







现代语言模型规模庞大,训练成本高昂。例如,训练一个120亿参数的模型大约需要72000 GPU小时。而小型语言模型虽然训练成本低,但准确性往往不足。在这篇论文中,作者提出了一种名为HyperCloning的方法,它可以将预训练的小语言模型的参数扩展到更大模型的参数,同时增加隐藏维度,从而在训练时间和最终准确性方面带来优势。
01
—
HyperCloning 方法
丨**** 1.1 方法目标
- 扩展维度:更大的网络应比小网络有更大的隐藏维度,同时保持层数相同。
- 功能保留:转换后的大模型在最终层的logits应与小模型匹配。
- 低计算开销:从小模型到更大模型的转换过程应简单,避免大量计算或迭代更新。
- 训练循环不变:为便于部署,训练循环应保持不变,仅需修改网络初始化。
丨**** 1.2 核心技术
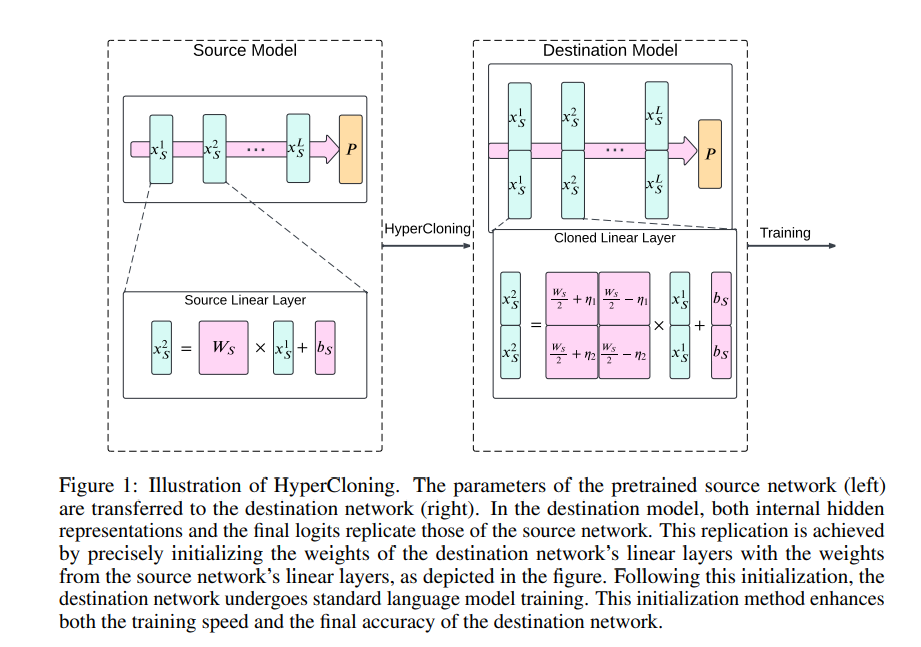
- 向量克隆
- 对于源网络(小模型)中的隐藏表示,通过堆叠n个副本得到n倍克隆版本。
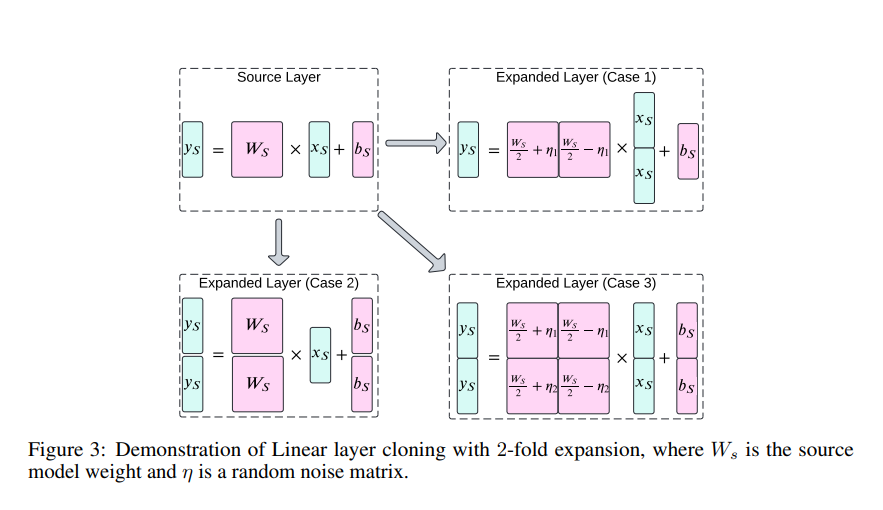
- 对于源网络中的线性层(权重参数为Ws,偏差参数为bs),HyperCloning的目标是在目标网络中获得权重WD和偏差bD,使得输入和输出向量是源网络的克隆版本。根据输入/输出维度的扩展情况,线性层有三种不同的初始化情况(如论文图3所示)。
- 针对不同层的克隆细节
- 线性层
- 当只有输入扩展时(如论文图3中Case 1),相关参数有特定设置。
- 当只有输出扩展时(如论文图3中Case 2),相关参数有特定设置。
- 当输入和输出都扩展时(如论文图3中Case 3),相关参数有特定设置。
- 注意力层
- 当扩展每个注意力头的维度时,查询/键/值矩阵可视为单独的线性层进行扩展,并且需要对查询值进行缩放。
- 当扩展注意力头的数量时,可直接复制注意力头,后续的全连接层也会相应扩展。
- 归一化层
- 克隆层归一化时,扩展仿射参数,可确保扩展后的层归一化输出是原始层归一化输出的克隆版本。
- 位置嵌入层
- 定义n倍克隆的位置嵌入,即通过重复小网络的位置嵌入n次来创建扩展网络的位置嵌入。
- 线性层
02
—
实验
丨**** 2.1 实验设置
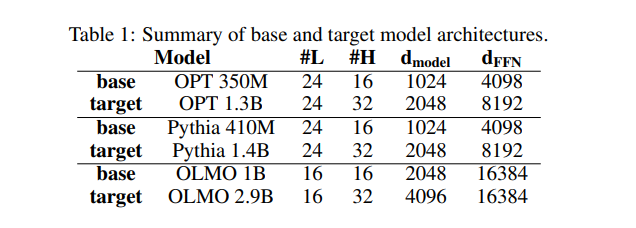
- 模型架构
- 使用三个开源基准模型进行实验:OPT、Pythia和OLMO。选择OPT - 350M、Pythia - 460M和OLMO - 1B作为基础预训练模型,然后使用HyperCloning构建三个更大的架构作为目标网络:OPT - 1.3B、Pythia - 1.4B和OLMO - 2.9B。
- 数据集和训练参数
- 数据集使用由Groeneveld等人提供的DOLMA数据集,包含多个开源数据集,总计达2.4万亿个标记。训练时对数据进行洗牌,保持随机洗牌的种子相同。
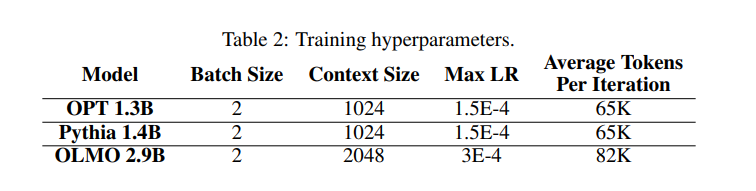
- 训练参数方面,使用AdamW优化器,权重衰减为0.05,β1 = 0.9,β2 = 0.999,采用梯度积累(16步)和zero_2梯度更新算法。学习率进行热身,经过一定迭代后进行衰减并最终保持恒定。不同模型的批量大小、上下文大小和学习率等参数有所不同(如论文表2所示)。
丨**** 2.2 实验结果
- 与随机初始化的比较
- 准确性
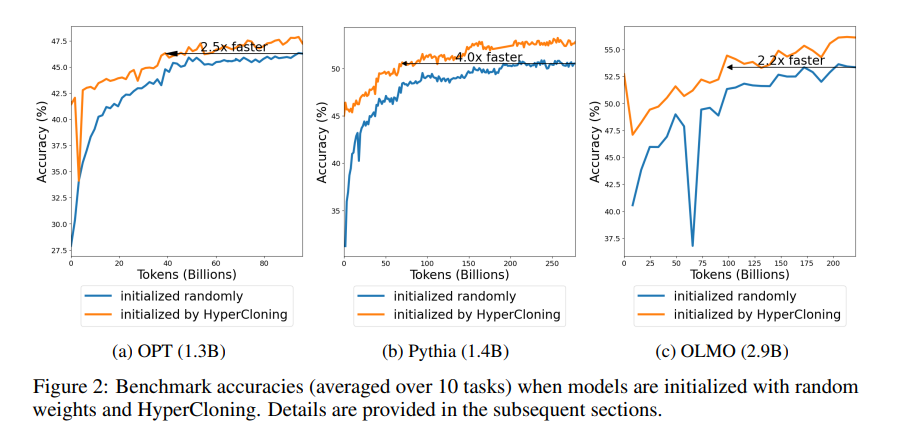
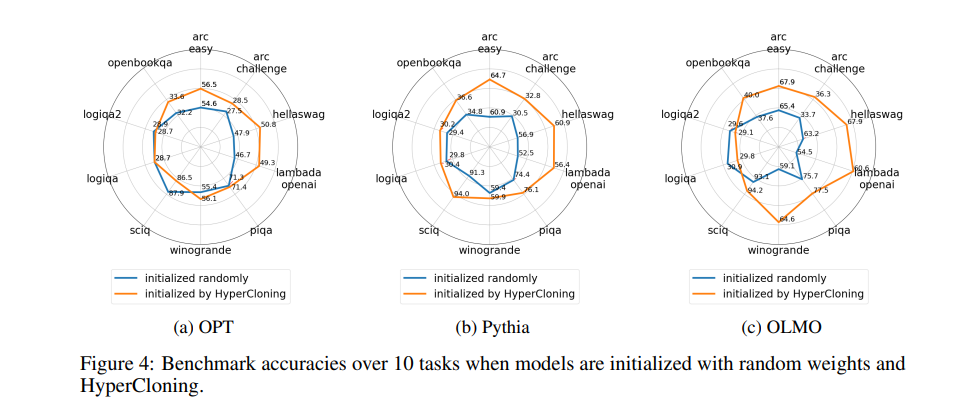
- 使用Harness框架计算模型准确性,在10个不同任务上进行测量。如论文图4所示,HyperCloning显著提高了模型收敛后的准确性。
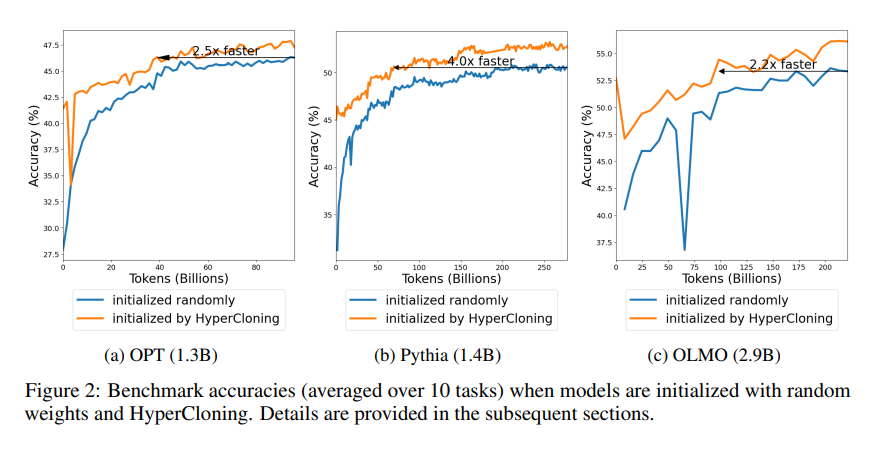
- 如论文图2所示,计算10个工作的平均准确性并展示其在训练过程中的趋势,HyperCloning使网络更快地达到随机初始化基线的最终准确性,加速比在不同模型类型中从2.2倍到4倍不等。这是因为HyperCloning实现了知识从基础模型的转移,例如OLMO架构的基础模型已经在2.4T个标记上进行了训练,这些知识在训练开始前就转移到了目标模型中。
- 准确性
- **灾难性遗忘**
* 模型在使用HyperCloning初始化时,在训练开始时往往会出现灾难性遗忘,例如在OLMO基准测试的训练曲线中可以看到。但经过足够的训练,这种遗忘可以得到补偿,并且HyperCloning仍然大幅优于随机初始化。
- HyperCloning分析
- 权重对称性
- 对于n倍克隆,目标网络中的目标权重由源权重块归一化后初始化,其标准差是源网络权重标准差的1/n。在训练过程中,通过定义度量来评估克隆矩阵的对称性,如论文图5所示,最初所有层的余弦相似度为1,随着训练的进行,大多数层的余弦相似度下降,这表明模型在训练过程中利用了其有效参数空间。
- 主成分分析
- 分析HyperCloning收敛的另一种方法是检查权重矩阵的秩。由于克隆算法的复制性质,克隆矩阵的秩在初始化时最多等于基础矩阵的秩,这意味着模型在初始化时虽有合理准确性,但未充分利用其预测能力。但如论文图6所示,经过训练后,使用HyperCloning初始化的模型实现了与随机初始化模型相似的高秩权重。
- 权重对称性
- 替代扩展方法
- 对几种权重扩展策略进行了实证评估,包括对称、对角、有噪对称和有噪对角等方法。如论文图7所示,所有克隆方法都优于随机初始化,其中对称和有噪对称方法表现最佳,对角方法的准确性提升最小。
- 基础模型准确性的影响
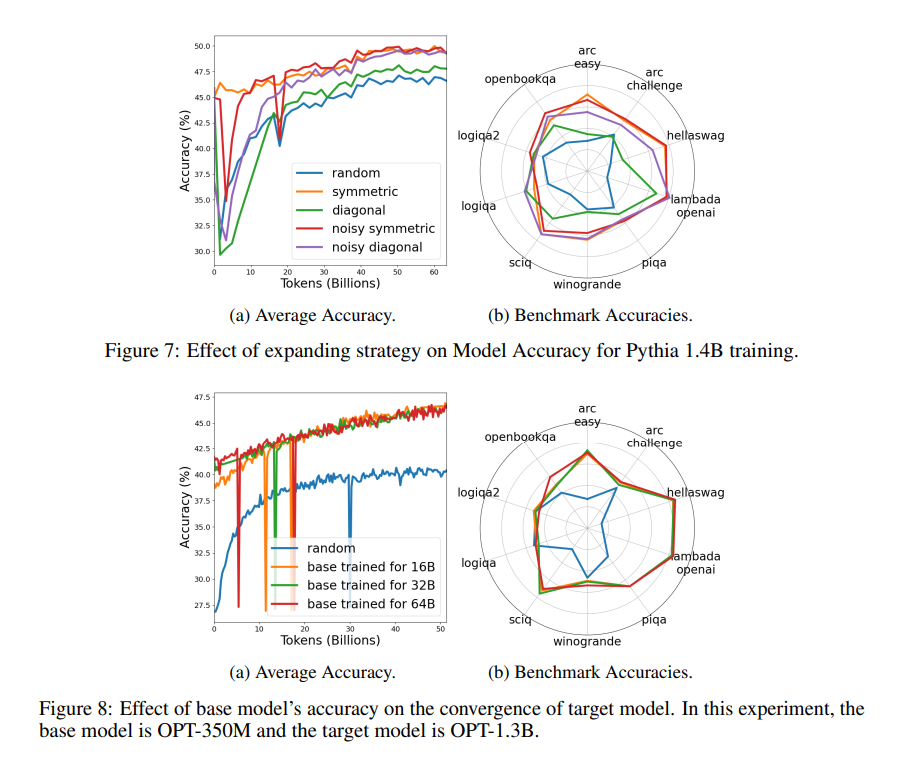
- 使用OPT - 350M基础模型的不同检查点(分别用160亿、320亿和640亿个标记训练)初始化目标OPT - 1.3B模型,并与随机初始化进行比较。如论文图8所示,使用基础模型初始化比随机初始化提高了准确性,并且使用更准确的基础网络初始化的克隆网络在训练开始时准确性更好,但随着训练的进行,曲线之间的差异变小。
- 基础模型大小的影响

- 创建目标模型OPT - 5.3B,通过HyperCloning可以用OPT - 1.3B(2倍克隆)或OPT - 350M(4倍克隆)进行初始化。如论文图9所示,用OPT - 350M或OPT - 1.3B初始化都比随机初始化收敛更快,且OPT - 1.3B的收敛效果比OPT - 350M更好,因为OPT - 1.3B更大且更准确。
03
—
相关工作
- 网络增长文献中的相关研究包括深度和宽度扩展等策略。例如,一些研究通过重复块权重来初始化更大的模型实现深度增长,而在宽度增长方面也有多种策略,但以往研究中的深度和宽度缩放策略大多不保留函数属性。
- 本文在宽度扩展方面进行了创新,将宽度扩展技术推广到解码器式变压器模型,包括对注意力层的扩展以及对位置嵌入的克隆函数定义等,并通过大规模模型和数据集的实验验证了方法的有效性。
- 与其他宽度扩展技术相比,本文的对称初始化方法比一些将扩展权重矩阵非对角元素初始化为零的方法收敛更快,并且通过实验证明了权重对称性在训练过程中会自然打破,同时提出了一种保留功能的噪声添加机制来提高模型收敛率。
本文介绍的HyperCloning是一种新颖的初始化策略,它可以将权重从较小的预训练源模型转移到较大的目标模型,过程简单有效且保留模型功能。通过这种方法,在语言模型训练中实现了更快的收敛和更好的最终准确性,实验中加速比达到2 - 4倍。同时,通过消融研究探索了源模型架构和不同权重克隆技术对目标模型收敛的影响。
论文地址:https://arxiv.org/pdf/2409.12903
原文链接:https://mp.weixin.qq.com/s/hlqvXPe2OcMw3WXv_CdUAQ
关于通过小型模型初始化加速大型语言模型预训练分享结束,如果对文章感兴趣别忘了点赞、关注噢~
















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









