







近年来,随着大型语言模型(LLMs)的快速发展,如何有效利用这些模型进行复杂任务的推理成为了研究热点。其中,链式思考(Chain-of-Thought, CoT)推理方法作为一种有效的策略,能够显著提升LLMs在逻辑推理、数学计算等领域的表现。然而,传统CoT方法依赖于大量的人工示例或预定义模板,这限制了其在实际应用中的灵活性和可扩展性。本文将深入解读一篇关于自动优化CoT推理的论文《Self-Harmonized Chain-of-Thought Prompts for LLMs》,特别是该论文中提出的ECHO(Efficient Chain-of-Thought Optimization)方法,并通过图文并茂的方式,为大家呈现这一创新方法的精髓。
论文背景与动机
CoT推理简介
CoT推理方法的核心思想是引导LLMs在给出最终答案之前,先生成一系列中间推理步骤。这种方法能够显著提高LLMs在解答复杂问题时的准确性和透明度。然而,传统CoT方法存在两大挑战:一是需要大量高质量的人工示例,这既耗时又费力;二是人工示例往往难以覆盖所有可能的推理路径,导致模型泛化能力不足。
ECHO方法的提出
针对上述挑战,本文提出了ECHO方法,旨在通过自动生成的多样化示例来优化CoT推理过程。ECHO方法不仅能够自动生成高质量的示例,还能通过迭代更新这些示例,逐步统一并优化推理模式,从而提高LLMs的推理能力。
ECHO方法详解
方法概述
ECHO方法主要包含三个核心步骤:问题聚类、示例采样和动态优化。
- 问题聚类:首先,将给定数据集中的问题根据相似度进行聚类,以识别出不同的问题类型或推理模式。
- 示例采样:在每个聚类中选择一个代表性问题,并使用Zero-shot-CoT方法生成其推理链。这些推理链将作为初始示例。
- 动态优化:通过迭代更新这些示例来优化推理过程。在每次迭代中,随机选择一个示例,并使用当前最新的LLM模型重新生成其推理链。新生成的推理链将替换旧的推理链,从而逐步统一并优化整个示例集。
图解ECHO方法

图1:ECHO方法与其他CoT基线方法的比较
图1展示了ECHO方法与其他CoT基线方法(如Zero-shot-CoT和Few-shot-CoT)的比较。可以看出,ECHO方法通过自动生成并优化多样化示例,能够在没有大量人工标注数据的情况下,显著提升LLMs的推理性能。
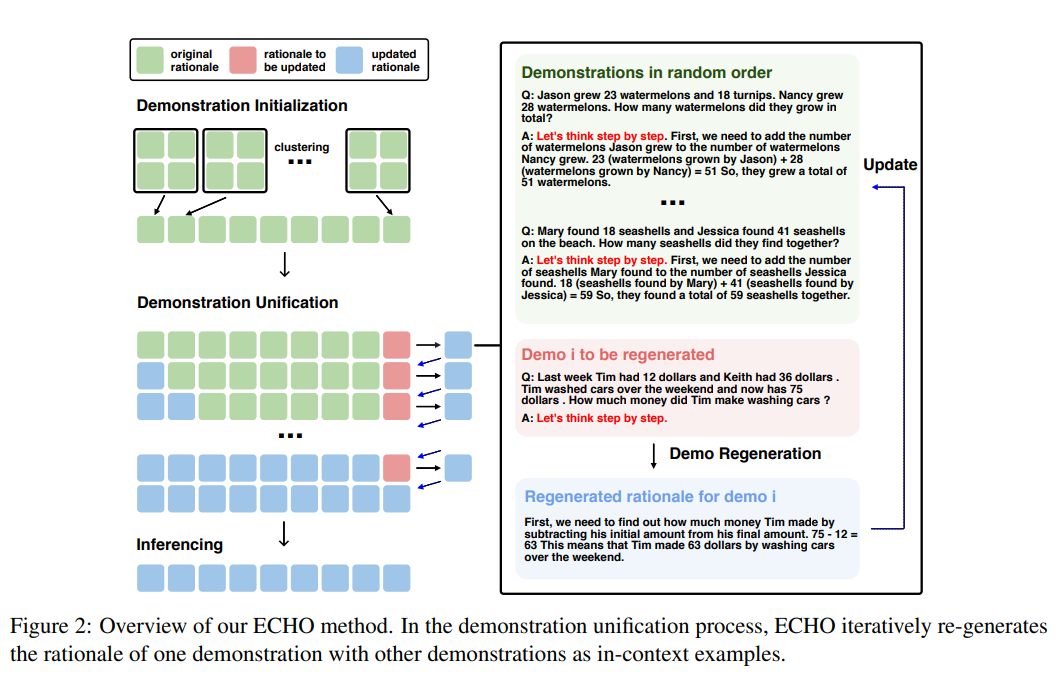
图2:ECHO方法的主要步骤
图2详细展示了ECHO方法的主要步骤。首先,将数据集中的问题聚类成几个相似的组。然后,从每个组中选择一个代表性问题,并使用Zero-shot-CoT方法生成其推理链。接下来,通过迭代更新这些推理链,逐步统一和优化示例集。最后,将优化后的示例集用于指导LLMs进行CoT推理。
算法实现

ECHO方法的算法实现如算法1所示。该算法首先通过聚类算法将问题分组,并在每个组中选择一个代表性问题。然后,使用Zero-shot-CoT方法生成这些代表性问题的推理链。接下来,进入迭代优化阶段,每次迭代中随机选择一个示例进行更新,并使用当前最新的LLM模型重新生成其推理链。最后,根据需要调整示例集的大小以匹配推理时的需求。
实验结果与分析
实验设置
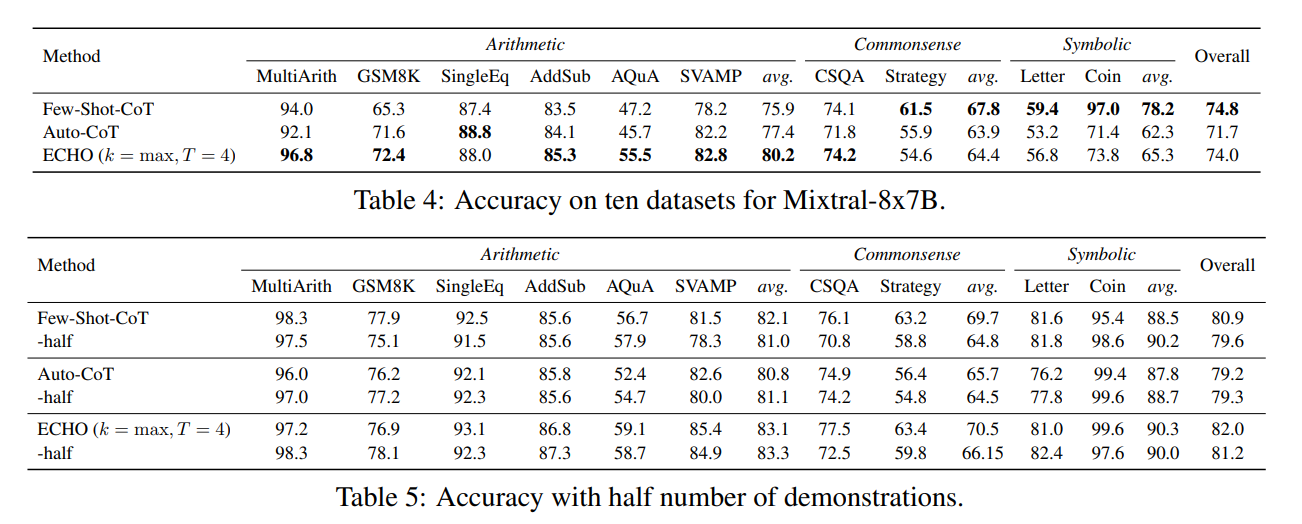
本文在多个推理领域的数据集上进行了实验,包括常识推理、数学计算、策略问答等。实验中使用了GPT-3.5-Turbo-0301模型作为主要测试对象,并验证了ECHO方法在不同模型上的通用性。
性能提升显著
实验结果表明,ECHO方法在多个推理任务上均取得了显著的性能提升。与现有的基线方法相比,ECHO方法在不同数据集和模型上的平均准确率均有显著提升。这一结果充分证明了ECHO方法的有效性和优越性。
生成的演示质量提升
通过ECHO方法的迭代优化,生成的演示质量得到了显著提升。初始时高度多样化的演示在经过ECHO的统一后,逐渐形成了更加一致和准确的推理模式。这不仅提高了推理的准确性,还降低了因演示错误而导致的误导风险。
泛化能力强
实验还表明,ECHO方法具有较强的泛化能力。在不同类型的推理任务和数据集上,ECHO方法均能保持稳定的性能表现。这一特点使得ECHO方法在实际应用中具有更广泛的应用前景。
总结与展望
本文通过深入解读《Self-Harmonized Chain of Thought》论文中的ECHO方法,详细阐述了其创新点、工作流程以及实验结果。ECHO方法通过自我协调机制将多样化的演示统一成一个通用的推理模式,有效解决了现有CoT方法中的诸多挑战。
论文地址:https://arxiv.org/pdf/2409.04057
GitHub代码库:https://github.com/Xalp/ECHO?spm=5176.28103460.0.0.40f75d27nBIzah
关于个探索LLM中的CoT链式推理:ECHO方法深度解读分享结束,如果对文章感兴趣别忘了点赞、关注噢~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









