







微博爬虫大多基于移动端网页,因为反爬机制较少,甚至无需登录。本爬虫基于微博移动端网页(m.weibo.cn)接口,无需登录,即可爬取用户历史微博。本文针对爬取逻辑作简要介绍,具体参见源码。
1. 爬取接口
通过过get方式访问
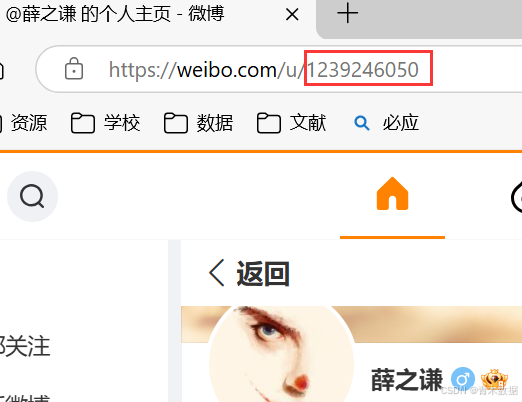
https://m.weibo.cn/api/container/getIndex?type=uid&value=userid&containerid=107603userid,其中userid为要爬取的用户id,可通过访问其主页获取,见下图。其他内容为固定值,无须修改。
2. 解析结果
(1)接口返回格式如下(为方便展示已隐去一部分内容):
{
"ok": 1,
"data": {
"cardlistInfo": {
...
"since_id": 5106892537596106
},
"cards": [
{
...
"mblog": {
...
"created_at": "Tue Oct 15 15:02:18 +0800 2024",
"mid": "5089755503001975",
"text": "为何大型巡演 一到了海外都会选择 大变小 进馆进剧院 减配 速搭台 改内容 等方式来完成演出 一来是运输困难 巨型设备需漂洋过海 二来搭建难题 海外大场地搭台档期工期都会让成本昂贵<br />所以 经过长时间多方面协调<br />请准我 食言这半次…<br />因为这件事 现在的我不做 暮年时 定会遗憾<br />对所有国内的谦友说声抱歉 ...<a href=\"/status/5089755503001975\">全文</a>",
"source": "iPhone 16 Pro Max",
"user": {
"id": 1239246050,
"screen_name": "薛之谦",
...
},
"reposts_count": 1000000,
"comments_count": 229648,
"reprint_cmt_count": 0,
"attitudes_count": 318500,
"isLongText": true,
"pics": [
{
"pid": "001lRKvwgy1hun3ggzy39j61hc219e8102",
"url": "https://wx2.sinaimg.cn/orj360/001lRKvwgy1hun3ggzy39j61hc219e8102.jpg",
...
"large": {
"size": "large",
"url": "https://wx2.sinaimg.cn/large/001lRKvwgy1hun3ggzy39j61hc219e8102.jpg",
...
}
}
]
}
}
],
...
}
}其中每一个“mblog”对象对应一条微博,created_at为发布时间,text为微博文本,user为用户属性相关,pics为微博关连的图片信息,等等。
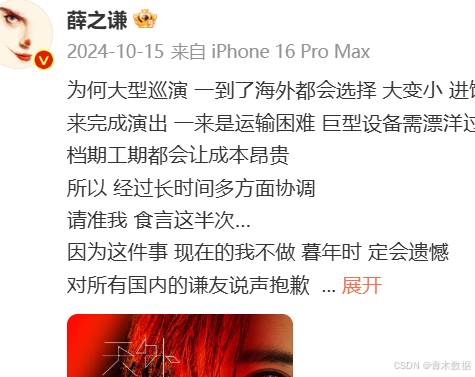
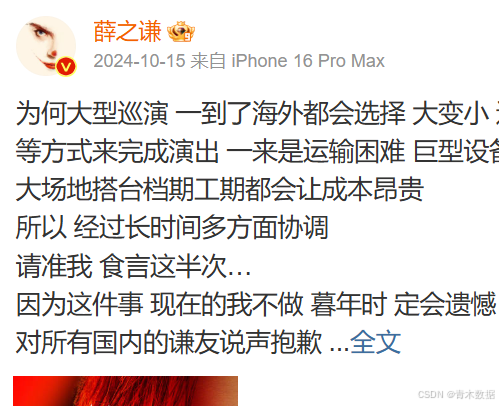
(2)解析微博文本时有两点需要注意,其一是文本包含一些HTML内容,如<br/>以及话题标签与地点信息等,如果只需要纯文本需要编写正则表达式过滤掉这些内容。二是isLongText字段表明该微博是否为长文本,若是则需要单独调用其他接口获取全部文本内容(后续介绍)。长文本内容在接口中显示为“...<a ...>全文</a>”,在页面上显示如下:
(3)爬取图片时有两点需要注意,一是图片清晰度,large字段中的是高清晰度图片,一般是原图,可根据自己实际需求选择清晰度。二是下载图片时需要添加Referer,内含“weibo.com”即可。
def download_file(url, path):
_header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Referer": "https://weibo.com/"
}
res = requests.get(url, headers=_header)
f = open(path, "wb")
f.write(res.content)
f.close()
return
def parse_mblog_pic(userid, mid, pics):
path = os.path.join(get_cur_path(), userid, "pics", f"mid_{mid}")
if os.path.exists(path):
return
os.makedirs(path, exist_ok=True)
for idx, pic in enumerate(pics):
picurl = pic["url"]
if "large" in pic: # 高清大图
picurl = pic["large"]["url"]
download_file(picurl, os.path.join(path, f"{idx+1}.jpg"))
print(f" pic {idx} done!")
sleep(0.05)3. 翻页机制与结束判断
每次调用接口会返回10条微博,那么如何实现更多内容爬取,以及如何判断全部内容爬取完毕呢?不像其他接口中使用page字段,本接口采用since_id字段,该字段由前一次调用返回结果提供,出现在“cardlistInfo”下。如若该字段缺失,可视作爬取完毕。
# 微博移动端接口,无需登录即可爬取
url = f'https://m.weibo.cn/api/container/getIndex?type=uid&value={userid}&containerid=107603{userid}'
while True:
page_url = f'{url}&since_id={sinceid}' if sinceid != "" else url
ret = requests.get(page_url, headers=_header).json()
if 1 != ret["ok"]:
break
# 解析用户微博数据
data = ret["data"]
if "cards" in data:
for card in data["cards"]:
parse_user_mblog(userid, card, save_pic)
print(f" since_id {sinceid} done!")
# sinceid为空时表示数据爬取完成,否则代表下一页
sinceid = ""
if "cardlistInfo" in data and "since_id" in data["cardlistInfo"]:
sinceid = str(data["cardlistInfo"]["since_id"])
if "" == sinceid:
break
# 适当延时,防止被微博封IP
sleep(0.05)
print(f"user {userid} done!")4. 其他
(1)每条微博以及每个图片之间,适当延时,以防被封IP。
(2)本接口只能爬取移动端网页可见微博,被用户隐藏的微博爬取不到。此外,由于移动端网页、weibo.com网页以及app端的差异,本接口获取数据不能确保是用户的所有微博,仅供参考。


















 1535
1535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











