caffe对于训练数据格式,支持:lmdb、h5py……,其中lmdb数据格式常用于单标签数据,像分类等,经常使用lmdb的数据格式。对于回归等问题,或者多标签数据,一般使用h5py数据的格式。当然好像还有其它格式的数据可用,不过我一般使用这两种数据格式,因此本文就主要针对这两种数据格式的制作方法,进行简单讲解。
一、lmdb数据
lmdb用于单标签数据。为了简单起见,我后面通过一个性别分类作为例子,进行相关数据制作讲解。
1、数据准备
首先我们要准备好训练数据,然后新建一个名为train的文件夹和一个val的文件夹:

train文件存放训练数据,val文件存放验证数据。然后我们在train文件下面,把训练数据性别为男、女图片各放在一个文件夹下面:
同样的我们在val文件下面也创建文件夹:
两个文件也是分别存我们用于验证的图片数据男女性别文件。我们在test_female下面存放了都是女性的图片,然后在test_male下面存放的都是验证数据的男性图片。
2、标签文件.txt文件制作.
接着我们需要制作一个train.txt、val.txt文件,这两个文件分别包含了我们上面的训练数据的图片路径,以及其对应的标签,如下所示。
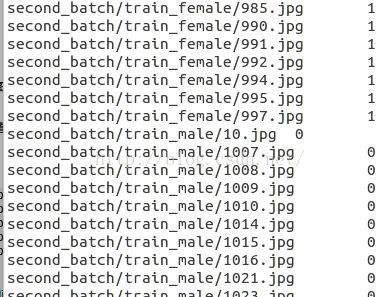
我们把女生图片标号为1,男生图片标记为0。标签数据文件txt的生成可以通过如下代码,通过扫描路径男、女性别下面的图片,得到标签文件train.txt和val.txt:
- <span style="font-family:Arial;font-size:18px;"><span style="font-size:18px;"><span style="font-size:18px;">import os
- import numpy as np
- from matplotlib import pyplot as plt
- import cv2
- import shutil
-
-
-
- def GetFileList(FindPath,FlagStr=[]):
- import os
- FileList=[]
- FileNames=os.listdir(FindPath)
- if len(FileNames)>0:
- for fn in FileNames:
- if len(FlagStr)>0:
- if IsSubString(FlagStr,fn):
- fullfilename=os.path.join(FindPath,fn)
- FileList.append(fullfilename)
- else:
- fullfilename=os.path.join(FindPath,fn)
- FileList.append(fullfilename)
-
-
- if len(FileList)>0:
- FileList.sort()
-
- return FileList
- def IsSubString(SubStrList,Str):
- flag=True
- for substr in SubStrList:
- if not(substr in Str):
- flag=False
-
- return flag
-
- txt=open('train.txt','w')
-
- imgfile=GetFileList('first_batch/train_female')
- for img in imgfile:
- str=img+'\t'+'1'+'\n'
- txt.writelines(str)
-
- imgfile=GetFileList('first_batch/train_male')
- for img in imgfile:
- str=img+'\t'+'0'+'\n'
- txt.writelines(str)
- txt.close()</span></span></span>
把生成的标签文件,和train\val文件夹放在同一个目录下面:
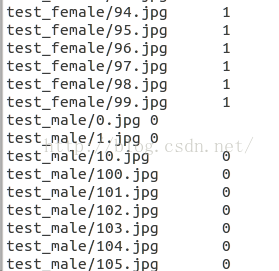
需要注意,我们标签数据文件里的文件路径和图片的路径要对应的起来,比如val.txt文件的某一行的图片路径,是否在val文件夹下面:
3、生成lmdb数据
接着我们的目的就是要通过上面的四个文件,把图片的数据和其对应的标签打包起来,打包成lmdb数据格式,打包脚本如下:
- <span style="font-family:Arial;font-size:18px;"><span style="font-size:18px;">
-
-
-
- EXAMPLE=.
- TOOLS=//../build/tools
- DATA=.
-
- TRAIN_DATA_ROOT=train/
- VAL_DATA_ROOT=val/
-
-
-
-
-
- RESIZE=true
- if $RESIZE; then
- RESIZE_HEIGHT=256
- RESIZE_WIDTH=256
- else
- RESIZE_HEIGHT=0
- RESIZE_WIDTH=0
- fi
-
- if [ ! -d "$TRAIN_DATA_ROOT" ]; then
- echo "Error: TRAIN_DATA_ROOT is not a path to a directory: $TRAIN_DATA_ROOT"
- echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
- "where the ImageNet training data is stored."
- exit 1
- fi
-
- if [ ! -d "$VAL_DATA_ROOT" ]; then
- echo "Error: VAL_DATA_ROOT is not a path to a directory: $VAL_DATA_ROOT"
- echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
- "where the ImageNet validation data is stored."
- exit 1
- fi
-
- echo "Creating train lmdb..."
-
- GLOG_logtostderr=1 $TOOLS/convert_imageset \
- --resize_height=$RESIZE_HEIGHT \
- --resize_width=$RESIZE_WIDTH \
- --shuffle \
- $TRAIN_DATA_ROOT \
- $DATA/train.txt \
- $EXAMPLE/train_lmdb
-
- echo "Creating val lmdb..."
-
- GLOG_logtostderr=1 $TOOLS/convert_imageset \
- --resize_height=$RESIZE_HEIGHT \
- --resize_width=$RESIZE_WIDTH \
- --shuffle \
- $VAL_DATA_ROOT \
- $DATA/val.txt \
- $EXAMPLE/val_lmdb
-
- echo "Done."</span></span>
通过运行上面的脚本,我们即将得到文件夹train_lmdb\val_lmdb:
我们打开train_lmdb文件夹

并查看一下文件data.mdb数据的大小,如果这个数据包好了我们所有的训练图片数据,查一下这个文件的大小是否符合预期大小,如果文件的大小才几k而已,那么就代表你没有打包成功,估计是因为路径设置错误。我们也可以通过如下的代码读取上面打包好的数据,把图片、和标签打印出来,查看一下,查看lmdb数据请参考下面的代码:
python lmdb数据验证:
- <span style="font-family:Arial;font-size:18px;"><span style="font-size:18px;">
- caffe_root = '/home/hjimce/caffe/'
- import sys
- sys.path.insert(0, caffe_root + 'python')
- import caffe
-
- import os
- import lmdb
- import numpy
- import matplotlib.pyplot as plt
-
-
- def readlmdb(path,visualize = False):
- env = lmdb.open(path, readonly=True,lock=False)
-
- datum = caffe.proto.caffe_pb2.Datum()
- x=[]
- y=[]
- with env.begin() as txn:
- cur = txn.cursor()
- for key, value in cur:
-
- datum.ParseFromString(value)
-
- img_data = numpy.array(bytearray(datum.data))\
- .reshape(datum.channels, datum.height, datum.width)
- print img_data.shape
- x.append(img_data)
- y.append(datum.label)
- if visualize:
- img_data=img_data.transpose([1,2,0])
- img_data = img_data[:, :, ::-1]
- plt.imshow(img_data)
- plt.show()
- print datum.label
- return x,y</span></span>
通过上面的函数,我们可以是读取相关的lmdb数据文件。
4、制作均值文件。
这个是为了图片归一化而生成的图片平均值文件,把所有的图片相加起来,做平均,具体的脚本如下:
-
-
-
-
- EXAMPLE=.
- DATA=train
- TOOLS=../../build/tools
-
- $TOOLS/compute_image_mean $EXAMPLE/train_lmdb \ #train_lmdb是我们上面打包好的lmdb数据文件
- $DATA/imagenet_mean.binaryproto
-
- echo "Done."
运行这个脚本,我们就可以训练图片均值文件:imagenet_mean.binaryproto
至此,我们得到了三个文件:imagenet_mean.binaryproto、train_lmdb、val_lmdb,这三个文件就是我们最后打包好的数据,这些数据我们即将作为caffe的数据输入数据格式文件,把这三个文件拷贝出来,就可以把原来还没有打包好的数据删了。这三个文件,我们在caffe的网络结构文件,数据层定义输入数据的时候,就会用到了:
- name: "CaffeNet"
- layers {
- name: "data"
- type: DATA
- top: "data"
- top: "label"
- data_param {
- source: "train_lmdb"#lmbd格式的训练数据
- backend: LMDB
- batch_size: 50
- }
- transform_param {
- crop_size: 227
- mirror: true
- mean_file:"imagenet_mean.binaryproto"#均值文件
-
- }
- include: { phase: TRAIN }
- }
- layers {
- name: "data"
- type: DATA
- top: "data"
- top: "label"
- data_param {
- source: "val_lmdb"#lmdb格式的验证数据
- backend: LMDB
- batch_size: 50
- }
- transform_param {
- crop_size: 227
- mirror: false
- mean_file:"imagenet_mean.binaryproto"#均值文件
- }
- include: { phase: TEST }
- }
二、h5py格式数据
上面的lmdb一般用于单标签数据,图片分类的时候,大部分用lmdb格式。然而假设我们要搞的项目是人脸特征点识别,我们要识别出68个人脸特征点,也就是相当于136维的输出向量。网上查了一下,对于caffe多标签输出,需要使用h5py格式的数据,而且使用h5py的数据格式的时候,caffe是不能使用数据扩充进行相关的数据变换的,很是悲剧啊,所以如果caffe使用h5py数据格式的话,需要自己在外部,进行数据扩充,数据归一化等相关的数据预处理操作。
1、h5py数据格式生成
下面演示一下数据h5py数据格式的制作:
-
- caffe_root = '/home/hjimce/caffe/'
- import sys
- sys.path.insert(0, caffe_root + 'python')
- import os
- import cv2
- import numpy as np
- import h5py
- from common import shuffle_in_unison_scary, processImage
- import matplotlib.pyplot as plt
-
- def readdata(filepath):
- fr=open(filepath,'r')
- filesplit=[]
- for line in fr.readlines():
- s=line.split()
- s[1:]=[float(x) for x in s[1:]]
- filesplit.append(s)
- fr.close()
- return filesplit
-
- def sqrtimg(img):
- height,width=img.shape[:2]
- maxlenght=max(height,width)
- sqrtimg0=np.zeros((maxlenght,maxlenght,3),dtype='uint8')
-
- sqrtimg0[(maxlenght*.5-height*.5):(maxlenght*.5+height*.5),(maxlenght*.5-width*.5):(maxlenght*.5+width*.5)]=img
- return sqrtimg0
-
-
- def generate_hdf5():
-
- labelfile =readdata('../data/my_alige_landmark.txt')
- F_imgs = []
- F_landmarks = []
-
-
- for i,l in enumerate(labelfile):
- imgpath='../data/'+l[0]
-
- img=cv2.imread(imgpath)
- maxx=max(img.shape[0],img.shape[1])
- img=sqrtimg(img)
- img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
- f_face=cv2.resize(img,(39,39))
-
- plt.imshow(f_face,cmap='gray')
-
-
- f_face = f_face.reshape((1, 39, 39))
- f_landmark =np.asarray(l[1:],dtype='float')
-
- F_imgs.append(f_face)
-
-
-
- f_landmark=f_landmark/maxx
- print f_landmark
- F_landmarks.append(f_landmark)
-
-
- F_imgs, F_landmarks = np.asarray(F_imgs), np.asarray(F_landmarks)
-
-
- F_imgs = processImage(F_imgs)
- shuffle_in_unison_scary(F_imgs, F_landmarks)
-
-
- with h5py.File(os.getcwd()+ '/train_data.h5', 'w') as f:
- f['data'] = F_imgs.astype(np.float32)
- f['landmark'] = F_landmarks.astype(np.float32)
-
- with open(os.getcwd() + '/train.txt', 'w') as f:
- f.write(os.getcwd() + '/train_data.h5\n')
- print i
-
-
- if __name__ == '__main__':
- generate_hdf5()
利用上面的代码,可以生成一个train.txt、train_data.h5的文件,然后在caffe的prototxt中,进行训练的时候,可以用如下的代码,作为数据层的调用:
- layer {
- name: "hdf5_train_data"
- type: "HDF5Data"
- top: "data"
- top: "landmark"
- include {
- phase: TRAIN
- }
- hdf5_data_param {
- source: "h5py/train.txt"
- batch_size: 64
- }
- }
上面需要注意的是,相比与lmdb的数据格式,我们需要该动的地方,我标注的地方就是需要改动的地方,还有h5py不支持数据变换。
2、h5py数据读取
- f=h5py.File('../h5py/train.h5','r')
- x=f['data'][:]
- x=np.asarray(x,dtype='float32')
- y=f['label'][:]
- y=np.asarray(y,dtype='float32')
- print x.shape
- print y.shape
可以通过上面代码,查看我们生成的.h5格式文件。
在需要注意的是,我们输入caffe的h5py图片数据为四维矩阵(number_samples,nchannels,height,width)的矩阵,标签矩阵为二维(number_samples,labels_ndim),同时数据的格式需要转成float32,用于回归任务。
**********************作者:hjimce 时间:2015.10.2 联系QQ:1393852684 原创文章,转载请保留原文地址、作者等信息***************























 2184
2184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









