







 本文介绍了Logistic回归的概念,它通过将线性回归的预测值输入sigmoid函数来得到0-1之间的概率。讨论了模型函数,解释了使用sigmoid的原因,以及如何将线性回归转化为对数几率回归。接着,详细阐述了损失函数,包括其直观理解,并解释了如何通过最大似然估计求解参数。最后,概述了梯度下降法在参数更新中的应用。
本文介绍了Logistic回归的概念,它通过将线性回归的预测值输入sigmoid函数来得到0-1之间的概率。讨论了模型函数,解释了使用sigmoid的原因,以及如何将线性回归转化为对数几率回归。接着,详细阐述了损失函数,包括其直观理解,并解释了如何通过最大似然估计求解参数。最后,概述了梯度下降法在参数更新中的应用。
理解Logistic回归首先要了解线性回归(http://blog.csdn.net/u013917439/article/details/77481216)。Linear Regression: h=WTX
训练集共m个样本,第i个样本 (x(i),y(i)),x(i)=(x(i)1,x(i)2,...,x(i)d)T ,即有d维特征。为了表示方便,将偏置b统一到权重W里。 W=(w0,w1,...,wd),w0=b 。
1 逻辑回归
Logistic回归将线性回归的结果输入到sigmoid函数函数中,得到一个0-1之间的数值,可用与分类。当结果大于 0.5时是正类,小于0.5时是负类。
sigmoid函数,也叫Logistic函数:
g(t)=11+e−t
图像如下:
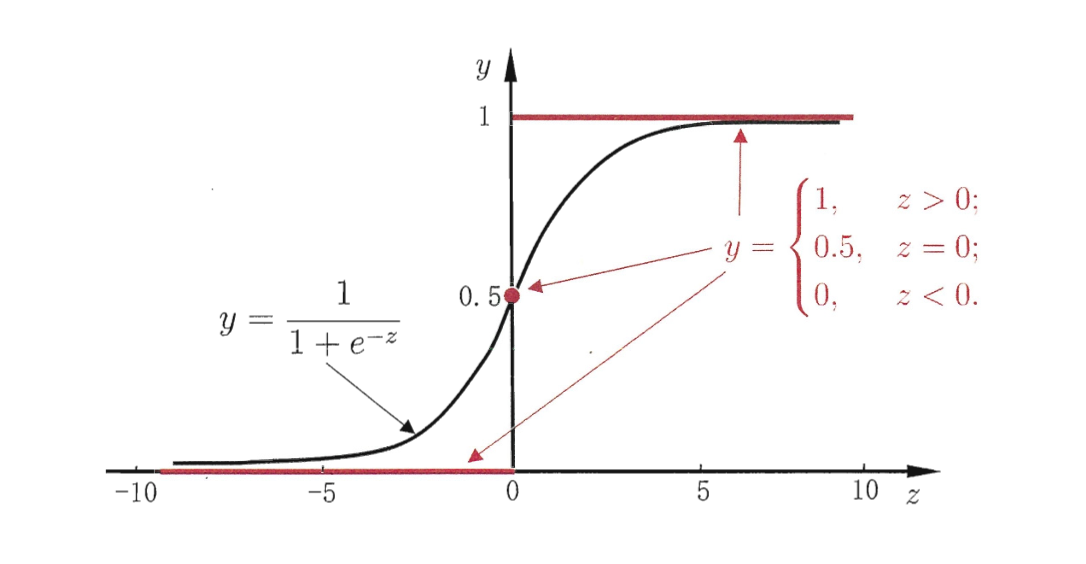
Logistic回归模型:
假设函数 Hypothesis:hw(X)=11+e−WTX
hw(X)=g(WTX)
g(z)=11+e−z
z=WTX
- 参数 Parameters:w
- 损失函数 CostFunction:J(w)=−1m∑mi=1[y(i)log(hw(x(i)))+(1−y(i))log(1−hw(x(i)))]
- 优化目标 Goal:minimizeJ(w)
2 模型函数
为什么将线性回归的结果输入到sigmoid函数中去做分类呢?
线性回归本身是预测连续值,是用于对线性数据进行拟合。输入特征X,输出的预测值 y∈R ,是实数集合。而二分类任务输入特征X后,输出 y∈0,1 。
怎样把实数集合映射到0,1? sigmoid函数:定义域R,值域(0,1),则 hw(X)=g(WTX) 的输出是0-1之间的数值,输出的是该样本为正类的概率。再用概率值判断所属类别。
p(y=1|x,w)=hw(x(i))
p(y=0|x,w)=1−hw(x(i))
对数几率
将 hw(x(i)) 视为样本作为正例的概率,则 1−hw(x(i)) 是该样本为反例的概率,两者的比值称为“几率“(odds),反应了 x(i) 作为正例的相对可能性。
odds=hw(x(i))1−hw(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









