






一、对照
俗称对比,单独看一个数据是不会有感觉的,必需跟另一个数据做对比才会有感觉。比如下面的图a和图b。
图a毫无感觉
图b经过跟昨天的成交量对比,就会发现,今天跟昨天实则差了一大截。
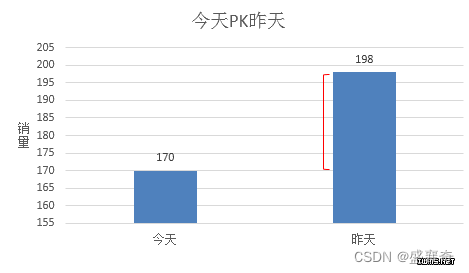
这是最基本的思路,也是最重要的思路。在现实中的应用非常广,比如选产品丶监控增量等,这些过程就是在做【对照】,决策BOSS们拿到数据后,如果数据是独立的,无法进行对比的话,就无法判断,等于无法从数据中读取有用的信息。
二、拆分
分析这个词从字面上来理解,就是拆分和解析,拆分不等于分析,分析包含拆分,拆分能帮助我们找出原因(这简直是终极意义)。
回到第一个思维“对比”上面来,当某个维度可以对比的时候,我们选择对比。再对比后发现问题需要找出原因的时候?或者根本就没有得对比。这个时候,拆分了。
例如:
运营组XX童鞋,经过对比成交数据,发现今天的销售额只有昨天的50%,这个时候,我们再怎么对比销售额这个维度,已经没有意义了。这时需要对销售额这个维度做分解,拆分指标。
销售额=成交用户数*客单价,成交用户数又等于访客数*转化率。
如图c和图d:
图c是一个指标公式的拆解
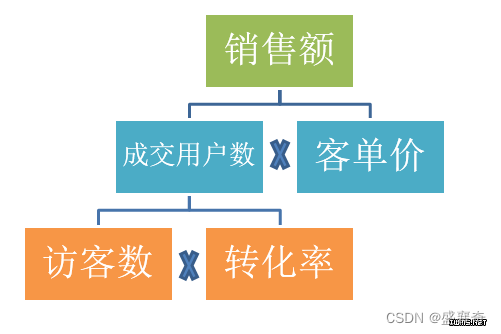
图b是对流量的组成成分做的简单分解(还可以分很细很全)
 分拆后的结果,相对于拆分前会清晰许多,便于分析,找细节。可见,拆分是分析人员必备的思维之一。
分拆后的结果,相对于拆分前会清晰许多,便于分析,找细节。可见,拆分是分析人员必备的思维之一。
三、降维
当面对一大堆维度的数据却促手无策时,当数据维度太多的时候,我们不可能每个维度都拿来分析,有一些有关联的指标,是可以从中筛选出代表的维度即可。如下表:

这么多的维度,不必每个都分析。我们知道成交用户数/意向客户数=转化率,当存在这种维度,是可以通过其他两个维度通过计算转化出来的时候,我们就可以降维
成交用户数、访客数和转化率,只要三选二即可。另外,成交用户数*客单价=销售额,这三个也可以三择二。
我们一般只关心对我们有用的数据,当有某些维度的数据跟我们的分析无关时,我们就可以筛选掉,达到降维的目的。
四、增维
增维和降维是对应的,有降必有增。当我们当前的维度不能很好地解释我们的问题时,我们就需要对数据做一个运算,增加多一个指标。请看下图。
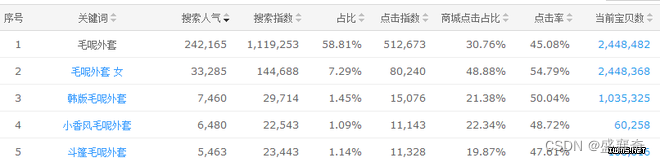 们发现一个搜索指数和一个类目数,这两个指标一个代表需求,一个代表竞争,有很多人把搜索指数/类目数=倍数,用倍数来代表一个词的竞争度。这种做法,就是在增维。增加的维度有一种叫法称之为辅助列。
们发现一个搜索指数和一个类目数,这两个指标一个代表需求,一个代表竞争,有很多人把搜索指数/类目数=倍数,用倍数来代表一个词的竞争度。这种做法,就是在增维。增加的维度有一种叫法称之为辅助列。
增维和降维是必需对数据的意义有充分的了解后,为了方便我们进行分析,有目的的对数据进行转换运算。
五、假说
当我们拿不准未来的时候,或者说是迷茫的时候。我们可以应用假说,假说是统计学的专业名词吧,俗称假设。当我们不知道结果,或者有几种选择的时候,那么我们就召唤假说,我们先假设有了结果,然后运用逆向思维。
从结果到原因,要有怎么样的因,才能产生这种结果。这有点寻根的味道。(好比你分析和女朋友的最终的目的)那么,我们可以知道,现在满足了多少因,还需要多少因。如果是多选的情况下,我们就可以通过这种方法来找到最佳路径决策(应对方法)
当然,假说的威力不仅仅如此。假说可是一匹天马(行空),除了结果可以假设,过程也是可以被假设的。
我们回到数据分析的目的,我们就会知道只有明确了问题和需求,我们才能选择分析的方法。
三大数据类型:这个属于偷换概念,其实就是时间序列的细分,不是真正意义上的数据类型,但这个却是在处理销售数据时经常会碰到的事情。数据放在坐标轴上面分过去丶现在和未来
第一大数据类型 过去
过去的数据指历史数据,已经发生过的数据。
作用:用于总结丶对照和提炼知识
如:历史店铺运营数据,退款数据,订单数据
第二大数据类型 现在
【现在】的概念比较模糊,当天,当月,今年这些都可以是现在的数据,看我们的时间单位而定。如果我们是以天作为单位,那么,今天的数据,就是现在的数据。现在的数据和过去的数据做比较,才可以知道现在自己是在哪个位置,单有现在的数据,是没什么用处的。
作用:用于了解现况,发现问题
如:当天的店铺数据
第三大数据类型 未来
未来 的数据指未发生的数据,通过预测得到。比如我们做得规划,预算等,这些就是在时间点上还没有到,但是却已经有了数据。这个数据是作为参考的数据,预测没有100%,总是有点儿出入的。
作用:用于预测
如:店铺规划,销售计划
三种数据是单向流动的,未来终究会变成现在,直到变成过去。
例如:把数据往坐标轴上面放,按时间段一划分,每个数据的作用就非常清晰。















 5002
5002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









