多核CPU的优势,GIL可以导致多线程没有多进程好。
join在多线程中的作用
当先看一段代码,并判断一下这个cost的值为多少
import threading, time
def a():
print('in a')
time.sleep(2)
print('out a')
def b():
print('in b')
time.sleep(3)
print('out b')
if __name__=='__main__':
start = time.time()
thread1 = threading.Thread(target=a)
thread2 = threading.Thread(target=b)
thread1.start()
thread2.start()
end=time.time()
cost = end - start
print('time is {}'.format(cost))
-------------------------------------------------------华---------------------------------------------------
----------------------------------------------------------丽------------------------------------------------
-------------------------------------------------------------的---------------------------------------------
----------------------------------------------------------------分------------------------------------------
-------------------------------------------------------------------隔---------------------------------------
----------------------------------------------------------------------线------------------------------------
约为0。原因是Python中是有一个主线程的,而这个print语句刚好属于这个主线程,所以它会先结束,从而这个cost也大约等于0。
如何证明
让代码说话,这里使用的Python版本为3.6.6,调试使用的IDE为:pycharm 2017.2.7。如何给代码打断点请百度,如何让代码一步步运行请按F7或百度。如果你对调试不熟悉,务必亲自动手。纸上得来终觉浅,绝知此事要躬行
- step1:打个断点,进入debug模式,并将函数a和b的sleep时长改为2000,3000,大一点设置,是为了之后的效果展示
- step2 看栈帧,可以看到目前只有一个主线程,点那个小的倒三角可以看到这种效果

- step3 让函数一直运行到print(‘time is {}’.format(cost))处,可以发现目前拥有3个线程在栈里面

- step4 console的输出是什么样的?函数a已经运行了,函数b也已经运行了

- step5 将
print('time is {}'.format(cost))继续运行完成,你会发现栈帧已经空空如也,因为主线程运行完毕并退出了
- step6 此时的console是什么情况呢?主线程的内容已经运行完成了,因为主线程的print语句已经有了输出结果。但是debug模式还没有退出,从下图中最左边的那个红框可以看出。

加入join
import threading, time
def a():
print('in a')
time.sleep(2)
print('out a')
def b():
print('in b')
time.sleep(3)
print('out b')
if __name__=='__main__':
start = time.time()
thread1 = threading.Thread(target=a)
thread2 = threading.Thread(target=b)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end=time.time()
cost = end - start
print('time is {}'.format(cost))
这次就不进行调试演示了,如果你对调试不熟,还是希望你去调试看一看,因为这次调试你会发现两个新大陆:
- 如果你很快的按
F7,你会发现某一段时间内按F7不管用,这是什么原因造成的呢? 不是你的电脑卡了,而是join使当前线程阻塞造成的。 - 在调试的console中,如果你运行到
thread2.join()这一步,不继续按F7,则会看到b函数运行完毕后的结果,即输出out b。如果你将函数b的sleep时间和函数a的sleep时间修改一下,比如函数a的sleep为2,b的sleep为10 。肉眼上效果会更好。
看看运行结果
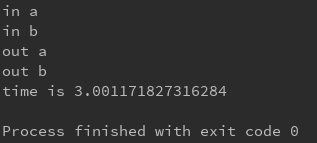
上述的join方法能够说明啥?
- 子线程使用了join方法后,主线程必须在子线程退出后才能退出。
- 另外,如果你上了调试器,且细心观察后还会发现threading.Thread(),这个方法只不过是创建一个线程对象,若没有对这个对象调用start方法,则栈里面是没有需要运行的子线程的,这个有什么意义呢?意义就是如果你要对这个线程做什么设置,那就先做好设置,然后去运行,比如设置成守护线程就需要放在start方法的前面。
守护线程
大家可以先百度一下对于守护线程的描述。总的来说就是别的线程运行完了就先退出,不用管我这个守护线程就行了。既然不用管我了,那就千万别对守护线程加join方法。
祖
传
代
码
祖传代码
祖传代码
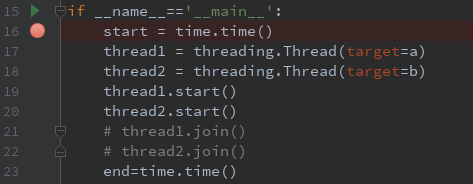
import threading, time
def a():
print('in a')
time.sleep(2)
print('out a')
def b():
print('in b')
time.sleep(3)
print('out b')
if __name__=='__main__':
start = time.time()
thread1 = threading.Thread(target=a)
thread2 = threading.Thread(target=b)
thread1.setDaemon(True)
thread2.setDaemon(True)
thread1.start()
thread2.start()
# thread1.join()
# thread2.join()
end=time.time()
cost = end - start
print('time is {}'.format(cost))
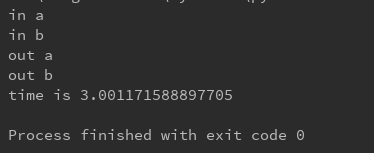
运行结果是这样的,这就是守护线程,主线程退出了,子线程也被强行退出了。
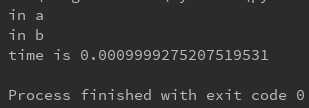
这里也附上对守护线程加上join方法的运行结果
总结
如果你从头看一遍,去好好调试调试,心里肯定已经有谱了,这里就不总结来贻笑大方了















 653
653











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









