







AlexNet模型解读

AlexNet共有八层,有60M以上的参数量。
前五层为卷积层:convolutional layer;
后三层为全连接层,fully connected layer。
最后一个全连接层输出具有1000个输出的softmax。(这个不懂什么意思的参考机器学习理论中的softmax regression,就是一个多类的logistic regression)
大致的分层结构如下:
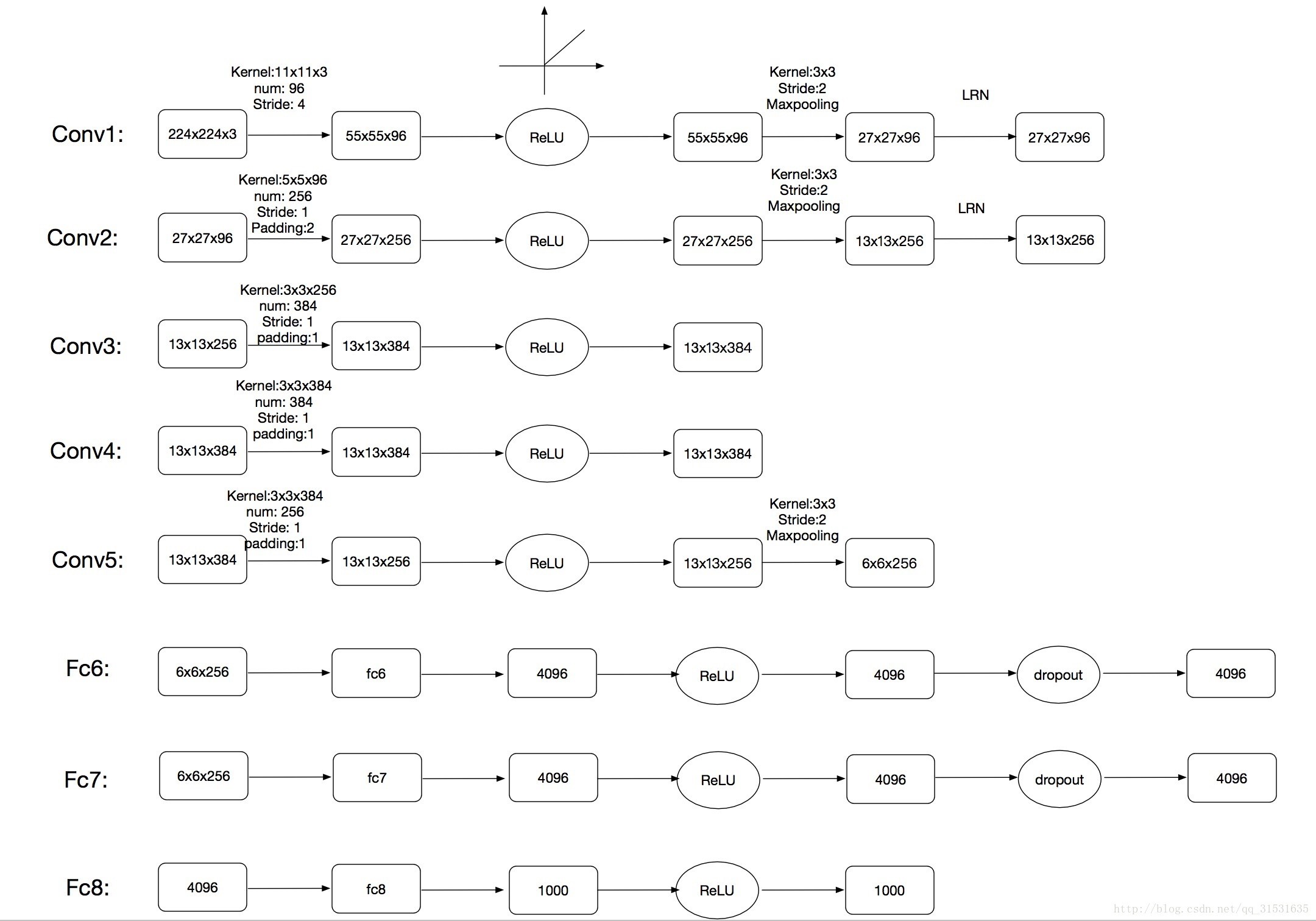

●第一层:
①输入图片为224x 224 x3, 表示长宽是224个像素,RGB彩色图通道为3通道,所以还要乘以3.(学界普遍认为论文中说的224不太合适,讲道理应该是227的大小才对,这也成为一个悬案),
②然后采用了96个11 x 11 x 3 的filter。在stride为4的设置下,对输入图像进行了卷积操作。所以经过这一卷积后的操作,输出就变成了55 x 55 x96 的data map。这三个数字的由来:(227-11)/ 4 + 1 = 55,96就是滤波器的个数。
③然后经过激活函数ReLu,再进行池化操作-pooling:滤波器的大小为3 x 3,步长stride为2. 所以池化后的输出为27x 27 x 96,(55-3)/ 2 + 1 =27. 96仍为原来的深度。
④LRN,局部响应归一化。后来大家都认为这个操作没有什么太大的作用,所以后面的网络几乎都没有这个操作,我也就不提了。
●其他第2、3、4、5层的计算过程类似。
●第六层:本层的输入为6 x 6 x 256,全连接层其实就是一个矩阵运算,它完成一个空间上的映射。所以把输入看成一个列向量X,维度为9216(6
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









