










最近想查看某个weibo主的内容,想着有没有现成的程序可以直接下载的。github上找到了可以使用的程序。将其加载到eclipse中。
dataabc/weibo-crawler: 新浪微博爬虫,用python爬取新浪微博数据,并下载微博图片和微博视频
使用过程中会遇到以下问题:
1.没有找到user_id_list.txt文件,在解压文件中新建该文件,此文件写入weibo的id(自己需要的博主id)。
2.没有提示错误,但是进度条为0。原因有2点,一是确实距离爬取数据的时间过近,博主没有更新。二是修改user_id_list.txt 文件中的内容,把id后面带的时间去除。
关联文件
- weibo-crawler/config.json 中的 "since_date": 1, (可修改,1表示当前下载时间往前推1天)
3.无法工作,提示warning。因为下载图片需要cifar10.py,所以增加cifar10的插件,一般keras或者tensorflow都会需要。可能还会需要其他依赖的插件。
4.别忘记运行此程序需要联网。
5.csv文件乱码,拷贝到其他电脑上,打开的内容是正常。
注意点:
(1)增加一个重点内容:如何找到微博的用户id(user_id)---每次回来用时都忘记mark。
GitHub - dataabc/weibo-follow: 爬取关注列表中微博账号的微博
该作者提供的注释。总结下就是找到某个人的微博号,然后点击其“资料”,查看网址,有一串数字的就是user_id内容。
举例:迪丽热巴 ,其中1669879400就是想要的内容。
https://weibo.cn/1669879400/info(2)(补)使用有效的cookie才能得到200页以上的博文。
之前运行的时候没有发现,如果直接使用这个程序只能扒200页的博文,超过部分无法显示,同时下载图片时还是debug的状态。
处理方法:
config.json文件中的cookie更换为自己的cookie。
如何查看自己的cookie,则是打开网址https://m.weibo.cn/ ,然后chrome网页,右击-检查-网络,然后再次访问这个网址,找到网络中的名称m.weibo.cn的标头,可以看到cookie。
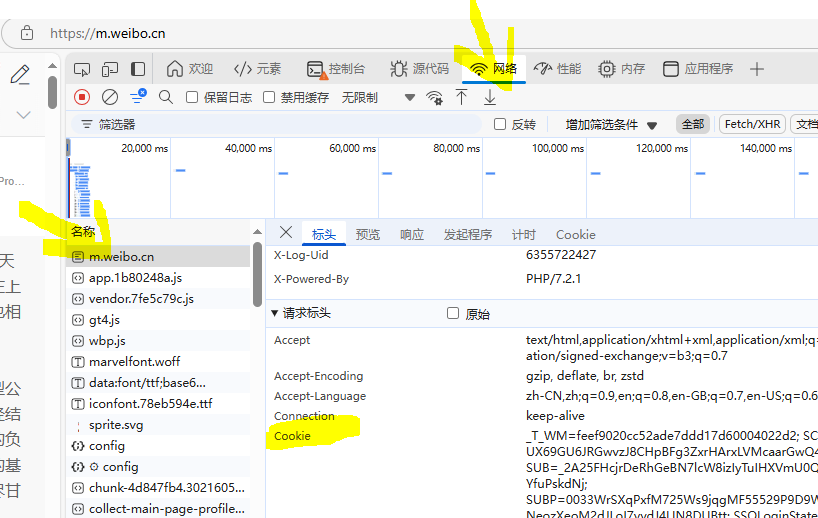
同时注意这个cookie每次刷新会有所变化。需要确认这个cookie是有效的。该作者对这个有进行说明。
dataabc/weibo-crawler: 新浪微博爬虫,用python爬取新浪微博数据,并下载微博图片和微博视频![]() https://github.com/dataabc/weibo-crawler#%E5%A6%82%E4%BD%95%E6%A3%80%E6%B5%8Bcookie%E6%98%AF%E5%90%A6%E6%9C%89%E6%95%88%E5%8F%AF%E9%80%89或者下图(来源--作者dataabc的说明中截图[上面网址的内容])。
https://github.com/dataabc/weibo-crawler#%E5%A6%82%E4%BD%95%E6%A3%80%E6%B5%8Bcookie%E6%98%AF%E5%90%A6%E6%9C%89%E6%95%88%E5%8F%AF%E9%80%89或者下图(来源--作者dataabc的说明中截图[上面网址的内容])。

能够看到提示“cookie检查有效”时,再次抓取200页后面的数据(config.json中的“start_page”改为190页)。
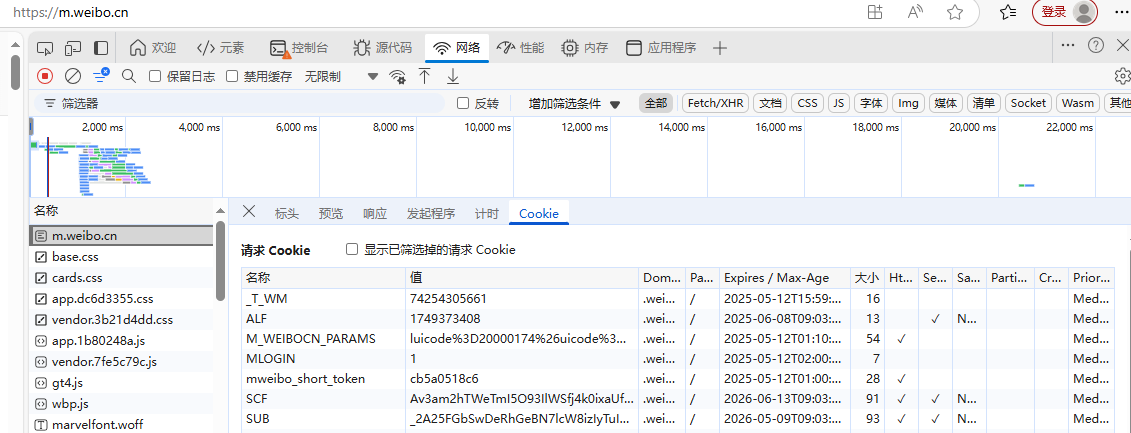
能够看到提示“cookie检查有效”时,再次抓取200页后面的数据(config.json中的“start_page”改为190页)。如果尝试了很多次还是失败,出现错误。那么cookie是有有效期的(见下图的expires/max-age),可以把网页的设置中删除cookies。然后重新对 https://m.weibo.cn/ 登陆,同时查看cookie(参照上面的方法),并且该wb网页不要关闭。

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









