






文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解Spark的背景;
⚪ 了解Spark的特点;
⚪ 掌握Spark的生态系统模块、使用模式;
⚪ 掌握Spark的单机模式安装;
一、简介
1. 背景
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的,后贡献给Apache。是一种快速、通用、可扩展的大数据分析引擎。它是不断壮大的大数据分析解决方案家族中备受关注的明星成员,为分布式数据集的处理提供了一个有效框架,并以高效的方式处理分布式数据集。Spark集批处理、实时流处理、交互式查询、机器学习与图计算于一体,避免了多种运算场景下需要部署不同集群带来的资源浪费。目前,Spark社区也成为大数据领域和Apache软件基金会最活跃的项目之一,其活跃度甚至远超曾经只能望其项背的Hadoop。
2. 特点
Spark是一种分布式的、快速的、通用的、可靠的、免费的计算框架。
目前市面上比较常用和流行的计算框架:
1. Hadoop Map Reduce->离线批处理;
2. Spark->离线批处理->实时流处理;
3. Storm->实时流处理;
4. Flink->实时流处理;

从上图可以看出,MapReduce在执行任务时,底层会发生Shuffle过程,则会产生大量和多次的磁盘I/O,拉低性能。并且在Shuffle过程会针对每个分区内的数据做排序,耗费大量的CPU,拉低性能。此外,在做一次迭代性质算法的场景下,比如梯度下降法,逻辑回归等时,需要重复的用到某些中间步结果集。由于不能做到中间结果集的复用,会带来大量的重新计算代价。
Spark团队吸取了以上Map Reduce的一些经验教训,做出了相关优化。比如尽量减少Shuffle过程生产,减少不必要的排序以及支持缓存机制,达到中间结果集的复用。
二、Spark的生态系统模块
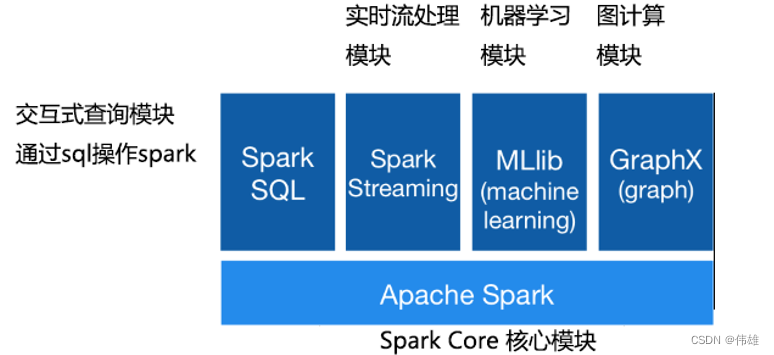
上图是Spark的整个生态系统。可以看出Spark涵盖了大数据处理的各种应用场景:
1. 离线批处理;
2. 交互式查询和数仓;
3. 实时流处理;
4. 算法建模和数据挖掘;
即Spark可以一线式处理大数据的所有应用场景,避免部署多种不同的集群带来的麻烦。
三、Spark的使用模式
1. 常见的使用模式三种:
1. Local 本地单机模式:一般用于测试或练习;
2. Standalone Spark集群模式:Spark集群的资源管理由Spark自己来负责;
3. On Yarn Spark集群模式:Spark集群的资源管理由Yarn来管理。
2. Spark单机模式安装:
1. 安装和配置好JDK
2. 上传和解压Spark安装包
3. 进入Spark安装目录下的conf目录
复制conf spark-env.sh.template 文件为 spark-env.sh
在其中修改,增加如下内容:
SPARK_LOCAL_IP=服务器IP地址(主机名)
4. 进入 Spark 的 bin 目录,执行:
sh spark-shell --master=local

5. 退出:ctrl + c。
四、练习任务
1. 有一个文件,文件中存储了40亿个整型数字,没有重复出现的。
# 要求找出有哪些数字没有出现过,并且内存使用不能超过2GB。
# Int的范围将近43亿个数字,而文件中有40亿个数字,肯定有一些数字是没有出现过的。
#如果用整型数组存40亿个数字,此时内存占用:15GB,不符合要求。















 251
251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









