







前言
在不稳定的网络环境中,如遭遇网络波动或丢包等偶发性网络问题时,重试机制是解决这类问题的有效手段。
架构
我们的系统架构通常如下所示:
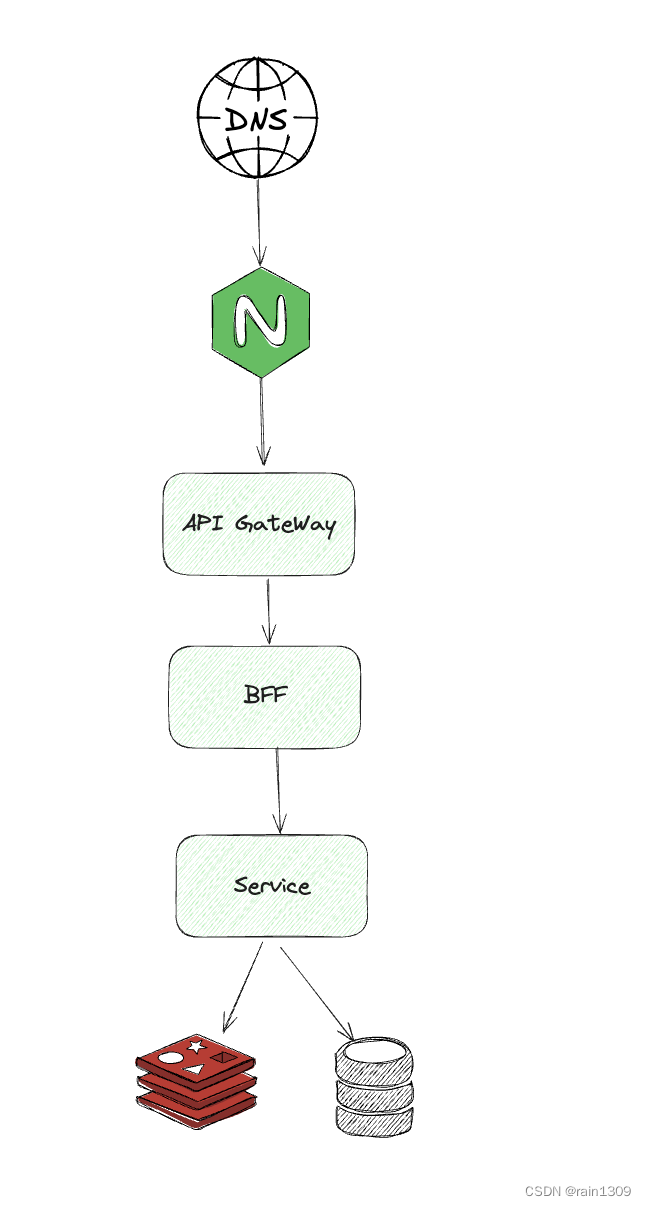
请求在从Nginx到API Gateway、再到后端服务(Backend For Frontend, BFF)层,以及最终到达服务层(Service)的过程中,都可能触发重试。
重试次数
在业务实践中,我们通常设定重试三次作为标准操作。
幂等
由于重试可能导致同一请求被多次处理,因此下游服务必须保证幂等性,以避免产生重复或不一致的结果。
重试场景
我们只在面对暂时性错误时采用重试策略,例如网络问题或服务限流等。对于如服务库存不足或用户权限不足等永久性错误,则应迅速失败(fast fail)。
重试传播
重试操作应由最初触发错误的层级执行,避免重试请求向上层传播,从而引发所谓的重试风暴。首次触发重试的层应向上层返回特定的错误码,上层根据这些错误码决定是否继续重试。
退避重试
频繁的重试可能会加剧网络带宽的负担,导致资源争用。指数退避是一种通过延长每次重试间隔时间来减少重试频率的技术。
使用场景
引入退避重试可能会延长服务请求的处理时间,这可能会触发上游服务的超时问题。因此,是否采用退避重试应根据具体业务场景来决定。例如,当触发下游服务的限流时,可以采用退避算法来控制发起端的流量。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









