







什么是栈
栈本质是表,只不过其限制了插入和删除都在一个位置上进行,这个位置是表的末端,称之为栈顶。栈也被称作后进先出(LIFO:Last In First Out)表。
栈的模型
栈是一种抽象型数据模型,以下就是栈的模型,每次数据进栈都会添加到栈顶(top),每次访问只能访问栈顶的数据
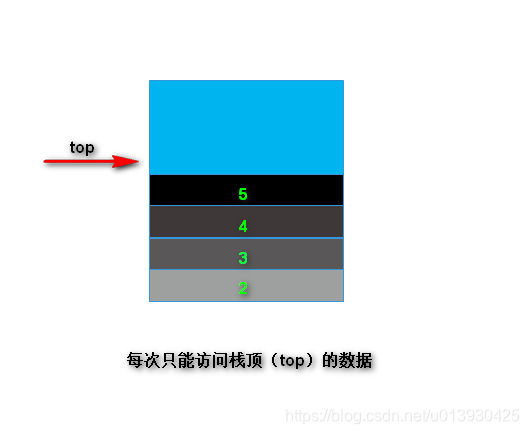
因为栈的本质是表,所以可以通过数组或者链表进行实现。
操作
进栈:private boolean push(E e)
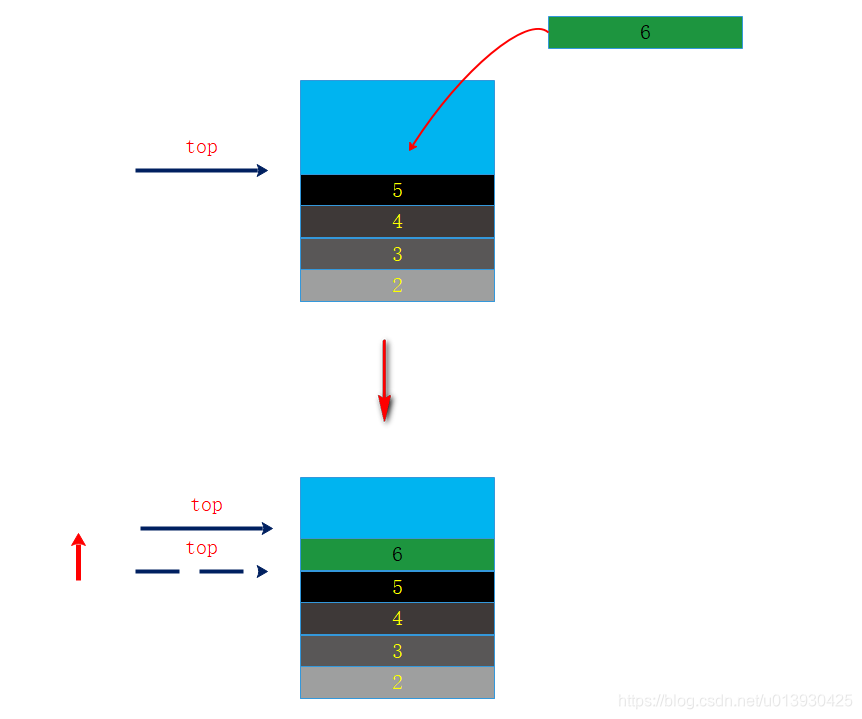
进栈也称之为压栈,将对象或者数据压入栈中,更新栈顶指针,使其指向最后入栈的对象或数据。
出栈:private E pop()
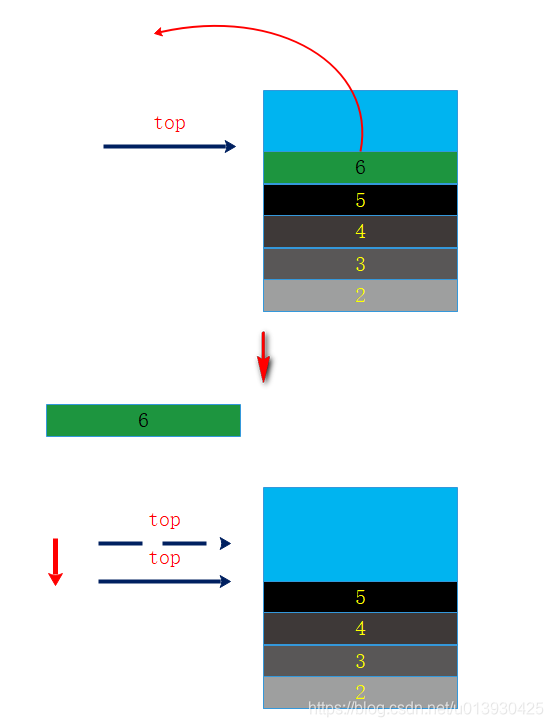
出栈也称之为弹栈,返回栈顶指向的对象或数据,并从栈中删除该对象或数据,更新栈顶。
获取栈顶元素: public E peek()
直接获取栈属性表的最后一个元素即可。
判断栈是否为空:public boolean isEmpty()
判断栈中属性表是否存在元素即可。
获取栈中的元素数目:public boolean size()
直接返回栈属性表的大小。
置空栈:public void empty()
直接调用栈属性表的 clear() 方法即可。
完整代码
package com.qucheng.qingtian.wwjd.datastructure;
/**
* 栈
*
* @author 阿导
* @CopyRight 万物皆导
* @Created 2019-12-06 12:07:00
*/
public class DaoStack<E> {
/**
* 声明表,这里通过链表来实现
*/
private DaoLinkedList<E> list;
public DaoStack() {
this.list = new DaoLinkedList<>();
}
/**
* 进栈
*
* @param e
* @return boolean
* @author 阿导
* @time 2019/12/6 :00
*/
public boolean push(E e) {
return this.list.add(e);
}
/**
* 出栈
*
* @return E
* @author 阿导
* @time 2019/12/6 :00
*/
public E pop() {
if(this.list.size()>0) {
return this.list.remove(this.list.size() - 1);
}
throw new RuntimeException("栈已空,无元素可出栈");
}
/**
* 返回栈顶元素
*
* @return E
* @author 阿导
* @time 2019/12/6 :00
*/
public E peek() {
if (this.list.size() > 0) {
return this.list.getData(this.list.size() - 1);
}
return null;
}
/**
* 判断栈是否为空
*
* @return boolean
* @author 阿导
* @time 2019/12/6 :00
*/
public boolean isEmpty() {
return this.list.isEmpty();
}
/**
* 获取栈的大小
*
* @return int
* @author 阿导
* @time 2019/12/6 :00
*/
public int size() {
return this.list.size();
}
/**
* 置空栈
*
* @author 阿导
* @time 2019/12/6 :00
* @return void
*/
public void empty(){
this.list.clear();
}
}
栈的应用
逆序输出 :输出次序与处理过程颠倒;递归深度和输出长度不易知道。
这个利用栈的后进先出的特点,将给定的字符串进行逆序输出,如输入 abcde,将字母依次进栈,然后出栈,输出为 edcba。具体代码如下:
public class DaoStack<E> {
/**
* 逆序输出
*
* @author 阿导
* @time 2019/12/10 :00
* @return void
*/
private static void reverse(){
String s="abcde";
DaoStack<Character> daoStack = new DaoStack();
for(char c:s.toCharArray()){
daoStack.push(c);
}
while (!daoStack.isEmpty()){
System.out.print(daoStack.pop());
}
}
}
递归嵌套:具有自相似性的问题可递归描述,但分支位置和嵌套深度不固定。
这里主要应用于括号匹配问题和栈混洗问题。
-
括号匹配问题:如我们在开发代码的时候,括号都是对称的,编译器怎么判断括号是否对称?我们可以这样做,每次输入 “(”进栈,当输入“)”就出栈,这样要是栈中还存在“(”就会报丢失括号。或者栈中没有“(” 就输入 “)” 则会提示缺少 “(”。
-
栈混洗:栈混洗的概念是说给定三个栈 A、B、S,其中 B,S 初始是空栈,A 是需要被栈混洗的栈,整个流程的操作只允许 A 出栈的元素入栈 S,S 出栈的元素入栈 B,最后将栈 A 中所有元素都转移到 栈 B ,这样就完成了对栈 A 的一次混洗。在这里我们需要了解一下栈混洗的甄别。
- 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。
我们分析以下这个问题:这个问题可以用栈混洗来解决,如果下一个弹出的数字刚好是辅助栈S的栈顶数字,那么直接弹出。如果下一个弹出的数字不在栈顶,我们把压栈序列中还没有入栈的数字压入S中,直到把下一个需要弹出的元素压入栈顶为止。如果所有元素都压入了栈还没有找到下一个弹出的数字,那么该序列就不是一个栈混洗。下面给出 java 代码。
public class DaoStack<E> {
/**
* 栈混洗
*
* @author 阿导
* @time 2019/12/10 :00
* @return void
*/
private static void stackShuffle() {
// 待入栈的序列
String a = "abcdefg";
// 待检测的序列
String b = "gefdcba";
// 栈 S
DaoStack<Character> ss = new DaoStack<>();
// 栈 A
DaoStack<Character> as = new DaoStack<>();
// 栈 B
DaoStack<Character> bs = new DaoStack<>();
// 长度都不一样,定然不是栈混洗
if (a.length() != b.length()) {
System.out.println("a 和 b 长度不一致,显然不是栈混洗。");
}
// 先将 a 进 栈 A
for (char ac : a.toCharArray()) {
as.push(ac);
}
// 然后进行栈甄别
for (char bc : b.toCharArray()) {
// 栈甄别递归(核心)
Character temp = doStackShuffleCore(ss, as, bc);
// 返回 null 跳出循环
if (temp == null) {
break;
}
// 入栈 B
bs.push(temp);
}
// 长度相等,定然是栈混洗
if (a.length() == bs.size()) {
System.out.println("a 和 bs 长度一致,是栈混洗。");
} else {
System.out.println("a 和 bs 长度不一致,显然不是栈混洗。");
}
}
/**
* 嵌套递归
*
* @author 阿导
* @time 2019/12/10 :00
* @param ss 栈 S
* @param as 栈 A
* @param bc 比对值
* @return java.lang.Character
*/
private static Character doStackShuffleCore(DaoStack<Character> ss, DaoStack<Character> as, char bc) {
// 若栈顶元素不等于 bc 继续递归
if (ss.isEmpty() || !ss.peek().equals(bc)) {
// 若栈 A 已空,仍然不能匹配,则直接返回
if (as.isEmpty()) {
return null;
}
// A 出栈 , S 入栈
ss.push(as.pop());
// 继续甄别
return doStackShuffleCore(ss, as, bc);
}
// 出栈
return ss.pop();
}
}
延迟缓冲:在线性扫描算法模式中,在预读足够长之后,方能确定可处理的前缀。
在一些应用问题中,输入可以分解为多个单元并通过迭代依次扫描处理,但过程中的各步计算往往滞后于扫描的速度,需要待到必要的信息完整到一定程度之后,才能做出判断并实施计算。在此类场合中,栈结构则可以扮演数据缓冲区的角色。比如算数中的优先级比较,先找出优先级最高的运算,当出栈的时候遇到较低的运算,先放入临时栈延后处理,等优先级较高的运算执行玩再执行,这里不多做解释了。
栈式计算:基于栈结构的特定计算模式。
逆波兰法(后缀表达式):将运算符写在操作数之后
这个场景也比较常见,我这边举个例子进行描述,不再写 java 代码了,就是想偷个懒,请谅解。
比如我们要计算:23+5+67=?
那么我们将这种操作的顺序书写如下:2 3 * 5 + 6 7 * +
-
执行操作的时候,依次出栈2,3后然后出栈第一个运算符 *,计算出结果为 6,然后入栈,序列为: 6 5 + 6 7 * +
-
再次出栈数字序列为 6,5,运算符为+,则计算结果为 11,入栈后序列为 11 6 7 * +
-
再次出栈数字序列为 11,6,7 运算符为 *,那么计算运算符最近的两个数字,结果为 42,将 11,42 入栈,序列为 11 42 +
-
最后一次出栈数字为11,42,运算符为 +,运算结果为 53
最小栈
最小栈和原来的栈相比就是能够返回栈中的最小值,实现起来相对比较简单,就加一个辅助栈记录最小值入栈即可,具体代码如下(辅助栈的大小一定和主栈相等吗?)。
/**
* 最小栈
*
* @author 阿导
* @time
* @copyRight 万物皆导
*/
class MiniDaoStack<E> {
/**
* 主栈
*/
private DaoStack<E> mainStack;
/**
* 寻找最小栈辅助类
*/
private DaoStack<E> minStack;
public MiniDaoStack() {
this.mainStack = new DaoStack<>();
this.minStack = new DaoStack<>();
}
/**
* 入栈
*
* @param e
* @return boolean
* @author 阿导
* @time 2019/12/10 :00
*/
public boolean push(E e) {
boolean status = mainStack.push(e);
if (status && (minStack.isEmpty() || minStack.peek().hashCode() >= e.hashCode())) {
status = minStack.push(e);
}
return status;
}
/**
* 出栈
*
* @return E
* @author 阿导
* @time 2019/12/10 :00
*/
public E pop() {
E e = mainStack.pop();
if (e.equals(minStack.peek())) {
minStack.pop();
}
return e;
}
/**
* 获取栈顶数据
*
* @return E
* @author 阿导
* @time 2019/12/10 :00
*/
public E top() {
return mainStack.peek();
}
/**
* 获取最小的元素
*
* @return E
* @author 阿导
* @time 2019/12/10 :00
*/
public E getMin() {
return minStack.peek();
}
}
栈排序
实现排序核心是怎么利用一个辅助的栈巧妙进出栈达到排序的效果,直接给代码
public class DaoStack<E> {
/**
* 从小到大排序
*
* @author 阿导
* @time 2019/12/10 :00
* @param daoStack
* @return com.qucheng.qingtian.wwjd.datastructure.DaoStack<java.lang.Integer>
*/
private static DaoStack<Integer> sortNumber(DaoStack<Integer> daoStack) {
// 声明结果
DaoStack<Integer> rs = new DaoStack<>();
// 循环条件直到给定的栈出栈结束
while (!daoStack.isEmpty()) {
Integer cur = daoStack.pop();
// 这里进行找寻到结果栈比给定栈小的位置,这步很关键
while (!rs.isEmpty() && rs.peek() > cur) {
daoStack.push(rs.pop());
}
// 栈顶数据小于等于当前给定栈定数据,直接入栈
rs.push(cur);
}
// 返回排序后的结果
return rs;
}
}
两个栈实现一个队列
这边阿导还没有进入队列的专题,这边不对队列进行详细介绍,只说一下队列的特性 FIFO(First In First Out,即先进先出),所以通过两个栈实现队列核心就是保证数据的先进先出,直接撸代码,具体说明会在注释中进行讲解(主要理解出队列的两个 while 的写法即可)。
/**
* 两个栈实现队列
*
* @author 阿导
* @time
* @copyRight 万物皆导
*/
class DaoStackQueue<E> {
/**
* 入队列保存的栈
*/
private DaoStack<E> inStack = new DaoStack<>();
/**
* 出队列操作的栈
*/
private DaoStack<E> outStack = new DaoStack<>();
/**
* 构造方法
*
* @param inStack
* @param outStack
* @return
* @author 阿导
* @time 2019/12/10 :00
*/
public DaoStackQueue(DaoStack<E> inStack, DaoStack<E> outStack) {
this.inStack = inStack;
this.outStack = outStack;
}
/**
* 进队
*
* @param e
* @return void
* @author 阿导
* @time 2019/12/10 :00
*/
public void enter(E e) {
// 直接添加到入栈里
inStack.push(e);
}
/**
* 出队
*
* @return E
* @author 阿导
* @time 2019/12/10 :00
*/
public E exit() {
// 如果 outStack 不为空,直接从 outStack 里面弹栈返回即可
while (!outStack.isEmpty()) {
return outStack.pop();
}
// 要是 outStack 为空,且 inStack 不为空,则将 inStack 弹栈出的元素压栈到 outStack
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
// 最后返回数据
return outStack.pop();
}
}
延伸
大家都清楚再 Java 内存中包含堆、栈、方法区,这里只延伸栈的知识。首先我们思考下面几个问题
- Java 栈里面存储了什么内容?为什么要存储这些东西?
栈里面存储的内容如下:
-
存放基本变量类型,包含这个基本类型的具体数值
-
引用对象的变量,会存放这个引用再堆里面的具体地址
JVM 基本架构就是采用栈进行来设计的。程序需要运行的时候,由于要预先内存空间和运行的生命周期,所以需要进行指针的变动,来进行内存大小的分配。因为这个操作会对程序的执行带来一定的不方便,所以一般栈被用来存放一些基本的变量类型或者引用对象的地址,而对于存储数据量较为庞大的 java 对象责备存储在了堆里面了。
- 为什么说栈的提取速度比堆要快?
-
栈里面的内存大小一般都是程序启动的时候由系统分配好的。
-
堆的内存大小需要在使用的时候才回去申请,而且每次对于内存大小的申请和归还都会比较消耗性能,开销较大。
-
cpu 里面会有专门的寄存器来操作栈,堆里面都是使用间接寻址的方式来进行对象查找的,所以栈会快一些。
- 虚拟机栈数据有共享一说吗?
在概念模型中,两个栈帧是完全独立的,但是在虚拟机的实现里会做一些优化处理,令两个栈帧出现一部分重叠。这样在进行方法调用时,就可以共用一部分数据,无须进行额外的参数复制传递。
另外网上有人举例 int i=10,j=10,说 i 和 j 共享一个栈里面的数据,阿导认为这个解释有点牵强,栈帧里面包含了局部变量表和操作数栈,阿导认为若是他们有重叠部分,则会有共享情况发生,因为这样优化无须做额外参数复制传递。
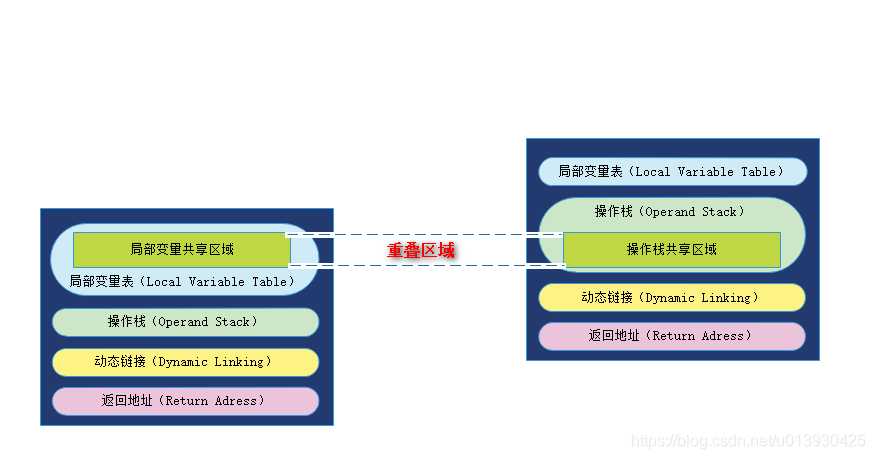
- 栈帧里面包含哪些信息
栈帧是用于支持虚拟机进行方法调用和方法执行的数据结构,它位于虚拟机栈里面,每个栈帧包含信息如下图所示。

- 局部变量表(Local Variable Table)
这里面的作用主要是存储一系列的变量信息,而且这些变量都是以数字数组的形式来存储的,一般而言 byte,short,char,类型的数据在存储的时候会变为 int 类型,boolean 类型也是存储为数字类型,long,double 则是转换为双字节大小的控件存储在栈里面。
-
操作数栈(Openrand Stack)
2.1 与局部变量表一样,均以字长为单位的数组。不过局部变量表用的是索引,操作数栈是弹栈/压栈来访问。操作数栈可理解为java虚拟机栈中的一个用于计算的临时数据存储区。
2.2 存储的数据与局部变量表一致含int、long、float、double、reference、returnType,操作数栈中byte、short、char压栈前(bipush)会被转为int。2.3 数据运算的地方,大多数指令都在操作数栈弹栈运算,然后结果压栈。
2.4 java虚拟机栈是方法调用和执行的空间,每个方法会封装成一个栈帧压入占中。其中里面的操作数栈用于进行运算,当前线程只有当前执行的方法才会在操作数栈中调用指令(可见java虚拟机栈的指令主要取于操作数栈)。
2.5 int类型在-15、-128127、-3276832767、-21474836482147483647范围分别对应的指令是iconst、bipush、sipush、ldc(这个就直接存在常量池了)
-
动态链接(Dynamic Linking)
动态链接的作用主要还是提供栈里面的对象在进行实例化的时候,能够查找到堆里面相应的类地址,并进行引用。这一整个过程,我们称之为动态链接。
- 返回地址(Return Adress)
某个子方法执行完毕之后,需要回到主方法的原有位置继续执行程序,方法出口主要就是记录该信息















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









