







 Xception模型基于Inception的深度可分离卷积思想,通过完全解耦通道关系映射和空间关系映射,提高了性能。在ImageNet和JFT数据集上的实验表明,Xception在参数量与Inception v3相同的情况下,表现更优,且得益于残差连接,模型训练更为高效。
Xception模型基于Inception的深度可分离卷积思想,通过完全解耦通道关系映射和空间关系映射,提高了性能。在ImageNet和JFT数据集上的实验表明,Xception在参数量与Inception v3相同的情况下,表现更优,且得益于残差连接,模型训练更为高效。
Xception: Deep Learning with Depthwise Separable Convolutions
摘要
Inception 介于 正常卷积、depthwise separable 卷积 之间。在这种认知下,一个 depthwise separable 卷积可以被理解为 包含最大数量 tower (tower 指的是 Inception 模块内的各个 path)的 Inception 模块。由此,作者提出了 Xception(灵感来自于 Inception)。在ImageNet 上,Xception 比 Inception v3 性能高一点,但在更大的数据集上,Xception 性能明显优于 Inception v3。因为 Xception 架构与 Inception v3 的参数量相同,因此性能的提高不是由于模型容量的增加,而是由于模型参数更高效的利用。
depthwise separable convolution:等价于一个 depthwise 卷积 + 一个 pointwise 卷积
1. 简介
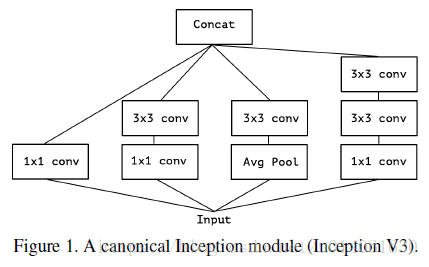
Inception 模块有很多不同的版本,图 1 展示了 Inception v3 中的标准 Inception 模块。Inception 模型就是用这些 Inception 模块堆叠而成的。这与早前 VGG 堆叠简单的卷积层不同。
在概念上,Inception 模块和卷积层是相似的(都是卷积特征提取器),经验上来说,他们都是用少量参数学习丰富的表达。它们是怎样工作的,和正常的卷积层有什么区别呢?Inception 背后的设计理念是什么呢?
1.1. Inception 的假设
卷积层尝试在一个 3 维空间(宽度和高度这两个维度、通道这个维度)学习一些 filter。因此一个卷积核同时负责 通道关系映射 和 空间关系映射。
Inception 模块的背后想法是:通过将 通道关系映射 和 空间关系映射 分开,从而使得这个过程更简单、高效。具体来说,标准的 Inception 模块首先通过 1x1 卷积来处理 通道关系映射,将输入映射到 3 或 4 个小于输入空间的独立空间上;然后通过正常的 3x3 或 5x5 卷积处理这些独立空间之间的关系。实际上,Inception 背后的基础假设是:将 通道间关系 和 空间关系 完全解耦。
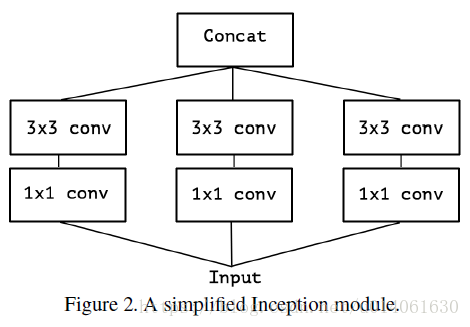
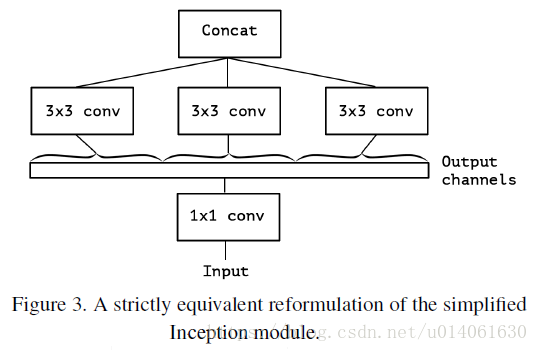
考虑图 2 这样一个简单的 Inception 模块。该模块可以被看作图 3 这样的一个结构:一个大的 1x1 卷积 跟 一些空间卷积。这个认知带来一些问题:分段的数量的影响?做出比 Inception 更强的假设是合理的吗?通道关系映射 和 空间关系映射 是否真的可以完全分开?
在 Inception v3 中,作者还用 7x1 和 1x7 的卷积来替代 7x7 的卷积,从而将高度方向和宽度方向解耦。这样的空间分离卷积在图像处理中有很悠久的历史,已经在2012年后(或许更早)的一些卷积网络中有使用
1.2. 正常卷积 与 separable convolution 间的连续性
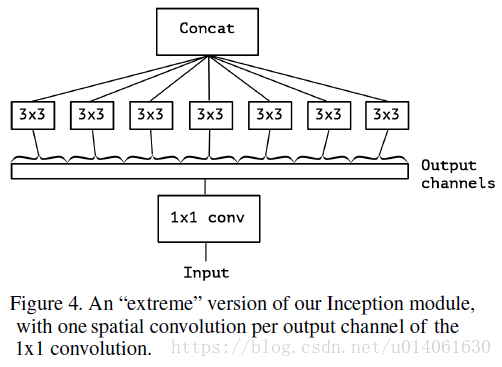
Inception 模块的 tower 的数量十分多时,我们就可以首先使用一个 1x1 卷积去处理通道关系映射,然后处理各个输出通道的空间关系(如图 4)。所以作者认为 tower 非常非常多时, Inception 模块和 depthwise separable 卷积趋向于一致。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









