







一、完整代码
import tensorflow as tf
import tensorlayer as tl
import numpy as np
import pandas as pd
from statsmodels.tsa.tsatools import lagmat
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
sess = tf.InteractiveSession()
# 读取数据、划分数据集
df = pd.read_csv('monthly-flows-chang-jiang-at-han.csv', engine='python',
skipfooter=3, names=['YearMonth', 'WaterFlow'],
parse_dates=[0], infer_datetime_format=True, header=0)
df.YearMonth = pd.to_datetime(df.YearMonth)
df.set_index("YearMonth", inplace=True)
train = df.WaterFlow[:-24]
test = df.WaterFlow[-24:]
# 构造数据
def create_dataset(dataset, timestep=1, look_back=1, look_ahead=1):
dataX = lagmat(dataset, maxlag=look_back, trim='both', original='ex')
dataY = lagmat(dataset[look_back:], maxlag=look_ahead, trim='backward', original='ex')
dataX = dataX.reshape(-1, timestep, dataX.shape[1])[: -(look_ahead - 1)]
return np.array(dataX), np.array(dataY[: -(look_ahead - 1)])
look_back = 60
look_ahead = 24
scaler = MinMaxScaler(feature_range=(0, 1))
trainstd = scaler.fit_transform(train.values.astype(float).reshape(-1, 1))
trainX, trainY = create_dataset(trainstd, timestep=1, look_back=look_back, look_ahead=look_ahead)
test_data = scaler.transform(df.WaterFlow['1972':'1976'].values.reshape(-1, 1)).copy()
testX = (test_data).reshape(1, 1, look_back)
# 定义placeholder
x = tf.placeholder(tf.float32, shape=[None, 1, look_back], name='x')
y_ = tf.placeholder(tf.float32, shape = [None, look_ahead], name='y_')
# 建立模型
network = tl.layers.InputLayer(inputs=x, name='input_layer')
network = tl.layers.RNNLayer(network, cell_fn=tf.nn.rnn_cell.LSTMCell, cell_init_args={},
n_hidden=48, initializer=tf.random_uniform_initializer(0, 0.05), n_steps=1,
return_last=False, return_seq_2d=True, name='lstm_layer')
network = tl.layers.DenseLayer(network, n_units=look_ahead, act=tf.identity, name='output_layer')
# 定义损失函数
y = network.outputs
cost = tl.cost.mean_squared_error(y, y_, is_mean=True)
# 定义优化器
train_param = network.all_params
train_op = tf.train.AdamOptimizer(learning_rate=0.0001, use_locking=False).minimize(cost, var_list=train_param)
# 初始化参数
tl.layers.initialize_global_variables(sess)
# 列出模型信息
network.print_layers()
network.print_params()
# 训练模型
tl.utils.fit(sess, network, train_op, cost, trainX, trainY, x, y_,
batch_size=11, n_epoch=50, print_freq=10,
eval_train=False, tensorboard=True)
# 预测
prediction = tl.utils.predict(sess, network, testX, x, y)
prediction = scaler.inverse_transform(prediction.reshape(-1, 1))
# 绘制结果
actual = df.WaterFlow['1977':'1978'].copy().reshape(-1, 1)
plt.plot(prediction, label='prediction')
plt.plot(actual, label='actual')
plt.legend(loc='best')
plt.show()
# 保存模型
tl.files.save_npz(network.all_params, name='model.npz')
sess.close()二、略有复杂
【数据集说明】
此例是时间序列预测问题,用到的数据集是在汉口测量的长江每月流量数据,该数据记录了从1865年1月到1978年12月早汉口记录的长江每月的流量,共计1368个数据点,计量单位未知。
数据点这里下载
1、第一步,读取数据
↓读取csv文件。engine=‘python’表示使用python作为分析引擎,另一个选择使C。skipfooter=3表示忽略最后三行,原数据的后三行是无用信息。names=['YearMonth', 'WaterFlow'],给数据的列重新命名。header=0,指定第0行作为列名。
df = pd.read_csv('monthly-flows-chang-jiang-at-han.csv', engine='python', skipfooter=3, names=['YearMonth', 'WaterFlow'], header=0)↓将str格式的YearMonth列转为时间格式
df.YearMonth = pd.to_datetime(df.YearMonth)
↓将YearMonth列作为索引
df.set_index("YearMonth", inplace=True)
↓将倒数第24个月之前的数据作为训练集,预测最后24个月的流量
train = df.WaterFlow[:-24] test = df.WaterFlow[-24:]
2、第二步,构造数据集
循环神经网络要求输入数据的格式为[样本数,时间步长,特征数]
↓定义一个函数来构造这类格式的数据。
def create_dataset(dataset, timestep=1, look_back=1, look_ahead=1): dataX = lagmat(dataset, maxlag=look_back, trim='both', original='ex') dataY = lagmat(dataset[look_back:], maxlag=look_ahead, trim='backward', original='ex') dataX = dataX.reshape(-1, timestep, dataX.shape[1])[: -(look_ahead - 1)] return np.array(dataX), np.array(dataY[: -(look_ahead - 1)])
输入参数:dataset,要构造的数据。timestep,时间步长。look_back,往后几个月。look_ahead,往前几个月。这里我们用look_ahead个月作为特征个数,timestep设为1,预测后look_back个月的流量。
lagmat是扩展包statsmodels的一个方法,用来生成上面格式的数据,statsmodels是统计建模的扩展包。
↓设置前60个月作为特征,预测未来的24个月look_back = 60 look_ahead = 24↓将数据缩放到0-1之间,构造训练集、测试集
scaler = MinMaxScaler(feature_range=(0, 1)) trainstd = scaler.fit_transform(train.values.astype(float).reshape(-1, 1)) trainX, trainY = create_dataset(trainstd, timestep=1, look_back=look_back, look_ahead=look_ahead) test_data = scaler.transform(df.WaterFlow['1972':'1976'].values.reshape(-1, 1)).copy() testX = (test_data).reshape(1, 1, look_back)
3、第三步,定义placeholder
x = tf.placeholder(tf.float32, shape=[None, 1, look_back], name='x') y_ = tf.placeholder(tf.float32, shape = [None, look_ahead], name='y_')
4、第四步,搭建模型
↓输入层
network = tl.layers.InputLayer(inputs=x, name='input_layer')↓LSTM层
network = tl.layers.RNNLayer(network, cell_fn=tf.nn.rnn_cell.LSTMCell n_hidden=48, initializer=tf.random_uniform_initializer(0, 0.05), n_steps=1, return_last=False, return_seq_2d=True, name='lstm_layer')cell_fn=tf.nn.rnn_cell.LSTMCell表示使用LSTM作为循环神经网络的内核。隐藏单元为48个。参数采用均值为0方差为0.05的正态分布初始化。序列长度为1。return_last=False表示返回所有的输出。return_seq_2d=True表示返回2维向量[样本数,隐藏单元数],主要目的是在这之后加Dense层。
↓Dense层
network = tl.layers.DenseLayer(network, n_units=look_ahead, act=tf.identity, name='output_layer')
5、第五步,定义损失函数
y = network.outputs cost = tl.cost.mean_squared_error(y, y_, is_mean=True)这里采用均方误差
6、第六步,定义优化器
train_param = network.all_params train_op = tf.train.AdamOptimizer(learning_rate=0.0001, use_locking=False).minimize(cost, var_list=train_param)
7、第七步,初始化参数,训练模型
# 初始化参数 tl.layers.initialize_global_variables(sess) # 列出模型信息 network.print_layers() network.print_params() # 训练模型 tl.utils.fit(sess, network, train_op, cost, trainX, trainY, x, y_, batch_size=11, n_epoch=50, print_freq=10, eval_train=False, tensorboard=True)
8、第八步,预测并绘制结果
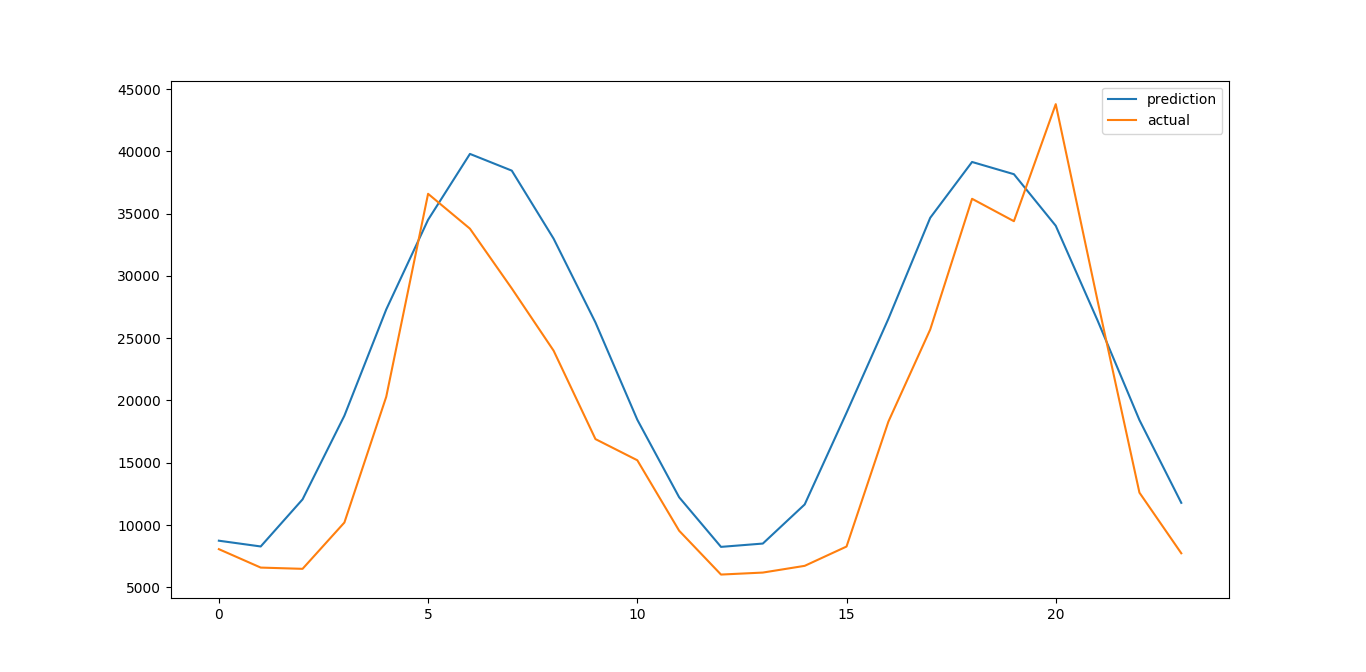
# 预测 prediction = tl.utils.predict(sess, network, testX, x, y) prediction = scaler.inverse_transform(prediction.reshape(-1, 1)) # 绘制结果 actual = df.WaterFlow['1977':'1978'].copy().reshape(-1, 1) plt.plot(prediction, label='prediction') plt.plot(actual, label='actual') plt.legend(loc='best') plt.show()注意直接预测出来的结果要重新缩放回去。
三、run起来
运行,输出以下信息:
[TL] InputLayer input_layer: (?, 1, 60)
[TL] RNNLayer lstm_layer: n_hidden:48 n_steps:1 in_dim:3 in_shape:(?, 1, 60) cell_fn:LSTMCell
non specified batch_size, uses a tensor instead.
n_params : 2
[TL] DenseLayer output_layer: 24 identity
layer 0: Reshape:0 (?, 48) float32
layer 1: output_layer/Identity:0 (?, 24) float32
param 0: lstm_layer/lstm_cell/kernel:0 (108, 192) float32_ref (mean: 0.025015197694301605, median: 0.025069095194339752, std: 0.014439292252063751)
param 1: lstm_layer/lstm_cell/bias:0 (192,) float32_ref (mean: 0.0 , median: 0.0 , std: 0.0 )
param 2: output_layer/W:0 (48, 24) float32_ref (mean: 0.0002973793598357588, median: 0.001085719559341669, std: 0.08804222196340561)
param 3: output_layer/b:0 (24,) float32_ref (mean: 0.0 , median: 0.0 , std: 0.0 )
num of params: 22104
Setting up tensorboard ...
[!] logs/ exists ...
Param name lstm_layer/lstm_cell/kernel:0
Param name lstm_layer/lstm_cell/bias:0
Param name output_layer/W:0
Param name output_layer/b:0
Finished! use $tensorboard --logdir=logs/ to start server
Start training the network ...
Epoch 1 of 50 took 0.813046s, loss 0.110952
Epoch 10 of 50 took 0.965055s, loss 0.009513
Epoch 20 of 50 took 0.841048s, loss 0.008852
Epoch 30 of 50 took 0.834048s, loss 0.008663
Epoch 40 of 50 took 0.891051s, loss 0.008521
Epoch 50 of 50 took 1.042059s, loss 0.008367
Total training time: 14.029802s
E:/Machine_Learning/TensorLayer_code/lstm/lstm.py:70: FutureWarning: reshape is deprecated and will raise in a subsequent release. Please use .values.reshape(...) instead
actual = df.WaterFlow['1977':'1978'].copy().reshape(-1, 1)
[*] model.npz saved预测结果:















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









